 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Multi-Domain and Long-Tailed Quantization via Feature Alignment and Scaling
Jun 03, 2026Quantizing deep neural networks is essential for efficient inference on resource-constrained devices. However, most existing methods are designed for single-domain and class-balanced data, leaving practical settings with domain shifts or severe class imbalance underexplored. We address these challenges with Efficient Multi-Domain Alignment Quantization (EmaQ), which aligns domain distributions through a CDF-based projection and uses sensitivity-aware weight aggregation to stabilize multi-domain quantization. We further extend EmaQ to EmaQ-LT for long-tailed quantization by introducing class-conditioned variance scaling and confidence-based logit adjustment to mitigate majority-class overconfidence. Theoretical analyses establish convergence guarantees and motivate the proposed sensitivity and scaling mechanisms. Experiments on standard, multi-domain (Office-31, Digits), and long-tailed (SynDigits-LT, CIFAR-10-LT, CIFAR-100-LT) benchmarks show that EmaQ and EmaQ-LT achieve strong low-bit performance under domain shift and class imbalance.
Self-guided Knowledgeable Network of Thoughts: Amplifying Reasoning with Large Language Models
Dec 21, 2024We introduce Knowledgeable Network of Thoughts (kNoT): a prompt scheme that advances the capabilities of large language models (LLMs) beyond existing paradigms like Chain-of-Thought (CoT), Tree of Thoughts (ToT), and Graph of Thoughts (GoT). The key innovation of kNoT is the LLM Workflow Template (LWT), which allows for an executable plan to be specified by LLMs for LLMs. LWT allows these plans to be arbitrary networks, where single-step LLM operations are nodes, and edges correspond to message passing between these steps. Furthermore, LWT supports selection of individual elements through indexing, facilitating kNoT to produce intricate plans where each LLM operation can be limited to elementary operations, greatly enhancing reliability over extended task sequences. We demonstrate that kNoT significantly outperforms the state of the art on six use cases, while reducing the need for extensive prompt engineering. For instance, kNoT finds 92% accuracy for sorting 32 numbers over 12% and 31% for ToT and GoT, while utilizing up to 84.4% and 87.3% less task-specific prompts, respectively.
In Anticipation of Perfect Deepfake: Identity-anchored Artifact-agnostic Detection under Rebalanced Deepfake Detection Protocol
May 01, 2024As deep generative models advance, we anticipate deepfakes achieving "perfection"-generating no discernible artifacts or noise. However, current deepfake detectors, intentionally or inadvertently, rely on such artifacts for detection, as they are exclusive to deepfakes and absent in genuine examples. To bridge this gap, we introduce the Rebalanced Deepfake Detection Protocol (RDDP) to stress-test detectors under balanced scenarios where genuine and forged examples bear similar artifacts. We offer two RDDP variants: RDDP-WHITEHAT uses white-hat deepfake algorithms to create 'self-deepfakes,' genuine portrait videos with the resemblance of the underlying identity, yet carry similar artifacts to deepfake videos; RDDP-SURROGATE employs surrogate functions (e.g., Gaussian noise) to process both genuine and forged examples, introducing equivalent noise, thereby sidestepping the need of deepfake algorithms. Towards detecting perfect deepfake videos that aligns with genuine ones, we present ID-Miner, a detector that identifies the puppeteer behind the disguise by focusing on motion over artifacts or appearances. As an identity-based detector, it authenticates videos by comparing them with reference footage. Equipped with the artifact-agnostic loss at frame-level and the identity-anchored loss at video-level, ID-Miner effectively singles out identity signals amidst distracting variations. Extensive experiments comparing ID-Miner with 12 baseline detectors under both conventional and RDDP evaluations with two deepfake datasets, along with additional qualitative studies, affirm the superiority of our method and the necessity for detectors designed to counter perfect deepfakes.
CDGraph: Dual Conditional Social Graph Synthesizing via Diffusion Model
Nov 06, 2023

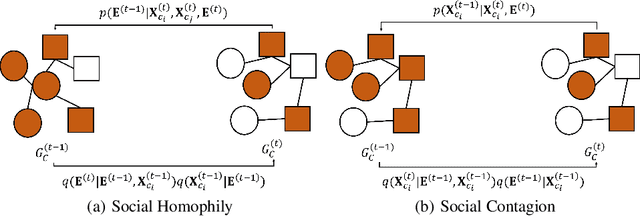

The social graphs synthesized by the generative models are increasingly in demand due to data scarcity and concerns over user privacy. One of the key performance criteria for generating social networks is the fidelity to specified conditionals, such as users with certain membership and financial status. While recent diffusion models have shown remarkable performance in generating images, their effectiveness in synthesizing graphs has not yet been explored in the context of conditional social graphs. In this paper, we propose the first kind of conditional diffusion model for social networks, CDGraph, which trains and synthesizes graphs based on two specified conditions. We propose the co-evolution dependency in the denoising process of CDGraph to capture the mutual dependencies between the dual conditions and further incorporate social homophily and social contagion to preserve the connectivity between nodes while satisfying the specified conditions. Moreover, we introduce a novel classifier loss, which guides the training of the diffusion process through the mutual dependency of dual conditions. We evaluate CDGraph against four existing graph generative methods, i.e., SPECTRE, GSM, EDGE, and DiGress, on four datasets. Our results show that the generated graphs from CDGraph achieve much higher dual-conditional validity and lower discrepancy in various social network metrics than the baselines, thus demonstrating its proficiency in generating dual-conditional social graphs.
Attack as the Best Defense: Nullifying Image-to-image Translation GANs via Limit-aware Adversarial Attack
Oct 06, 2021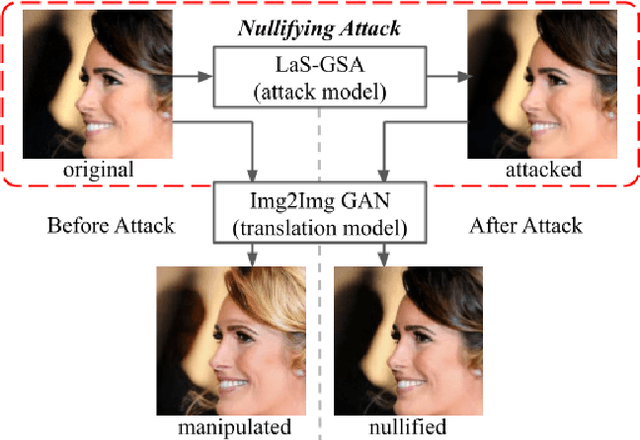
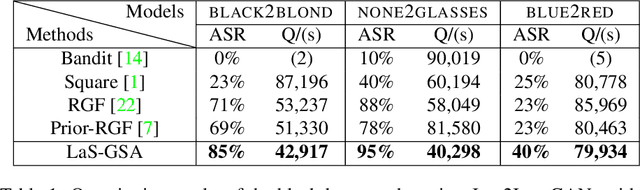
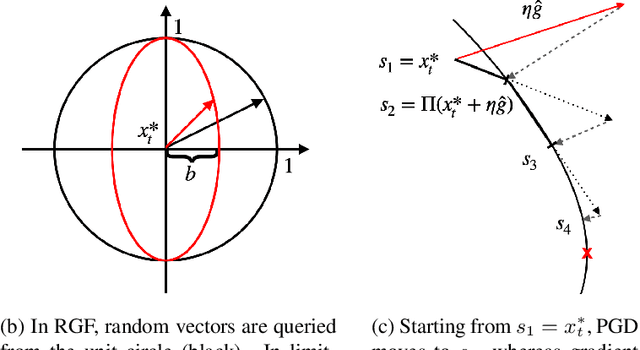

With the successful creation of high-quality image-to-image (Img2Img) translation GANs comes the non-ethical applications of DeepFake and DeepNude. Such misuses of img2img techniques present a challenging problem for society. In this work, we tackle the problem by introducing the Limit-Aware Self-Guiding Gradient Sliding Attack (LaS-GSA). LaS-GSA follows the Nullifying Attack to cancel the img2img translation process under a black-box setting. In other words, by processing input images with the proposed LaS-GSA before publishing, any targeted img2img GANs can be nullified, preventing the model from maliciously manipulating the images. To improve efficiency, we introduce the limit-aware random gradient-free estimation and the gradient sliding mechanism to estimate the gradient that adheres to the adversarial limit, i.e., the pixel value limitations of the adversarial example. Theoretical justifications validate how the above techniques prevent inefficiency caused by the adversarial limit in both the direction and the step length. Furthermore, an effective self-guiding prior is extracted solely from the threat model and the target image to efficiently leverage the prior information and guide the gradient estimation process. Extensive experiments demonstrate that LaS-GSA requires fewer queries to nullify the image translation process with higher success rates than 4 state-of-the-art black-box methods.
Live Multi-Streaming and Donation Recommendations via Coupled Donation-Response Tensor Factorization
Oct 05, 2021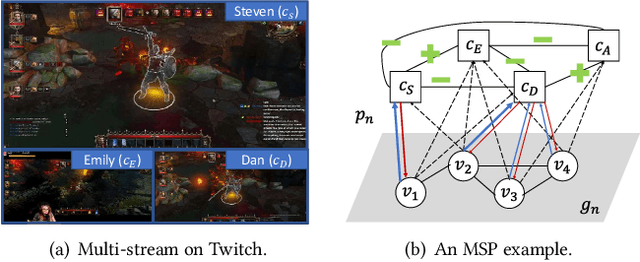
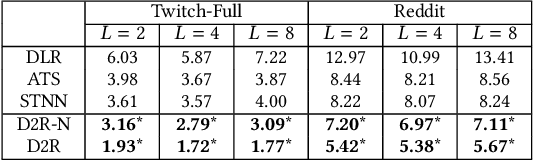
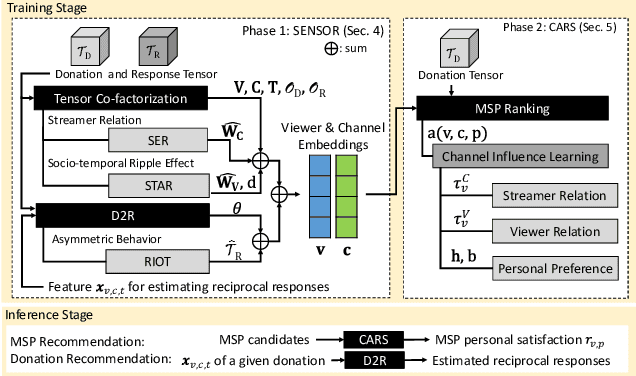

In contrast to traditional online videos, live multi-streaming supports real-time social interactions between multiple streamers and viewers, such as donations. However, donation and multi-streaming channel recommendations are challenging due to complicated streamer and viewer relations, asymmetric communications, and the tradeoff between personal interests and group interactions. In this paper, we introduce Multi-Stream Party (MSP) and formulate a new multi-streaming recommendation problem, called Donation and MSP Recommendation (DAMRec). We propose Multi-stream Party Recommender System (MARS) to extract latent features via socio-temporal coupled donation-response tensor factorization for donation and MSP recommendations. Experimental results on Twitch and Douyu manifest that MARS significantly outperforms existing recommenders by at least 38.8% in terms of hit ratio and mean average precision.