 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Surprising Effects of Risk-Aware Domain Randomization for Contact-Rich Sampling-based Predictive Control
May 05, 2026Domain randomization (DR) is widely used in policy learning to improve robustness to modeling error, but remains underexplored in contact-rich sampling-based predictive control (SPC), where rollout quality is highly sensitive to uncertainty. In this work, we take the first step by studying risk-aware DR in predictive sampling on a simple yet representative Push-T task, comparing average, optimistic, and pessimistic rollout aggregations under randomized model instances. Our initial results suggest that DR affects not only robustness to model error, but also the effective cost landscape seen by the sampling-based optimizer, by reshaping the basin of attraction around contact-producing actions. This opens up potential for exploring better grounded risk-aware contact-rich SPC under model uncertainty. Video: https://youtu.be/f1F0ALXxhSM
CENIC: Convex Error-controlled Numerical Integration for Contact
Nov 11, 2025State-of-the-art robotics simulators operate in discrete time. This requires users to choose a time step, which is both critical and challenging: large steps can produce non-physical artifacts, while small steps force the simulation to run slowly. Continuous-time error-controlled integration avoids such issues by automatically adjusting the time step to achieve a desired accuracy. But existing error-controlled integrators struggle with the stiff dynamics of contact, and cannot meet the speed and scalability requirements of modern robotics workflows. We introduce CENIC, a new continuous-time integrator that brings together recent advances in convex time-stepping and error-controlled integration, inheriting benefits from both continuous integration and discrete time-stepping. CENIC runs at fast real-time rates comparable to discrete-time robotics simulators like MuJoCo, Drake and Isaac Sim, while also providing guarantees on accuracy and convergence.
Reduced-Order Model Guided Contact-Implicit Model Predictive Control for Humanoid Locomotion
Feb 21, 2025Humanoid robots have great potential for real-world applications due to their ability to operate in environments built for humans, but their deployment is hindered by the challenge of controlling their underlying high-dimensional nonlinear hybrid dynamics. While reduced-order models like the Hybrid Linear Inverted Pendulum (HLIP) are simple and computationally efficient, they lose whole-body expressiveness. Meanwhile, recent advances in Contact-Implicit Model Predictive Control (CI-MPC) enable robots to plan through multiple hybrid contact modes, but remain vulnerable to local minima and require significant tuning. We propose a control framework that combines the strengths of HLIP and CI-MPC. The reduced-order model generates a nominal gait, while CI-MPC manages the whole-body dynamics and modifies the contact schedule as needed. We demonstrate the effectiveness of this approach in simulation with a novel 24 degree-of-freedom humanoid robot: Achilles. Our proposed framework achieves rough terrain walking, disturbance recovery, robustness under model and state uncertainty, and allows the robot to interact with obstacles in the environment, all while running online in real-time at 50 Hz.
Generative Predictive Control: Flow Matching Policies for Dynamic and Difficult-to-Demonstrate Tasks
Feb 19, 2025



Generative control policies have recently unlocked major progress in robotics. These methods produce action sequences via diffusion or flow matching, with training data provided by demonstrations. But despite enjoying considerable success on difficult manipulation problems, generative policies come with two key limitations. First, behavior cloning requires expert demonstrations, which can be time-consuming and expensive to obtain. Second, existing methods are limited to relatively slow, quasi-static tasks. In this paper, we leverage a tight connection between sampling-based predictive control and generative modeling to address each of these issues. In particular, we introduce generative predictive control, a supervised learning framework for tasks with fast dynamics that are easy to simulate but difficult to demonstrate. We then show how trained flow-matching policies can be warm-started at run-time, maintaining temporal consistency and enabling fast feedback rates. We believe that generative predictive control offers a complementary approach to existing behavior cloning methods, and hope that it paves the way toward generalist policies that extend beyond quasi-static demonstration-oriented tasks.
Equality Constrained Diffusion for Direct Trajectory Optimization
Oct 02, 2024



The recent success of diffusion-based generative models in image and natural language processing has ignited interest in diffusion-based trajectory optimization for nonlinear control systems. Existing methods cannot, however, handle the nonlinear equality constraints necessary for direct trajectory optimization. As a result, diffusion-based trajectory optimizers are currently limited to shooting methods, where the nonlinear dynamics are enforced by forward rollouts. This precludes many of the benefits enjoyed by direct methods, including flexible state constraints, reduced numerical sensitivity, and easy initial guess specification. In this paper, we present a method for diffusion-based optimization with equality constraints. This allows us to perform direct trajectory optimization, enforcing dynamic feasibility with constraints rather than rollouts. To the best of our knowledge, this is the first diffusion-based optimization algorithm that supports the general nonlinear equality constraints required for direct trajectory optimization.
DROP: Dexterous Reorientation via Online Planning
Sep 22, 2024Achieving human-like dexterity is a longstanding challenge in robotics, in part due to the complexity of planning and control for contact-rich systems. In reinforcement learning (RL), one popular approach has been to use massively-parallelized, domain-randomized simulations to learn a policy offline over a vast array of contact conditions, allowing robust sim-to-real transfer. Inspired by recent advances in real-time parallel simulation, this work considers instead the viability of online planning methods for contact-rich manipulation by studying the well-known in-hand cube reorientation task. We propose a simple architecture that employs a sampling-based predictive controller and vision-based pose estimator to search for contact-rich control actions online. We conduct thorough experiments to assess the real-world performance of our method, architectural design choices, and key factors for robustness, demonstrating that our simple sampled-based approach achieves performance comparable to prior RL-based works. Supplemental material: https://caltech-amber.github.io/drop.
Inverse Dynamics Trajectory Optimization for Contact-Implicit Model Predictive Control
Sep 04, 2023


Robots must make and break contact to interact with the world and perform useful tasks. However, planning and control through contact remains a formidable challenge. In this work, we achieve real-time contact-implicit model predictive control with a surprisingly simple method: inverse dynamics trajectory optimization. While trajectory optimization with inverse dynamics is not new, we introduce a series of incremental innovations that collectively enable fast model predictive control on a variety of challenging manipulation and locomotion tasks. We implement these innovations in an open-source solver, and present a variety of simulation examples to support the effectiveness of the proposed approach. Additionally, we demonstrate contact-implicit model predictive control on hardware at over 100 Hz for a 20 degree-of-freedom bi-manual manipulation task.
Temporal Logic Motion Planning with Convex Optimization via Graphs of Convex Sets
Jan 18, 2023



Temporal logic is a concise way of specifying complex tasks. But motion planning to achieve temporal logic specifications is difficult, and existing methods struggle to scale to complex specifications and high-dimensional system dynamics. In this paper, we cast Linear Temporal Logic (LTL) motion planning as a shortest path problem in a Graph of Convex Sets (GCS) and solve it with convex optimization. This approach brings together the best of modern optimization-based temporal logic planners and older automata-theoretic methods, addressing the limitations of each: paths are represented with continuous Bezier curves, avoiding clipping and pass-through; computational complexity is polynomial (not exponential) in the number of sample points; global optimality can be certified; soundness and completeness are guaranteed under mild assumptions; and most importantly, the method scales to complex specifications and high-dimensional systems, including a 30-DoF humanoid. Open-source code is available at https://github.com/vincekurtz/ltl_gcs.
Mixed-Integer Programming for Signal Temporal Logic with Fewer Binary Variables
Apr 13, 2022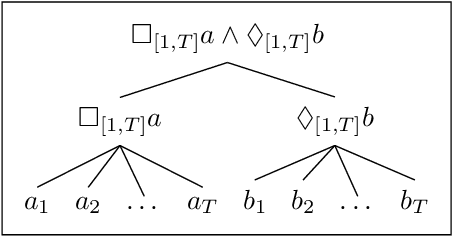
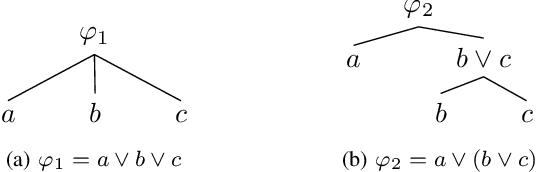
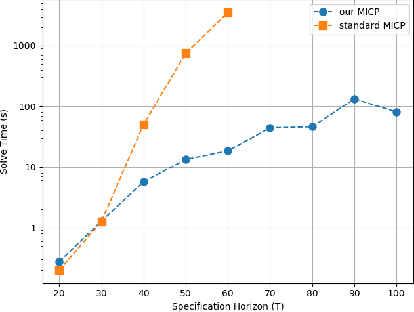
Signal Temporal Logic (STL) provides a convenient way of encoding complex control objectives for robotic and cyber-physical systems. The state-of-the-art in trajectory synthesis for STL is based on Mixed-Integer Convex Programming (MICP). The MICP approach is sound and complete, but has limited scalability due to exponential complexity in the number of binary variables. In this letter, we propose a more efficient MICP encoding for STL. Our new encoding is based on the insight that disjunction can be encoded using a logarithmic number of binary variables and conjunction can be encoded without binary variables. We demonstrate in simulation examples that our proposed approach significantly outperforms the state-of-the-art for long and complex specifications. Open-source software is available at https://stlpy.readthedocs.io .
Robust Approximate Simulation for Hierarchical Control of Piecewise Affine Systems under Bounded Disturbances
Mar 04, 2022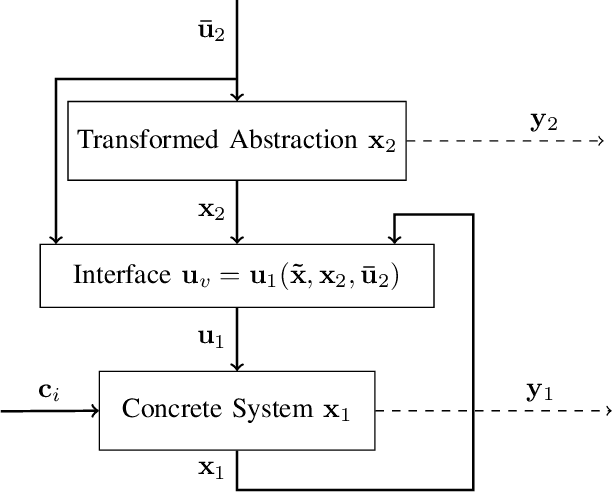
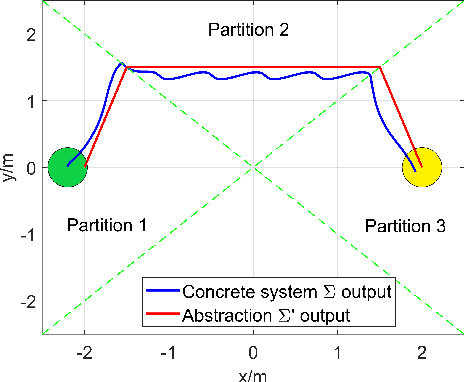
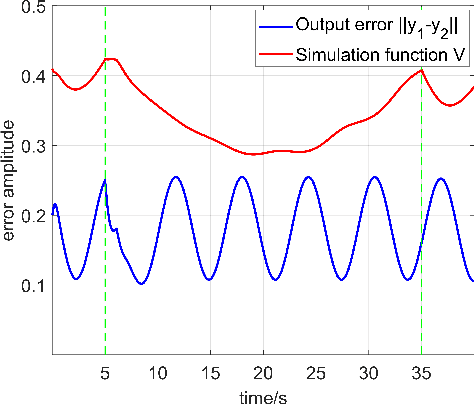
Piecewise affine (PWA) systems are widely applied in many practical cases such as the control of nonlinear systems and hybrid dynamics. However, most of the existing PWA control methods have poor scalability with respect to the number of modes and system dimensions and may not be robust to the disturbances in performance. In this paper, we present a robust approximate simulation based control method for PWA systems under bounded external disturbances. First, a lower-dimensional linear system (abstraction) and an associated interface are designed to enable the output of the PWA system (concrete system) to track the output of the abstraction. Then, a Lyapunov-like simulation function is designed to show the boundedness of the output errors between the two systems. Furthermore, the results obtained for linear abstraction are extended to the case that a simpler PWA system is the abstraction. To illustrate the effectiveness of the proposed approach, simulation results are provided for two design examples.