 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Policy Iteration Approach for Flock Motion Control
Mar 17, 2023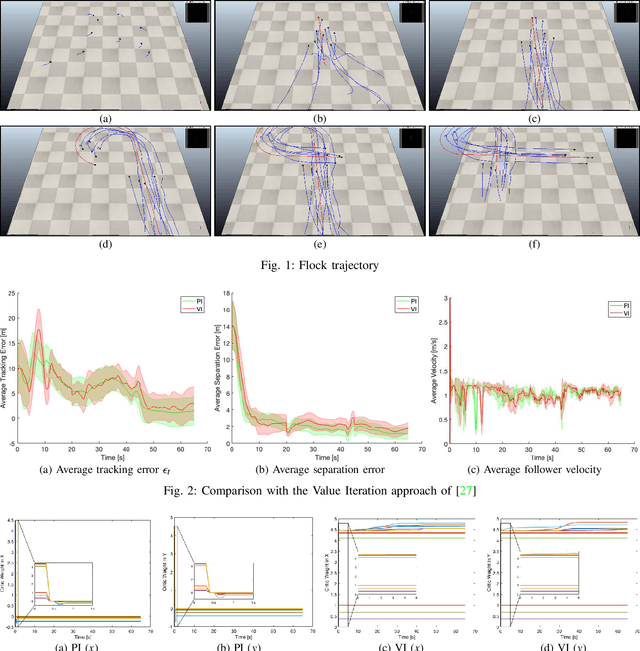
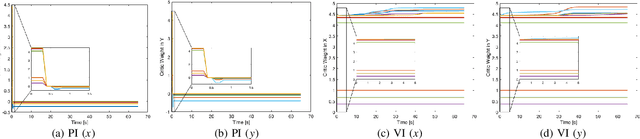
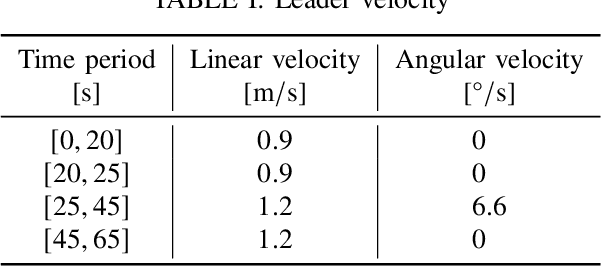
The flocking motion control is concerned with managing the possible conflicts between local and team objectives of multi-agent systems. The overall control process guides the agents while monitoring the flock-cohesiveness and localization. The underlying mechanisms may degrade due to overlooking the unmodeled uncertainties associated with the flock dynamics and formation. On another side, the efficiencies of the various control designs rely on how quickly they can adapt to different dynamic situations in real-time. An online model-free policy iteration mechanism is developed here to guide a flock of agents to follow an independent command generator over a time-varying graph topology. The strength of connectivity between any two agents or the graph edge weight is decided using a position adjacency dependent function. An online recursive least squares approach is adopted to tune the guidance strategies without knowing the dynamics of the agents or those of the command generator. It is compared with another reinforcement learning approach from the literature which is based on a value iteration technique. The simulation results of the policy iteration mechanism revealed fast learning and convergence behaviors with less computational effort.
* 7 pages, 3 figures
An Adaptive Fuzzy Reinforcement Learning Cooperative Approach for the Autonomous Control of Flock Systems
Mar 17, 2023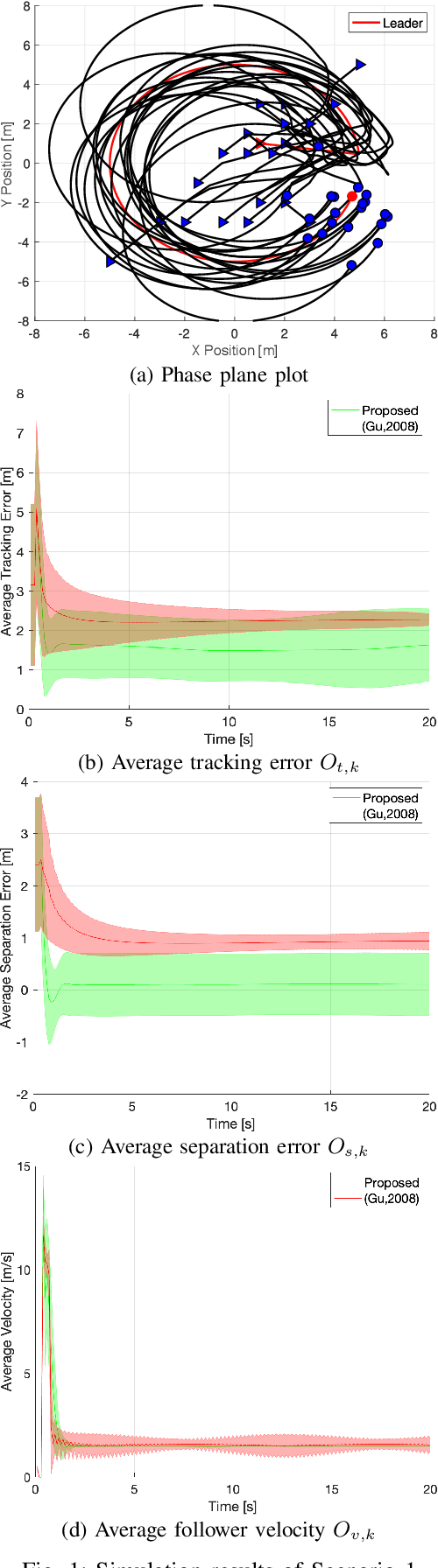
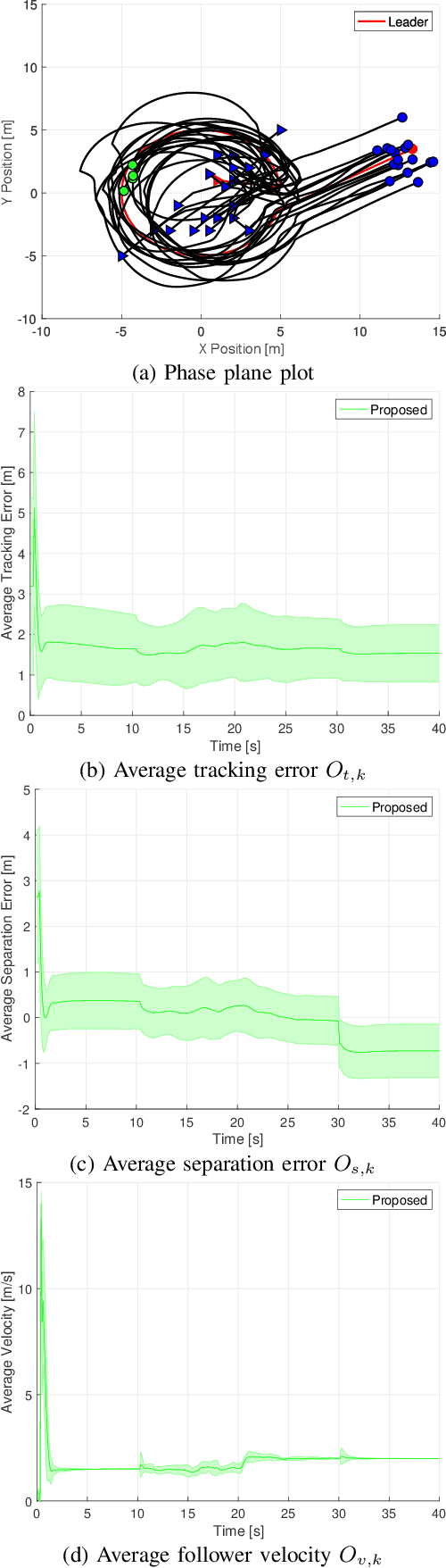
The flock-guidance problem enjoys a challenging structure where multiple optimization objectives are solved simultaneously. This usually necessitates different control approaches to tackle various objectives, such as guidance, collision avoidance, and cohesion. The guidance schemes, in particular, have long suffered from complex tracking-error dynamics. Furthermore, techniques that are based on linear feedback strategies obtained at equilibrium conditions either may not hold or degrade when applied to uncertain dynamic environments. Pre-tuned fuzzy inference architectures lack robustness under such unmodeled conditions. This work introduces an adaptive distributed technique for the autonomous control of flock systems. Its relatively flexible structure is based on online fuzzy reinforcement learning schemes which simultaneously target a number of objectives; namely, following a leader, avoiding collision, and reaching a flock velocity consensus. In addition to its resilience in the face of dynamic disturbances, the algorithm does not require more than the agent position as a feedback signal. The effectiveness of the proposed method is validated with two simulation scenarios and benchmarked against a similar technique from the literature.
* 7 pages, 2 figures
Responding to Illegal Activities Along the Canadian Coastlines Using Reinforcement Learning
Aug 05, 2021

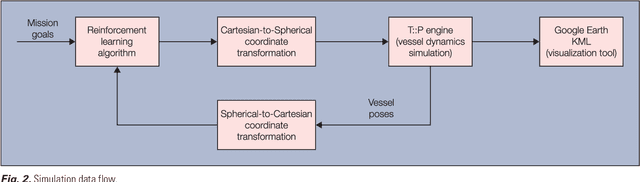
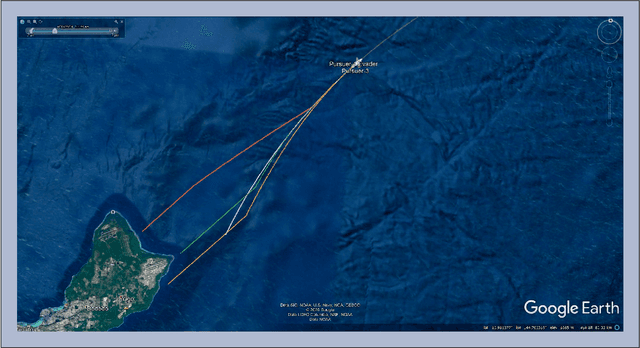
This article elaborates on how machine learning (ML) can leverage the solution of a contemporary problem related to the security of maritime domains. The worldwide ``Illegal, Unreported, and Unregulated'' (IUU) fishing incidents have led to serious environmental and economic consequences which involve drastic changes in our ecosystems in addition to financial losses caused by the depletion of natural resources. The Fisheries and Aquatic Department (FAD) of the United Nation's Food and Agriculture Organization (FAO) issued a report which indicated that the annual losses due to IUU fishing reached $25 Billion. This imposes negative impacts on the future-biodiversity of the marine ecosystem and domestic Gross National Product (GNP). Hence, robust interception mechanisms are increasingly needed for detecting and pursuing the unrelenting illegal fishing incidents in maritime territories. This article addresses the problem of coordinating the motion of a fleet of marine vessels (pursuers) to catch an IUU vessel while still in local waters. The problem is formulated as a pursuer-evader problem that is tackled within an ML framework. One or more pursuers, such as law enforcement vessels, intercept an evader (i.e., the illegal fishing ship) using an online reinforcement learning mechanism that is based on a value iteration process. It employs real-time navigation measurements of the evader ship as well as those of the pursuing vessels and returns back model-free interception strategies.