 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLive Multi-Streaming and Donation Recommendations via Coupled Donation-Response Tensor Factorization
Oct 05, 2021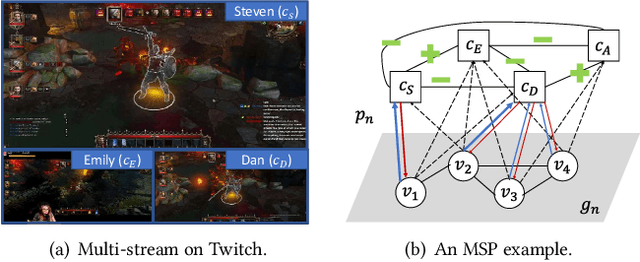
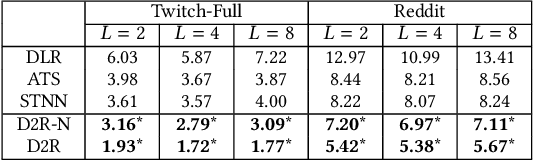
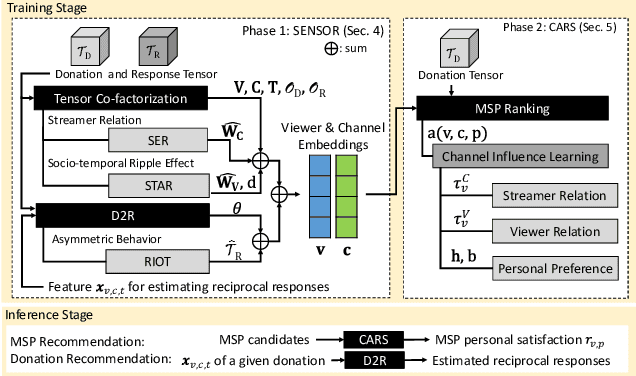

In contrast to traditional online videos, live multi-streaming supports real-time social interactions between multiple streamers and viewers, such as donations. However, donation and multi-streaming channel recommendations are challenging due to complicated streamer and viewer relations, asymmetric communications, and the tradeoff between personal interests and group interactions. In this paper, we introduce Multi-Stream Party (MSP) and formulate a new multi-streaming recommendation problem, called Donation and MSP Recommendation (DAMRec). We propose Multi-stream Party Recommender System (MARS) to extract latent features via socio-temporal coupled donation-response tensor factorization for donation and MSP recommendations. Experimental results on Twitch and Douyu manifest that MARS significantly outperforms existing recommenders by at least 38.8% in terms of hit ratio and mean average precision.
DeepIST: Deep Image-based Spatio-Temporal Network for Travel Time Estimation
Sep 05, 2019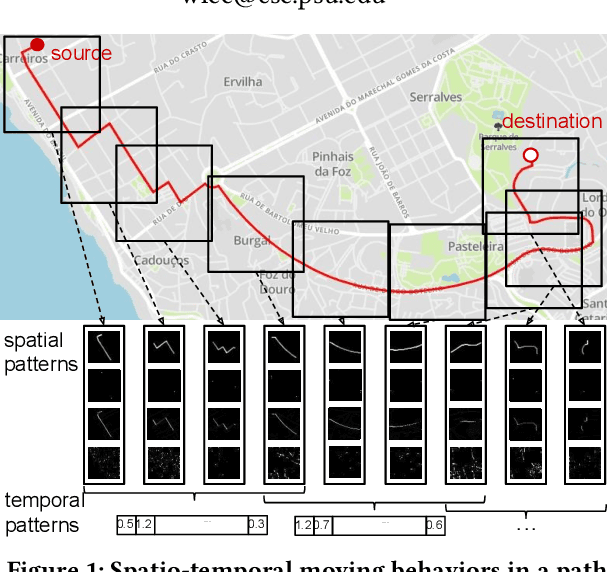
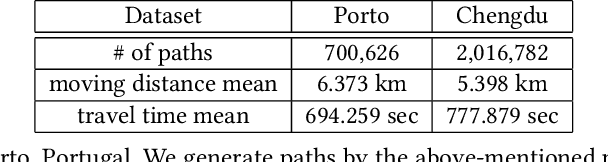
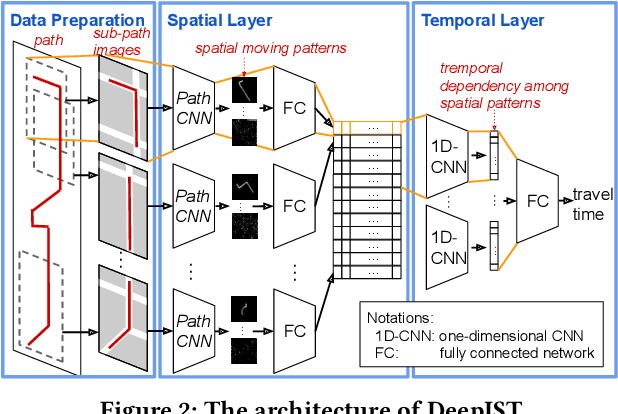
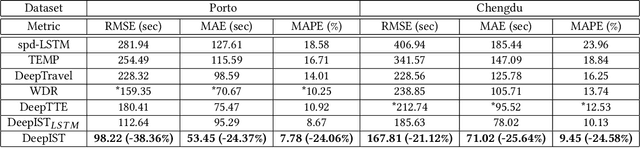
Estimating the travel time for a given path is a fundamental problem in many urban transportation systems. However, prior works fail to well capture moving behaviors embedded in paths and thus do not estimate the travel time accurately. To fill in this gap, in this work, we propose a novel neural network framework, namely {\em Deep Image-based Spatio-Temporal network (DeepIST)}, for travel time estimation of a given path. The novelty of DeepIST lies in the following aspects: 1) we propose to plot a path as a sequence of "generalized images" which include sub-paths along with additional information, such as traffic conditions, road network and traffic signals, in order to harness the power of convolutional neural network model (CNN) on image processing; 2) we design a novel two-dimensional CNN, namely {\em PathCNN}, to extract spatial patterns for lines in images by regularization and adopting multiple pooling methods; and 3) we apply a one-dimensional CNN to capture temporal patterns among the spatial patterns along the paths for the estimation. Empirical results show that DeepIST soundly outperforms the state-of-the-art travel time estimation models by 24.37\% to 25.64\% of mean absolute error (MAE) in multiple large-scale real-world datasets.
* 10 pages, accepted by The 28th ACM International Conference on Information and Knowledge Management (CIKM) 2019
Scene Graph Generation via Conditional Random Fields
Nov 20, 2018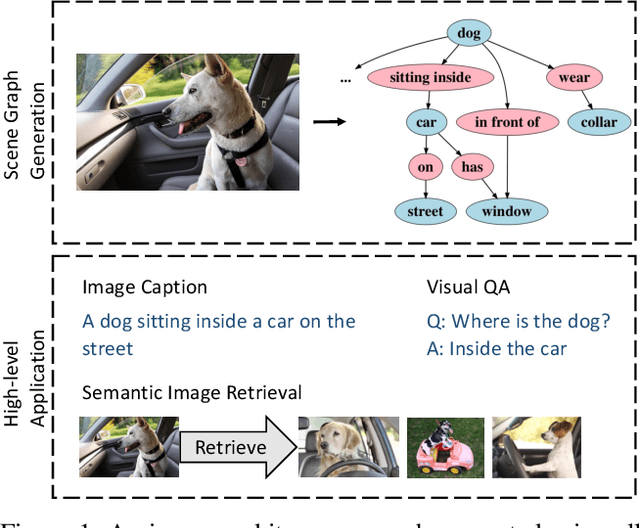
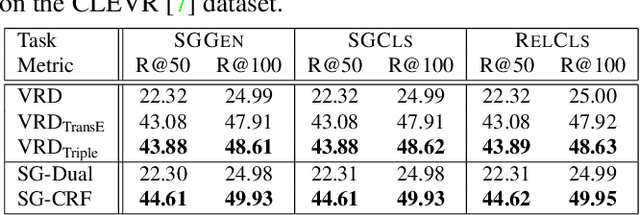
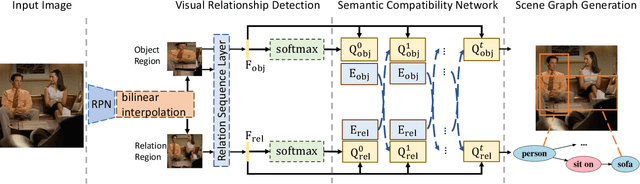
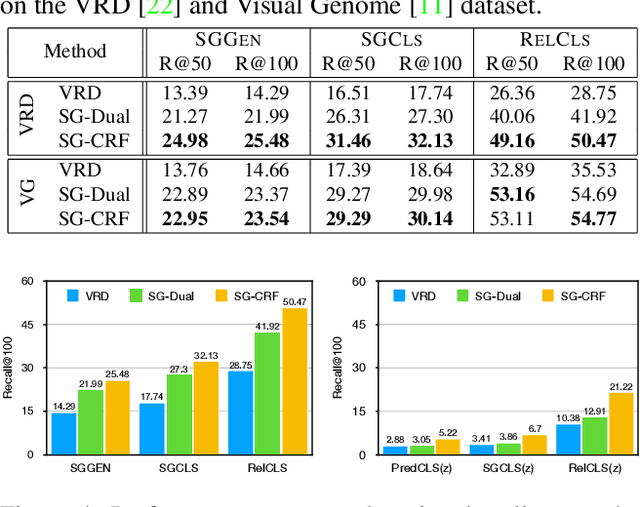
Despite the great success object detection and segmentation models have achieved in recognizing individual objects in images, performance on cognitive tasks such as image caption, semantic image retrieval, and visual QA is far from satisfactory. To achieve better performance on these cognitive tasks, merely recognizing individual object instances is insufficient. Instead, the interactions between object instances need to be captured in order to facilitate reasoning and understanding of the visual scenes in an image. Scene graph, a graph representation of images that captures object instances and their relationships, offers a comprehensive understanding of an image. However, existing techniques on scene graph generation fail to distinguish subjects and objects in the visual scenes of images and thus do not perform well with real-world datasets where exist ambiguous object instances. In this work, we propose a novel scene graph generation model for predicting object instances and its corresponding relationships in an image. Our model, SG-CRF, learns the sequential order of subject and object in a relationship triplet, and the semantic compatibility of object instance nodes and relationship nodes in a scene graph efficiently. Experiments empirically show that SG-CRF outperforms the state-of-the-art methods, on three different datasets, i.e., CLEVR, VRD, and Visual Genome, raising the Recall@100 from 24.99% to 49.95%, from 41.92% to 50.47%, and from 54.69% to 54.77%, respectively.