 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeColdGuess: A General and Effective Relational Graph Convolutional Network to Tackle Cold Start Cases
May 26, 2022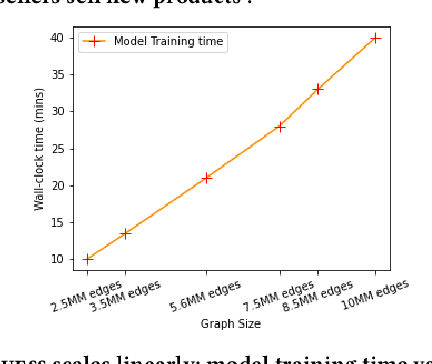


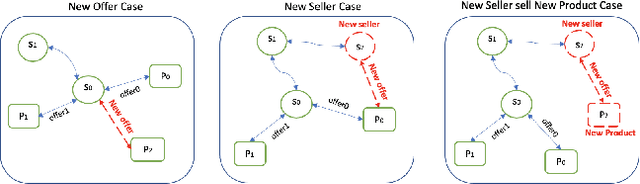
Low-quality listings and bad actor behavior in online retail websites threatens e-commerce business as these result in sub-optimal buying experience and erode customer trust. When a new listing is created, how to tell it has good-quality? Is the method effective, fast, and scalable? Previous approaches often have three limitations/challenges: (1) unable to handle cold start problems where new sellers/listings lack sufficient selling histories. (2) inability of scoring hundreds of millions of listings at scale, or compromise performance for scalability. (3) has space challenges from large-scale graph with giant e-commerce business size. To overcome these limitations/challenges, we proposed ColdGuess, an inductive graph-based risk predictor built upon a heterogeneous seller product graph, which effectively identifies risky seller/product/listings at scale. ColdGuess tackles the large-scale graph by consolidated nodes, and addresses the cold start problems using homogeneous influence1. The evaluation on real data demonstrates that ColdGuess has stable performance as the number of unknown features increases. It outperforms the lightgbm2 by up to 34 pcp ROC-AUC in a cold start case when a new seller sells a new product . The resulting system, ColdGuess, is effective, adaptable to changing risky seller behavior, and is already in production
Improving Factual Consistency of Abstractive Summarization on Customer Feedback
Jun 30, 2021
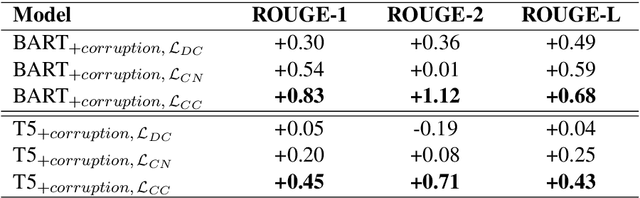
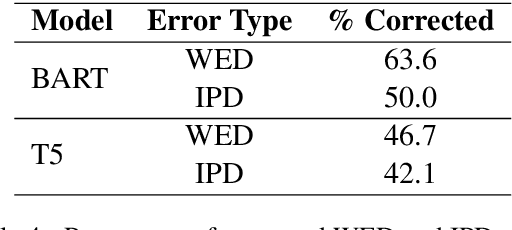

E-commerce stores collect customer feedback to let sellers learn about customer concerns and enhance customer order experience. Because customer feedback often contains redundant information, a concise summary of the feedback can be generated to help sellers better understand the issues causing customer dissatisfaction. Previous state-of-the-art abstractive text summarization models make two major types of factual errors when producing summaries from customer feedback, which are wrong entity detection (WED) and incorrect product-defect description (IPD). In this work, we introduce a set of methods to enhance the factual consistency of abstractive summarization on customer feedback. We augment the training data with artificially corrupted summaries, and use them as counterparts of the target summaries. We add a contrastive loss term into the training objective so that the model learns to avoid certain factual errors. Evaluation results show that a large portion of WED and IPD errors are alleviated for BART and T5. Furthermore, our approaches do not depend on the structure of the summarization model and thus are generalizable to any abstractive summarization systems.