 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Data-Driven Model-Reference Adaptive Control Approach Based on Reinforcement Learning
Mar 17, 2023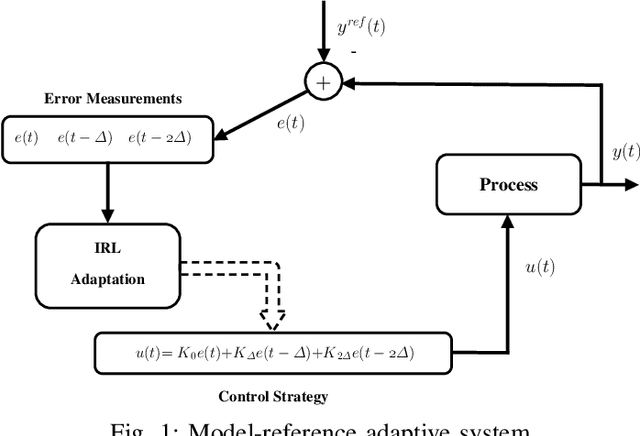
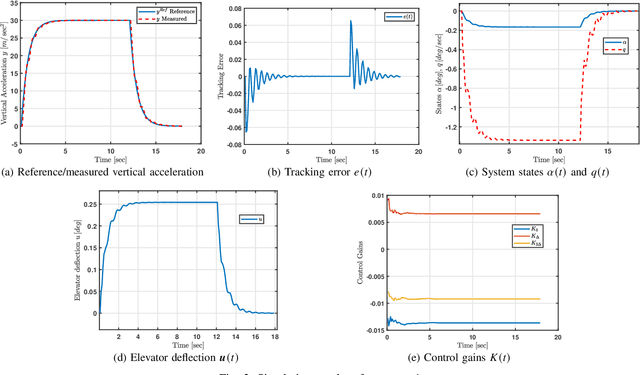
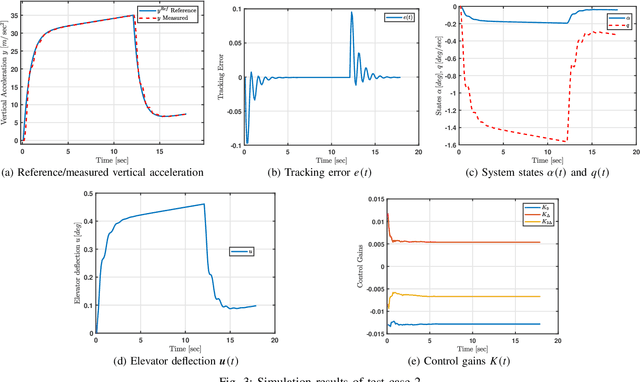
Model-reference adaptive systems refer to a consortium of techniques that guide plants to track desired reference trajectories. Approaches based on theories like Lyapunov, sliding surfaces, and backstepping are typically employed to advise adaptive control strategies. The resulting solutions are often challenged by the complexity of the reference model and those of the derived control strategies. Additionally, the explicit dependence of the control strategies on the process dynamics and reference dynamical models may contribute in degrading their efficiency in the face of uncertain or unknown dynamics. A model-reference adaptive solution is developed here for autonomous systems where it solves the Hamilton-Jacobi-Bellman equation of an error-based structure. The proposed approach describes the process with an integral temporal difference equation and solves it using an integral reinforcement learning mechanism. This is done in real-time without knowing or employing the dynamics of either the process or reference model in the control strategies. A class of aircraft is adopted to validate the proposed technique.
* 10 pages, 3 figures
Real-Time Measurement-Driven Reinforcement Learning Control Approach for Uncertain Nonlinear Systems
Mar 15, 2023

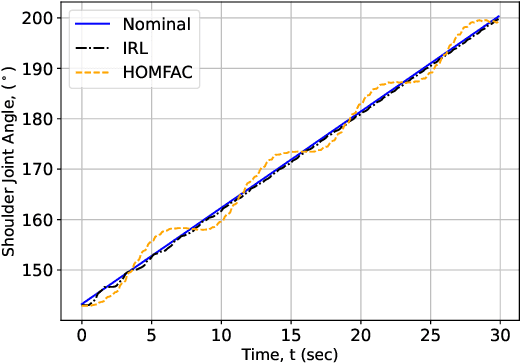
The paper introduces an interactive machine learning mechanism to process the measurements of an uncertain, nonlinear dynamic process and hence advise an actuation strategy in real-time. For concept demonstration, a trajectory-following optimization problem of a Kinova robotic arm is solved using an integral reinforcement learning approach with guaranteed stability for slowly varying dynamics. The solution is implemented using a model-free value iteration process to solve the integral temporal difference equations of the problem. The performance of the proposed technique is benchmarked against that of another model-free high-order approach and is validated for dynamic payload and disturbances. Unlike its benchmark, the proposed adaptive strategy is capable of handling extreme process variations. This is experimentally demonstrated by introducing static and time-varying payloads close to the rated maximum payload capacity of the manipulator arm. The comparison algorithm exhibited up to a seven-fold percent overshoot compared to the proposed integral reinforcement learning solution. The robustness of the algorithm is further validated by disturbing the real-time adapted strategy gains with a white noise of a standard deviation as high as 5%.
* 15 pages