 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Model-Free Kullback-Leibler Divergence Filter for Anomaly Detection in Noisy Data Series
May 05, 2024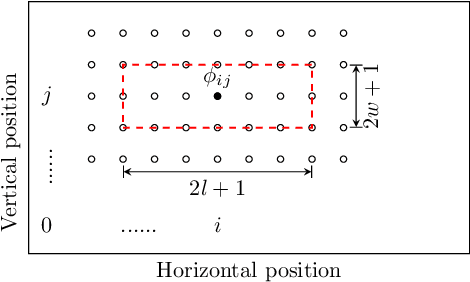
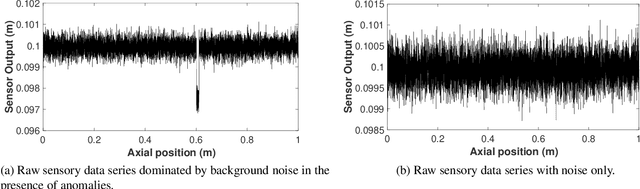
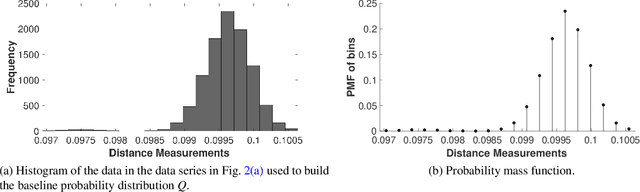
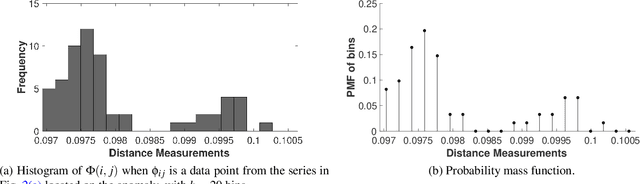
We propose a Kullback-Leibler Divergence (KLD) filter to extract anomalies within data series generated by a broad class of proximity sensors, along with the anomaly locations and their relative sizes. The technique applies to devices commonly used in engineering practice, such as those mounted on mobile robots for non-destructive inspection of hazardous or other environments that may not be directly accessible to humans. The raw data generated by this class of sensors can be challenging to analyze due to the prevalence of noise over the signal content. The proposed filter is built to detect the difference of information content between data series collected by the sensor and baseline data series. It is applicable in a model-based or model-free context. The performance of the KLD filter is validated in an industrial-norm setup and benchmarked against a peer industrially-adopted algorithm.
* 10 pages, 40 references
A Policy Iteration Approach for Flock Motion Control
Mar 17, 2023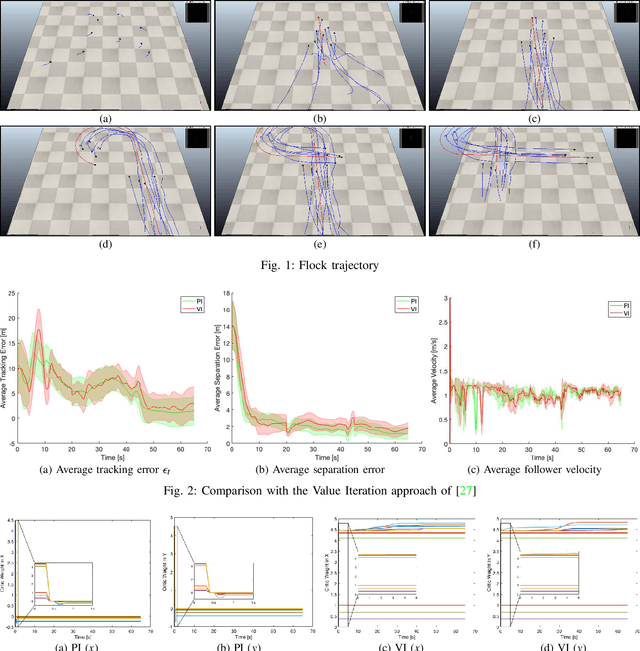
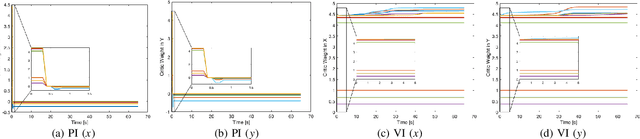
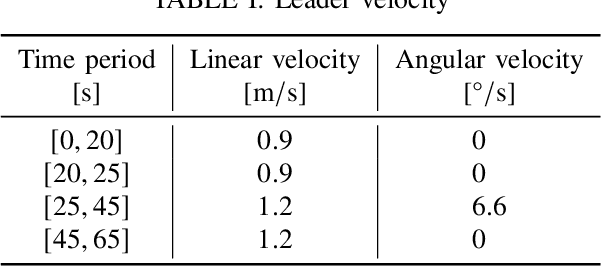
The flocking motion control is concerned with managing the possible conflicts between local and team objectives of multi-agent systems. The overall control process guides the agents while monitoring the flock-cohesiveness and localization. The underlying mechanisms may degrade due to overlooking the unmodeled uncertainties associated with the flock dynamics and formation. On another side, the efficiencies of the various control designs rely on how quickly they can adapt to different dynamic situations in real-time. An online model-free policy iteration mechanism is developed here to guide a flock of agents to follow an independent command generator over a time-varying graph topology. The strength of connectivity between any two agents or the graph edge weight is decided using a position adjacency dependent function. An online recursive least squares approach is adopted to tune the guidance strategies without knowing the dynamics of the agents or those of the command generator. It is compared with another reinforcement learning approach from the literature which is based on a value iteration technique. The simulation results of the policy iteration mechanism revealed fast learning and convergence behaviors with less computational effort.
* 7 pages, 3 figures
An Adaptive Fuzzy Reinforcement Learning Cooperative Approach for the Autonomous Control of Flock Systems
Mar 17, 2023
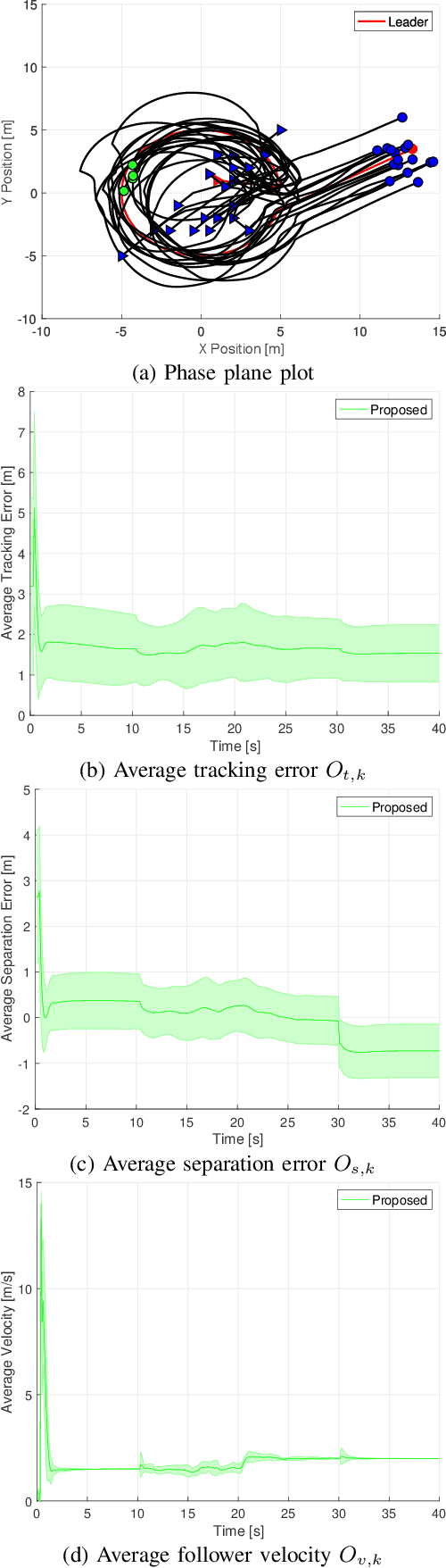
The flock-guidance problem enjoys a challenging structure where multiple optimization objectives are solved simultaneously. This usually necessitates different control approaches to tackle various objectives, such as guidance, collision avoidance, and cohesion. The guidance schemes, in particular, have long suffered from complex tracking-error dynamics. Furthermore, techniques that are based on linear feedback strategies obtained at equilibrium conditions either may not hold or degrade when applied to uncertain dynamic environments. Pre-tuned fuzzy inference architectures lack robustness under such unmodeled conditions. This work introduces an adaptive distributed technique for the autonomous control of flock systems. Its relatively flexible structure is based on online fuzzy reinforcement learning schemes which simultaneously target a number of objectives; namely, following a leader, avoiding collision, and reaching a flock velocity consensus. In addition to its resilience in the face of dynamic disturbances, the algorithm does not require more than the agent position as a feedback signal. The effectiveness of the proposed method is validated with two simulation scenarios and benchmarked against a similar technique from the literature.
* 7 pages, 2 figures
A Data-Driven Model-Reference Adaptive Control Approach Based on Reinforcement Learning
Mar 17, 2023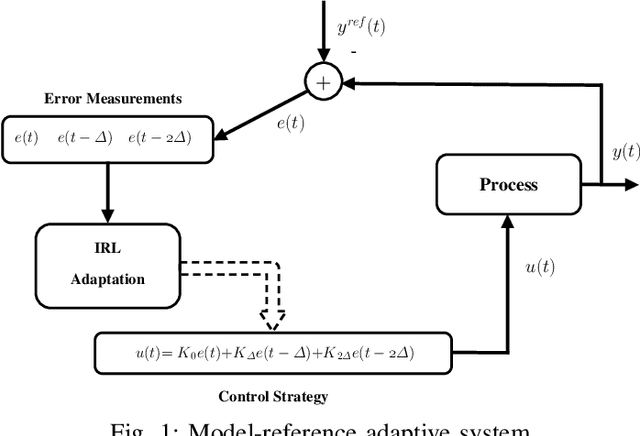
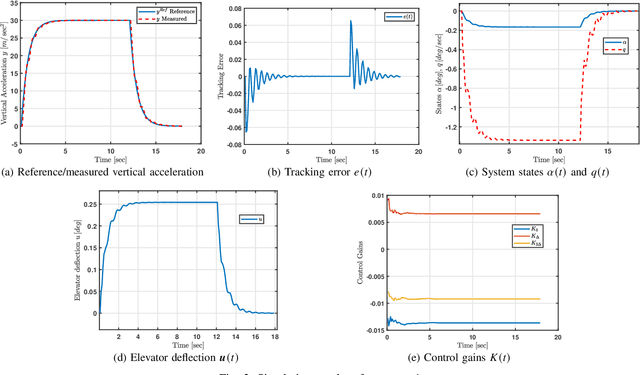
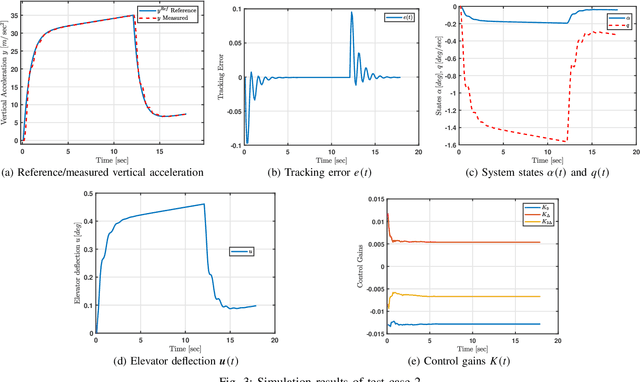
Model-reference adaptive systems refer to a consortium of techniques that guide plants to track desired reference trajectories. Approaches based on theories like Lyapunov, sliding surfaces, and backstepping are typically employed to advise adaptive control strategies. The resulting solutions are often challenged by the complexity of the reference model and those of the derived control strategies. Additionally, the explicit dependence of the control strategies on the process dynamics and reference dynamical models may contribute in degrading their efficiency in the face of uncertain or unknown dynamics. A model-reference adaptive solution is developed here for autonomous systems where it solves the Hamilton-Jacobi-Bellman equation of an error-based structure. The proposed approach describes the process with an integral temporal difference equation and solves it using an integral reinforcement learning mechanism. This is done in real-time without knowing or employing the dynamics of either the process or reference model in the control strategies. A class of aircraft is adopted to validate the proposed technique.
* 10 pages, 3 figures
Real-Time Measurement-Driven Reinforcement Learning Control Approach for Uncertain Nonlinear Systems
Mar 15, 2023

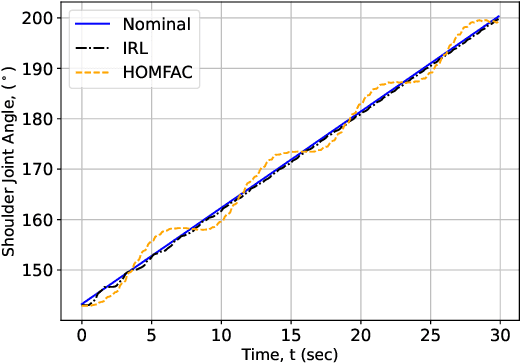
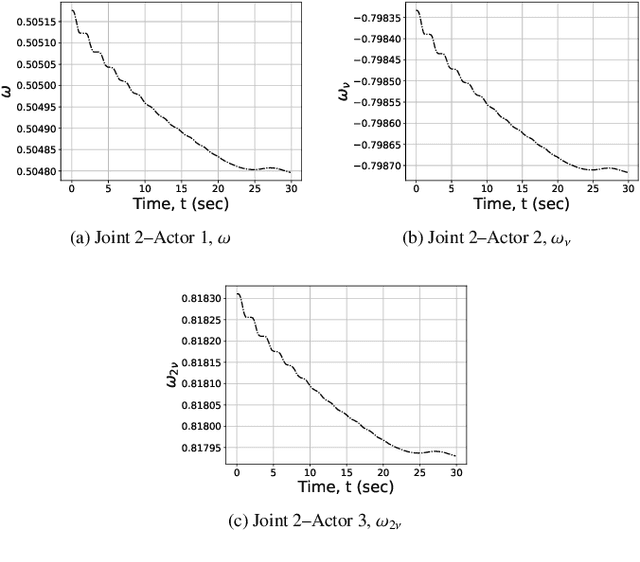
The paper introduces an interactive machine learning mechanism to process the measurements of an uncertain, nonlinear dynamic process and hence advise an actuation strategy in real-time. For concept demonstration, a trajectory-following optimization problem of a Kinova robotic arm is solved using an integral reinforcement learning approach with guaranteed stability for slowly varying dynamics. The solution is implemented using a model-free value iteration process to solve the integral temporal difference equations of the problem. The performance of the proposed technique is benchmarked against that of another model-free high-order approach and is validated for dynamic payload and disturbances. Unlike its benchmark, the proposed adaptive strategy is capable of handling extreme process variations. This is experimentally demonstrated by introducing static and time-varying payloads close to the rated maximum payload capacity of the manipulator arm. The comparison algorithm exhibited up to a seven-fold percent overshoot compared to the proposed integral reinforcement learning solution. The robustness of the algorithm is further validated by disturbing the real-time adapted strategy gains with a white noise of a standard deviation as high as 5%.
* 15 pages
Online Model-Free Reinforcement Learning for the Automatic Control of a Flexible Wing Aircraft
Aug 05, 2021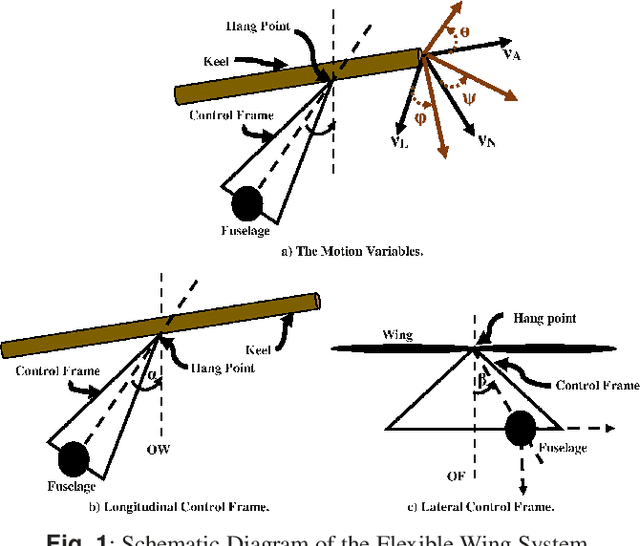

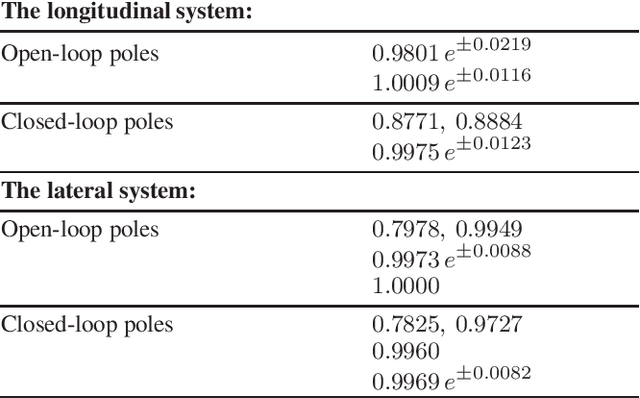
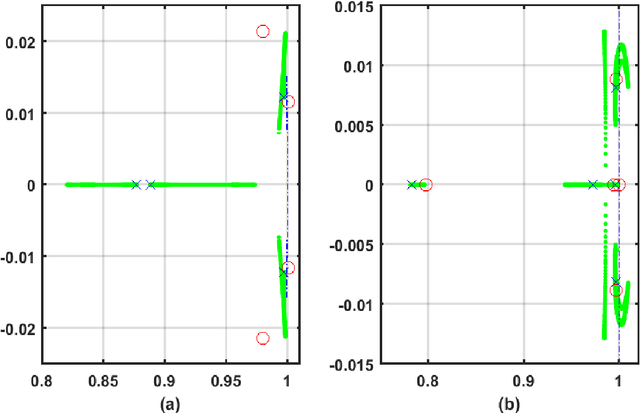
The control problem of the flexible wing aircraft is challenging due to the prevailing and high nonlinear deformations in the flexible wing system. This urged for new control mechanisms that are robust to the real-time variations in the wing's aerodynamics. An online control mechanism based on a value iteration reinforcement learning process is developed for flexible wing aerial structures. It employs a model-free control policy framework and a guaranteed convergent adaptive learning architecture to solve the system's Bellman optimality equation. A Riccati equation is derived and shown to be equivalent to solving the underlying Bellman equation. The online reinforcement learning solution is implemented using means of an adaptive-critic mechanism. The controller is proven to be asymptotically stable in the Lyapunov sense. It is assessed through computer simulations and its superior performance is demonstrated on two scenarios under different operating conditions.
Responding to Illegal Activities Along the Canadian Coastlines Using Reinforcement Learning
Aug 05, 2021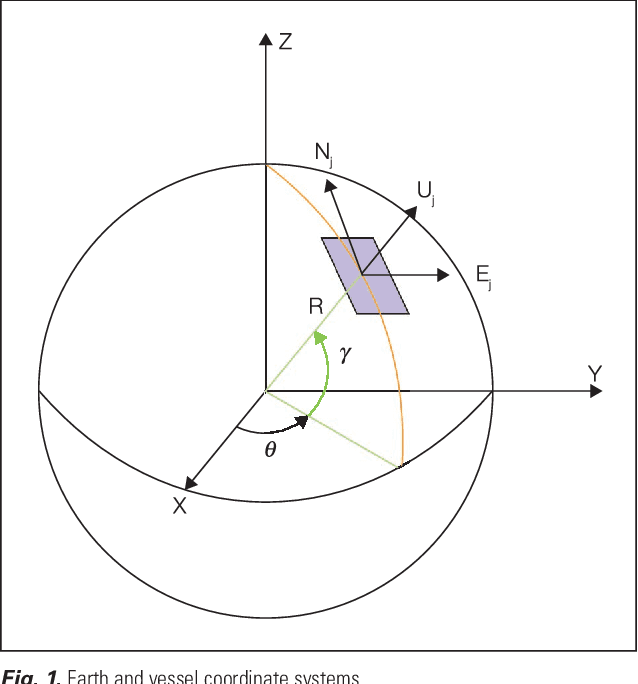

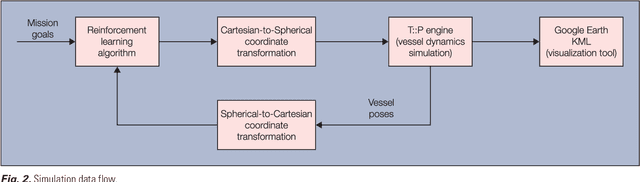
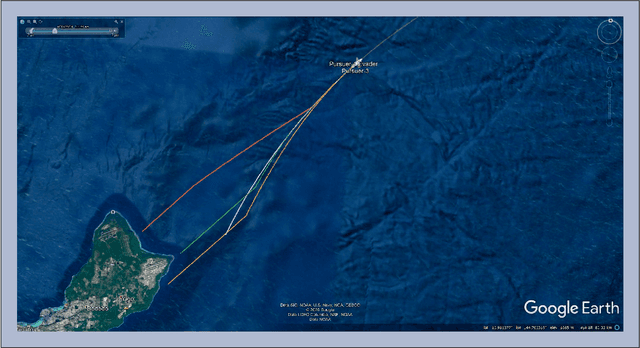
This article elaborates on how machine learning (ML) can leverage the solution of a contemporary problem related to the security of maritime domains. The worldwide ``Illegal, Unreported, and Unregulated'' (IUU) fishing incidents have led to serious environmental and economic consequences which involve drastic changes in our ecosystems in addition to financial losses caused by the depletion of natural resources. The Fisheries and Aquatic Department (FAD) of the United Nation's Food and Agriculture Organization (FAO) issued a report which indicated that the annual losses due to IUU fishing reached $25 Billion. This imposes negative impacts on the future-biodiversity of the marine ecosystem and domestic Gross National Product (GNP). Hence, robust interception mechanisms are increasingly needed for detecting and pursuing the unrelenting illegal fishing incidents in maritime territories. This article addresses the problem of coordinating the motion of a fleet of marine vessels (pursuers) to catch an IUU vessel while still in local waters. The problem is formulated as a pursuer-evader problem that is tackled within an ML framework. One or more pursuers, such as law enforcement vessels, intercept an evader (i.e., the illegal fishing ship) using an online reinforcement learning mechanism that is based on a value iteration process. It employs real-time navigation measurements of the evader ship as well as those of the pursuing vessels and returns back model-free interception strategies.
Data-Driven Optimized Tracking Control Heuristic for MIMO Structures: A Balance System Case Study
Apr 01, 2021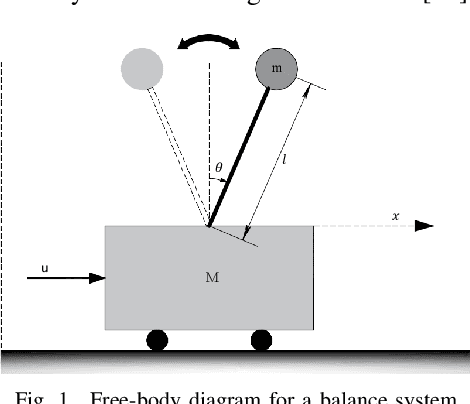
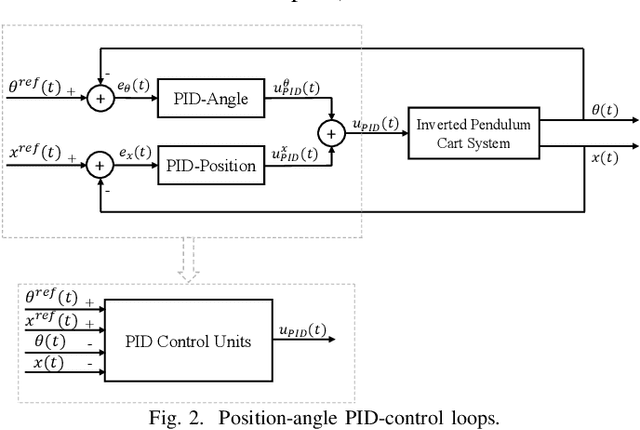
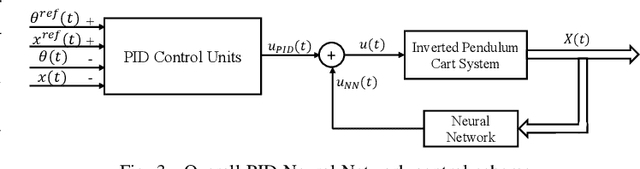
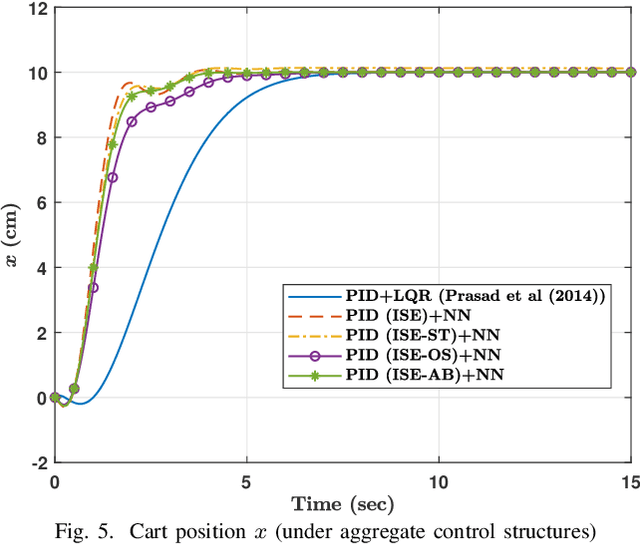
A data-driven computational heuristic is proposed to control MIMO systems without prior knowledge of their dynamics. The heuristic is illustrated on a two-input two-output balance system. It integrates a self-adjusting nonlinear threshold accepting heuristic with a neural network to compromise between the desired transient and steady state characteristics of the system while optimizing a dynamic cost function. The heuristic decides on the control gains of multiple interacting PID control loops. The neural network is trained upon optimizing a weighted-derivative like objective cost function. The performance of the developed mechanism is compared with another controller that employs a combined PID-Riccati approach. One of the salient features of the proposed control schemes is that they do not require prior knowledge of the system dynamics. However, they depend on a known region of stability for the control gains to be used as a search space by the optimization algorithm. The control mechanism is validated using different optimization criteria which address different design requirements.
Trajectory Tracking of Underactuated Sea Vessels With Uncertain Dynamics: An Integral Reinforcement Learning Approach
Apr 01, 2021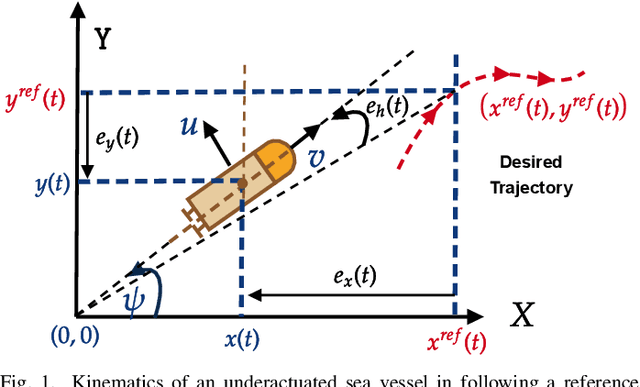
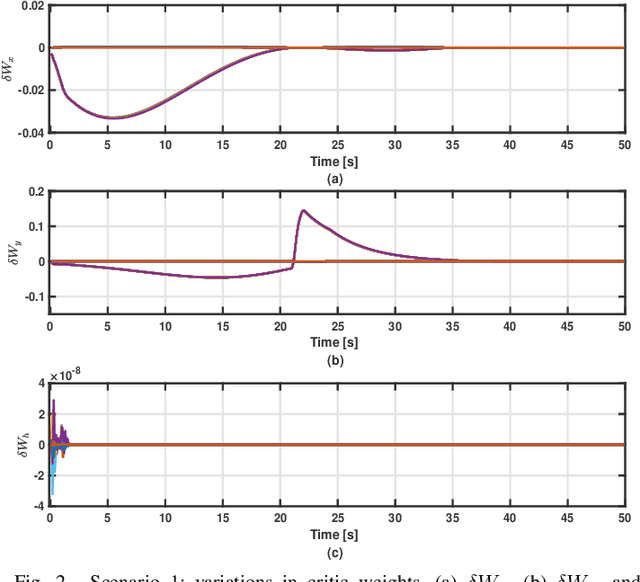
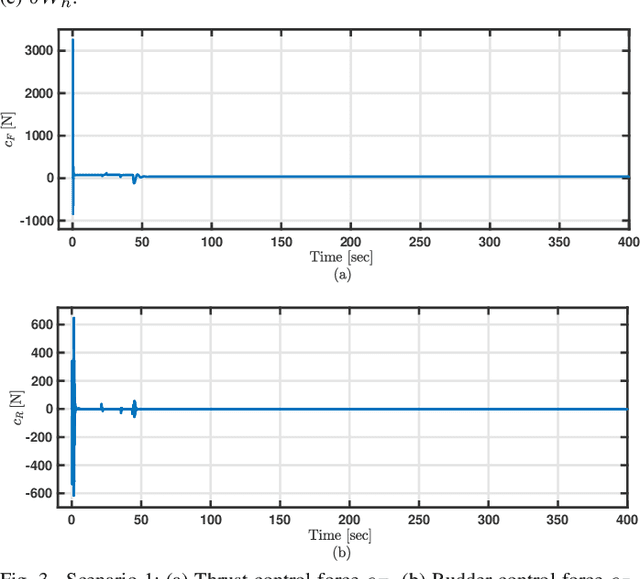
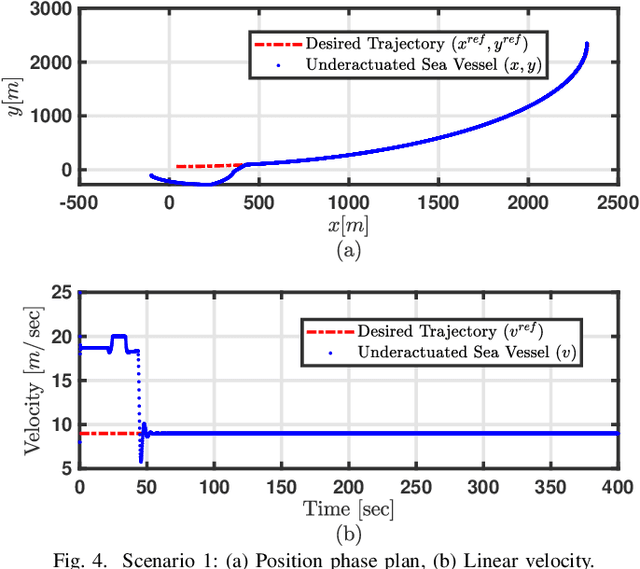
Underactuated systems like sea vessels have degrees of motion that are insufficiently matched by a set of independent actuation forces. In addition, the underlying trajectory-tracking control problems grow in complexity in order to decide the optimal rudder and thrust control signals. This enforces several difficult-to-solve constraints that are associated with the error dynamical equations using classical optimal tracking and adaptive control approaches. An online machine learning mechanism based on integral reinforcement learning is proposed to find a solution for a class of nonlinear tracking problems with partial prior knowledge of the system dynamics. The actuation forces are decided using innovative forms of temporal difference equations relevant to the vessel's surge and angular velocities. The solution is implemented using an online value iteration process which is realized by employing means of the adaptive critics and gradient descent approaches. The adaptive learning mechanism exhibited well-functioning and interactive features in react to different desired reference-tracking scenarios.