 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSkim-Aware Contrastive Learning for Efficient Document Representation
Dec 30, 2025Although transformer-based models have shown strong performance in word- and sentence-level tasks, effectively representing long documents, especially in fields like law and medicine, remains difficult. Sparse attention mechanisms can handle longer inputs, but are resource-intensive and often fail to capture full-document context. Hierarchical transformer models offer better efficiency but do not clearly explain how they relate different sections of a document. In contrast, humans often skim texts, focusing on important sections to understand the overall message. Drawing from this human strategy, we introduce a new self-supervised contrastive learning framework that enhances long document representation. Our method randomly masks a section of the document and uses a natural language inference (NLI)-based contrastive objective to align it with relevant parts while distancing it from unrelated ones. This mimics how humans synthesize information, resulting in representations that are both richer and more computationally efficient. Experiments on legal and biomedical texts confirm significant gains in both accuracy and efficiency.
Natural Language Understanding for Argumentative Dialogue Systems in the Opinion Building Domain
Mar 03, 2021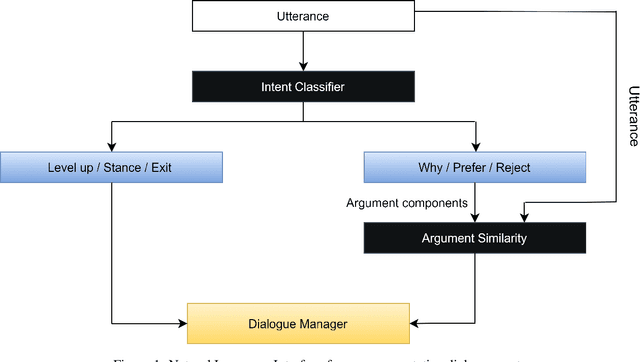

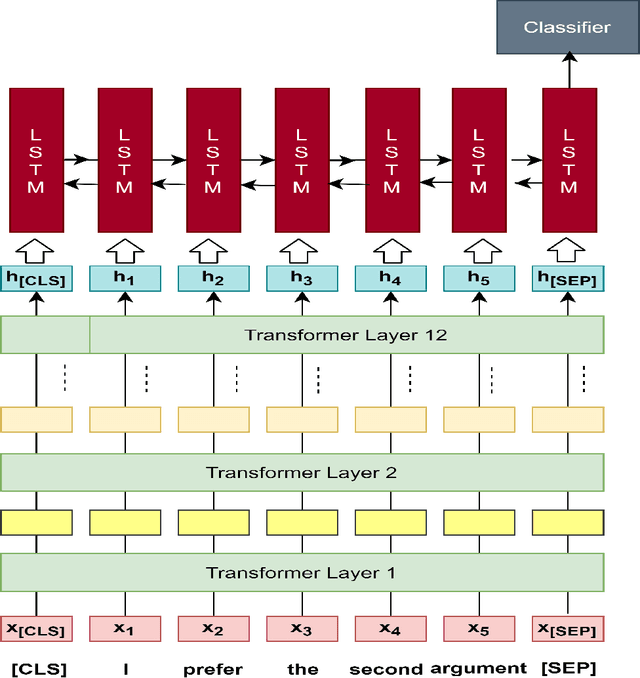

This paper introduces a natural language understanding (NLU) framework for argumentative dialogue systems in the information-seeking and opinion building domain. Our approach distinguishes multiple user intents and identifies system arguments the user refers to in his or her natural language utterances. Our model is applicable in an argumentative dialogue system that allows the user to inform him-/herself about and build his/her opinion towards a controversial topic. In order to evaluate the proposed approach, we collect user utterances for the interaction with the respective system and labeled with intent and reference argument in an extensive online study. The data collection includes multiple topics and two different user types (native speakers from the UK and non-native speakers from China). The evaluation indicates a clear advantage of the utilized techniques over baseline approaches, as well as a robustness of the proposed approach against new topics and different language proficiency as well as cultural background of the user.