 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Policy Iteration Approach for Flock Motion Control
Paper and Code
Mar 17, 2023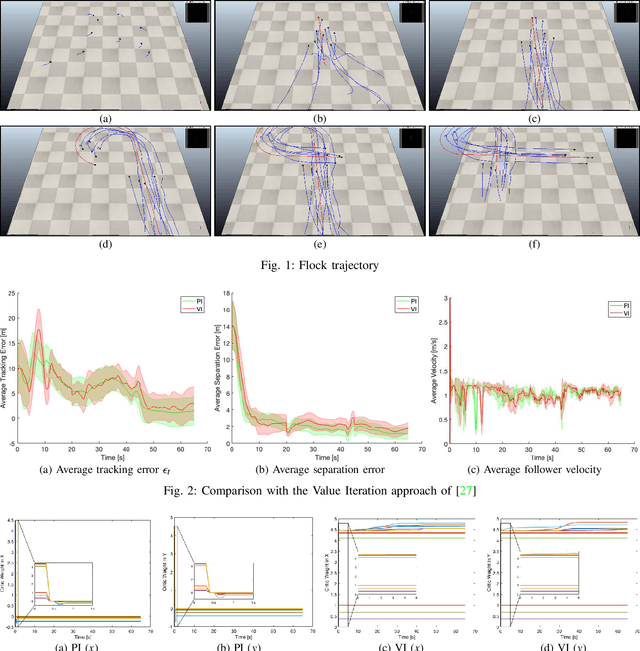
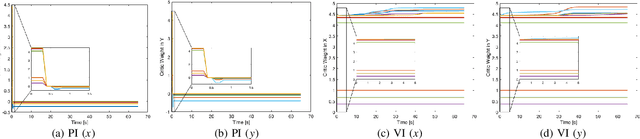
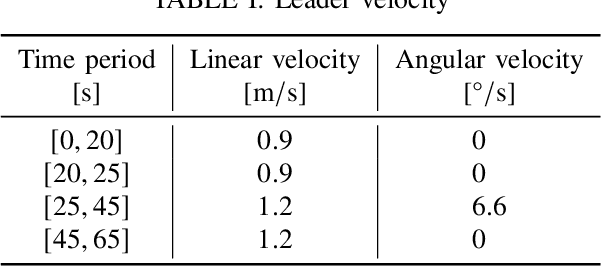
The flocking motion control is concerned with managing the possible conflicts between local and team objectives of multi-agent systems. The overall control process guides the agents while monitoring the flock-cohesiveness and localization. The underlying mechanisms may degrade due to overlooking the unmodeled uncertainties associated with the flock dynamics and formation. On another side, the efficiencies of the various control designs rely on how quickly they can adapt to different dynamic situations in real-time. An online model-free policy iteration mechanism is developed here to guide a flock of agents to follow an independent command generator over a time-varying graph topology. The strength of connectivity between any two agents or the graph edge weight is decided using a position adjacency dependent function. An online recursive least squares approach is adopted to tune the guidance strategies without knowing the dynamics of the agents or those of the command generator. It is compared with another reinforcement learning approach from the literature which is based on a value iteration technique. The simulation results of the policy iteration mechanism revealed fast learning and convergence behaviors with less computational effort.