 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-modal Sensor Registration for Vehicle Perception via Deep Neural Networks
Jul 08, 2015
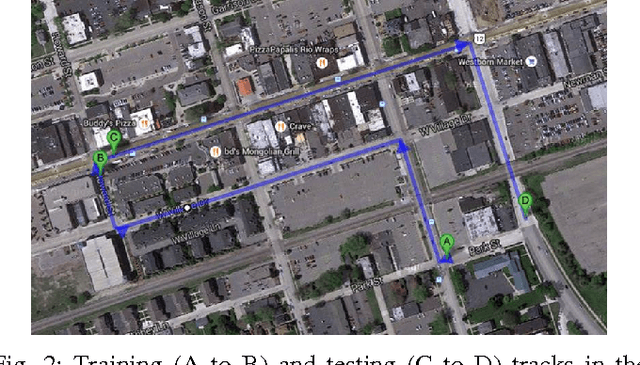

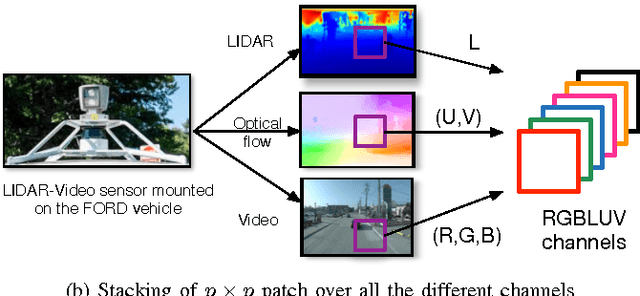
The ability to simultaneously leverage multiple modes of sensor information is critical for perception of an automated vehicle's physical surroundings. Spatio-temporal alignment of registration of the incoming information is often a prerequisite to analyzing the fused data. The persistence and reliability of multi-modal registration is therefore the key to the stability of decision support systems ingesting the fused information. LiDAR-video systems like on those many driverless cars are a common example of where keeping the LiDAR and video channels registered to common physical features is important. We develop a deep learning method that takes multiple channels of heterogeneous data, to detect the misalignment of the LiDAR-video inputs. A number of variations were tested on the Ford LiDAR-video driving test data set and will be discussed. To the best of our knowledge the use of multi-modal deep convolutional neural networks for dynamic real-time LiDAR-video registration has not been presented.
Occlusion Edge Detection in RGB-D Frames using Deep Convolutional Networks
Jul 08, 2015


Occlusion edges in images which correspond to range discontinuity in the scene from the point of view of the observer are an important prerequisite for many vision and mobile robot tasks. Although they can be extracted from range data however extracting them from images and videos would be extremely beneficial. We trained a deep convolutional neural network (CNN) to identify occlusion edges in images and videos with both RGB-D and RGB inputs. The use of CNN avoids hand-crafting of features for automatically isolating occlusion edges and distinguishing them from appearance edges. Other than quantitative occlusion edge detection results, qualitative results are provided to demonstrate the trade-off between high resolution analysis and frame-level computation time which is critical for real-time robotics applications.