 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust PDF Document Conversion Using Recurrent Neural Networks
Feb 18, 2021
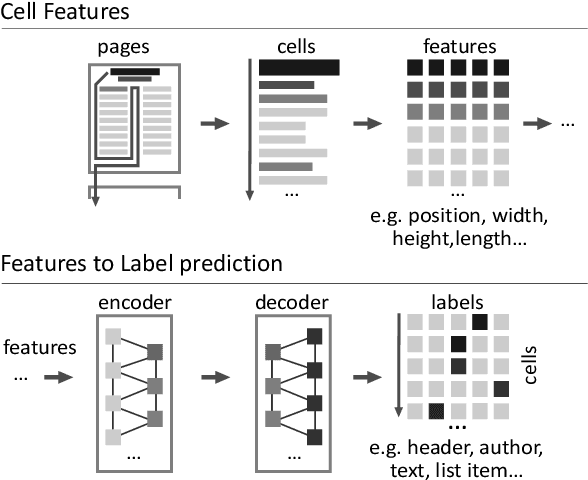


The number of published PDF documents has increased exponentially in recent decades. There is a growing need to make their rich content discoverable to information retrieval tools. In this paper, we present a novel approach to document structure recovery in PDF using recurrent neural networks to process the low-level PDF data representation directly, instead of relying on a visual re-interpretation of the rendered PDF page, as has been proposed in previous literature. We demonstrate how a sequence of PDF printing commands can be used as input into a neural network and how the network can learn to classify each printing command according to its structural function in the page. This approach has three advantages: First, it can distinguish among more fine-grained labels (typically 10-20 labels as opposed to 1-5 with visual methods), which results in a more accurate and detailed document structure resolution. Second, it can take into account the text flow across pages more naturally compared to visual methods because it can concatenate the printing commands of sequential pages. Last, our proposed method needs less memory and it is computationally less expensive than visual methods. This allows us to deploy such models in production environments at a much lower cost. Through extensive architectural search in combination with advanced feature engineering, we were able to implement a model that yields a weighted average F1 score of 97% across 17 distinct structural labels. The best model we achieved is currently served in production environments on our Corpus Conversion Service (CCS), which was presented at KDD18 (arXiv:1806.02284). This model enhances the capabilities of CCS significantly, as it eliminates the need for human annotated label ground-truth for every unseen document layout. This proved particularly useful when applied to a huge corpus of PDF articles related to COVID-19.
Towards a reinforcement learning de novo genome assembler
Feb 02, 2021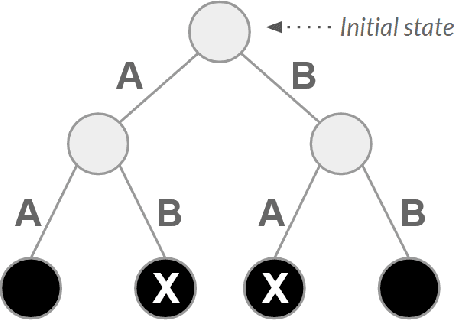
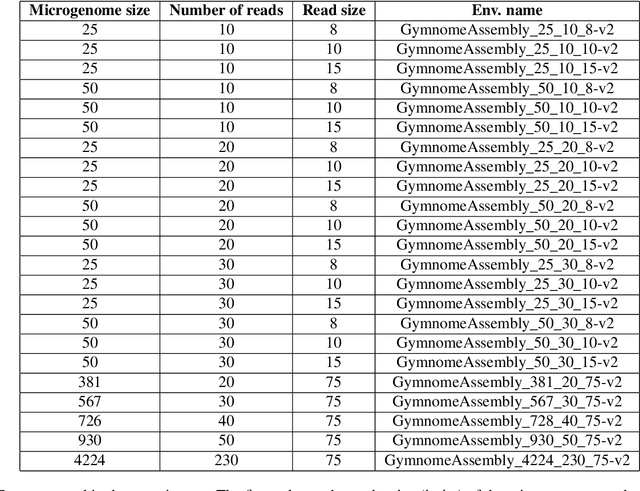
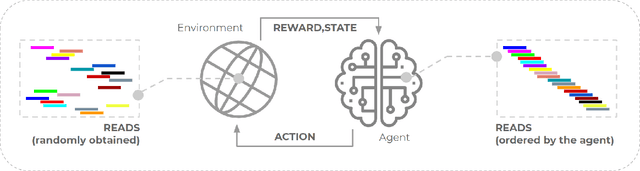

The use of reinforcement learning has proven to be very promising for solving complex activities without human supervision during their learning process. However, their successful applications are predominantly focused on fictional and entertainment problems - such as games. Based on the above, this work aims to shed light on the application of reinforcement learning to solve this relevant real-world problem, the genome assembly. By expanding the only approach found in the literature that addresses this problem, we carefully explored the aspects of intelligent agent learning, performed by the Q-learning algorithm, to understand its suitability to be applied in scenarios whose characteristics are more similar to those faced by real genome projects. The improvements proposed here include changing the previously proposed reward system and including state space exploration optimization strategies based on dynamic pruning and mutual collaboration with evolutionary computing. These investigations were tried on 23 new environments with larger inputs than those used previously. All these environments are freely available on the internet for the evolution of this research by the scientific community. The results suggest consistent performance progress using the proposed improvements, however, they also demonstrate the limitations of them, especially related to the high dimensionality of state and action spaces. We also present, later, the paths that can be traced to tackle genome assembly efficiently in real scenarios considering recent, successfully reinforcement learning applications - including deep reinforcement learning - from other domains dealing with high-dimensional inputs.