 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDocling: An Efficient Open-Source Toolkit for AI-driven Document Conversion
Jan 27, 2025



We introduce Docling, an easy-to-use, self-contained, MIT-licensed, open-source toolkit for document conversion, that can parse several types of popular document formats into a unified, richly structured representation. It is powered by state-of-the-art specialized AI models for layout analysis (DocLayNet) and table structure recognition (TableFormer), and runs efficiently on commodity hardware in a small resource budget. Docling is released as a Python package and can be used as a Python API or as a CLI tool. Docling's modular architecture and efficient document representation make it easy to implement extensions, new features, models, and customizations. Docling has been already integrated in other popular open-source frameworks (e.g., LangChain, LlamaIndex, spaCy), making it a natural fit for the processing of documents and the development of high-end applications. The open-source community has fully engaged in using, promoting, and developing for Docling, which gathered 10k stars on GitHub in less than a month and was reported as the No. 1 trending repository in GitHub worldwide in November 2024.
Docling Technical Report
Aug 19, 2024



This technical report introduces Docling, an easy to use, self-contained, MIT-licensed open-source package for PDF document conversion. It is powered by state-of-the-art specialized AI models for layout analysis (DocLayNet) and table structure recognition (TableFormer), and runs efficiently on commodity hardware in a small resource budget. The code interface allows for easy extensibility and addition of new features and models.
Robust PDF Document Conversion Using Recurrent Neural Networks
Feb 18, 2021
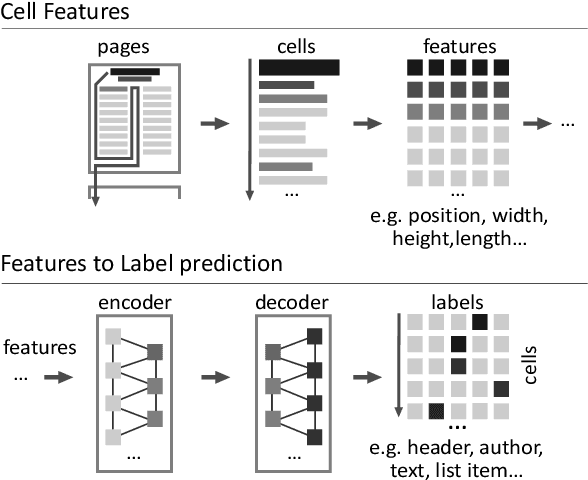


The number of published PDF documents has increased exponentially in recent decades. There is a growing need to make their rich content discoverable to information retrieval tools. In this paper, we present a novel approach to document structure recovery in PDF using recurrent neural networks to process the low-level PDF data representation directly, instead of relying on a visual re-interpretation of the rendered PDF page, as has been proposed in previous literature. We demonstrate how a sequence of PDF printing commands can be used as input into a neural network and how the network can learn to classify each printing command according to its structural function in the page. This approach has three advantages: First, it can distinguish among more fine-grained labels (typically 10-20 labels as opposed to 1-5 with visual methods), which results in a more accurate and detailed document structure resolution. Second, it can take into account the text flow across pages more naturally compared to visual methods because it can concatenate the printing commands of sequential pages. Last, our proposed method needs less memory and it is computationally less expensive than visual methods. This allows us to deploy such models in production environments at a much lower cost. Through extensive architectural search in combination with advanced feature engineering, we were able to implement a model that yields a weighted average F1 score of 97% across 17 distinct structural labels. The best model we achieved is currently served in production environments on our Corpus Conversion Service (CCS), which was presented at KDD18 (arXiv:1806.02284). This model enhances the capabilities of CCS significantly, as it eliminates the need for human annotated label ground-truth for every unseen document layout. This proved particularly useful when applied to a huge corpus of PDF articles related to COVID-19.