 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-modal Sensor Registration for Vehicle Perception via Deep Neural Networks
Paper and Code
Jul 08, 2015
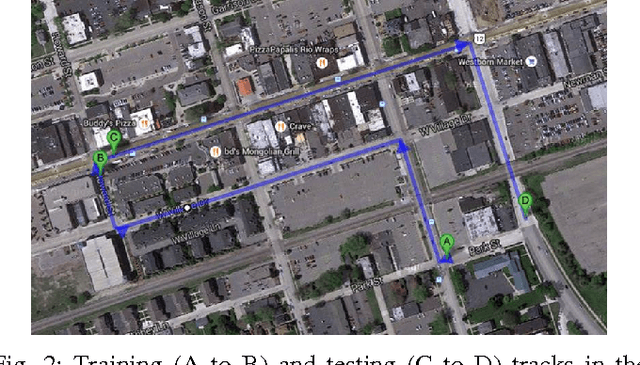

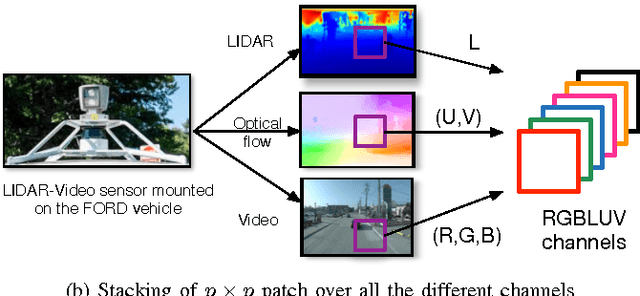
The ability to simultaneously leverage multiple modes of sensor information is critical for perception of an automated vehicle's physical surroundings. Spatio-temporal alignment of registration of the incoming information is often a prerequisite to analyzing the fused data. The persistence and reliability of multi-modal registration is therefore the key to the stability of decision support systems ingesting the fused information. LiDAR-video systems like on those many driverless cars are a common example of where keeping the LiDAR and video channels registered to common physical features is important. We develop a deep learning method that takes multiple channels of heterogeneous data, to detect the misalignment of the LiDAR-video inputs. A number of variations were tested on the Ford LiDAR-video driving test data set and will be discussed. To the best of our knowledge the use of multi-modal deep convolutional neural networks for dynamic real-time LiDAR-video registration has not been presented.