 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Classifier Evaluation: A Fairer Benchmarking Strategy Based on Ability and Robustness
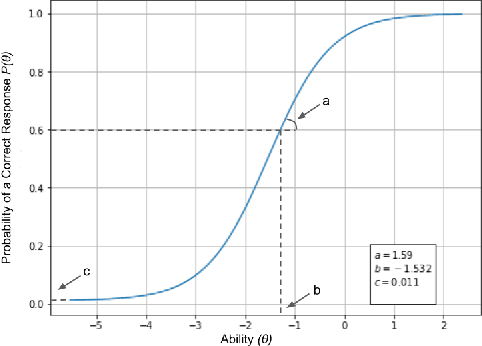
Apr 13, 2025Benchmarking is a fundamental practice in machine learning (ML) for comparing the performance of classification algorithms. However, traditional evaluation methods often overlook a critical aspect: the joint consideration of dataset complexity and an algorithm's ability to generalize. Without this dual perspective, assessments may favor models that perform well on easy instances while failing to capture their true robustness. To address this limitation, this study introduces a novel evaluation methodology that combines Item Response Theory (IRT) with the Glicko-2 rating system, originally developed to measure player strength in competitive games. IRT assesses classifier ability based on performance over difficult instances, while Glicko-2 updates performance metrics - such as rating, deviation, and volatility - via simulated tournaments between classifiers. This combined approach provides a fairer and more nuanced measure of algorithm capability. A case study using the OpenML-CC18 benchmark showed that only 15% of the datasets are truly challenging and that a reduced subset with 50% of the original datasets offers comparable evaluation power. Among the algorithms tested, Random Forest achieved the highest ability score. The results highlight the importance of improving benchmark design by focusing on dataset quality and adopting evaluation strategies that reflect both difficulty and classifier proficiency.
How Reliable and Stable are Explanations of XAI Methods?
Jul 03, 2024Black box models are increasingly being used in the daily lives of human beings living in society. Along with this increase, there has been the emergence of Explainable Artificial Intelligence (XAI) methods aimed at generating additional explanations regarding how the model makes certain predictions. In this sense, methods such as Dalex, Eli5, eXirt, Lofo and Shap emerged as different proposals and methodologies for generating explanations of black box models in an agnostic way. Along with the emergence of these methods, questions arise such as "How Reliable and Stable are XAI Methods?". With the aim of shedding light on this main question, this research creates a pipeline that performs experiments using the diabetes dataset and four different machine learning models (LGBM, MLP, DT and KNN), creating different levels of perturbations of the test data and finally generates explanations from the eXirt method regarding the confidence of the models and also feature relevances ranks from all XAI methods mentioned, in order to measure their stability in the face of perturbations. As a result, it was found that eXirt was able to identify the most reliable models among all those used. It was also found that current XAI methods are sensitive to perturbations, with the exception of one specific method.
Black Box Model Explanations and the Human Interpretability Expectations -- An Analysis in the Context of Homicide Prediction
Oct 19, 2022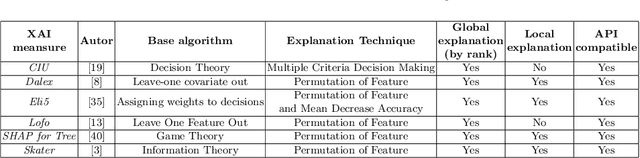
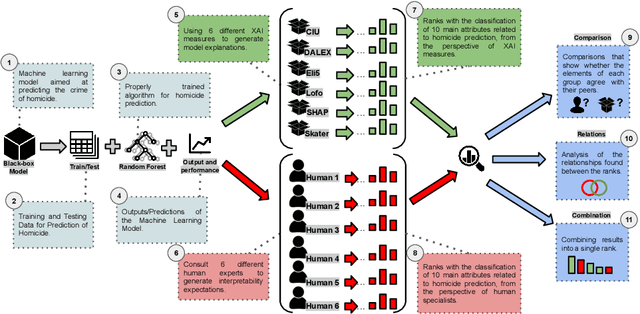
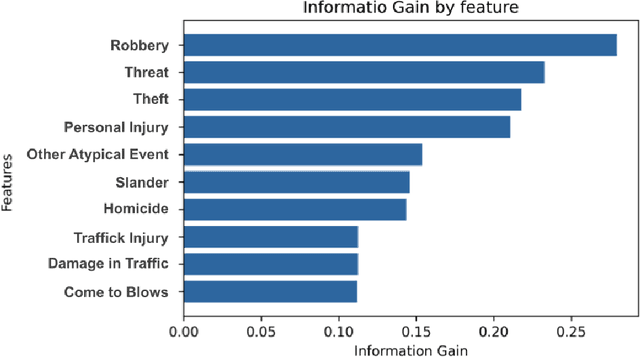
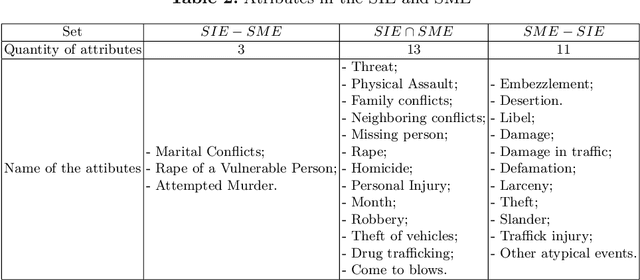
Strategies based on Explainable Artificial Intelligence - XAI have promoted better human interpretability of the results of black box machine learning models. The XAI measures being currently used (Ciu, Dalex, Eli5, Lofo, Shap, and Skater) provide various forms of explanations, including global rankings of relevance of attributes. Current research points to the need for further studies on how these explanations meet the Interpretability Expectations of human experts and how they can be used to make the model even more transparent while taking into account specific complexities of the model and dataset being analyzed, as well as important human factors of sensitive real-world contexts/problems. Intending to shed light on the explanations generated by XAI measures and their interpretabilities, this research addresses a real-world classification problem related to homicide prediction, duly endorsed by the scientific community, replicated its proposed black box model and used 6 different XAI measures to generate explanations and 6 different human experts to generate what this research referred to as Interpretability Expectations - IE. The results were computed by means of comparative analysis and identification of relationships among all the attribute ranks produced, and ~49% concordance was found among attributes indicated by means of XAI measures and human experts, ~41% exclusively by XAI measures and ~10% exclusively by human experts. The results allow for answering: "Do the different XAI measures generate similar explanations for the proposed problem?", "Are the interpretability expectations generated among different human experts similar?", "Do the explanations generated by XAI measures meet the interpretability expectations of human experts?" and "Can Interpretability Explanations and Expectations work together?", all of which concerning the context of homicide prediction.
Global Explanation of Tree-Ensembles Models Based on Item Response Theory
Oct 18, 2022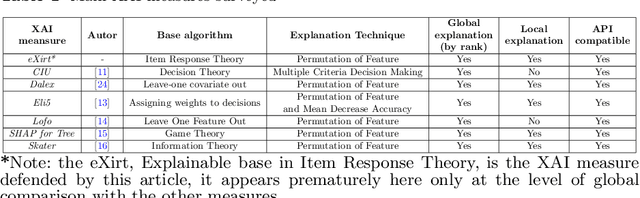

Explainable Artificial Intelligence - XAI is aimed at studying and developing techniques to explain black box models, that is, models that provide limited self-explanation of their predictions. In recent years, XAI researchers have been formalizing proposals and developing new measures to explain how these models make specific predictions. In previous studies, evidence has been found on how model (dataset and algorithm) complexity affects global explanations generated by XAI measures Ciu, Dalex, Eli5, Lofo, Shap and Skater, suggesting that there is room for the development of a new XAI measure that builds on the complexity of the model. Thus, this research proposes a measure called Explainable based on Item Response Theory - eXirt, which is capable of explaining tree-ensemble models by using the properties of Item Response Theory (IRT). For this purpose, a benchmark was created using 40 different datasets and 2 different algorithms (Random Forest and Gradient Boosting), thus generating 6 different explainability ranks using known XAI measures along with 1 data purity rank and 1 rank of the measure eXirt, amounting to 8 global ranks for each model, i.e., 640 ranks altogether. The results show that eXirt displayed different ranks than those of the other measures, which demonstrates that the advocated methodology generates global explanations of tree-ensemble models that have not yet been explored, either for the more difficult models to explain or even the easier ones.
Does Dataset Complexity Matters for Model Explainers?
Jul 06, 2021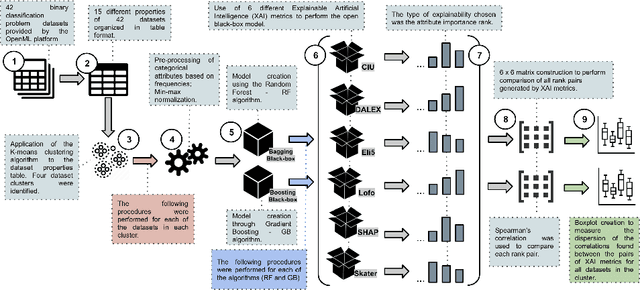
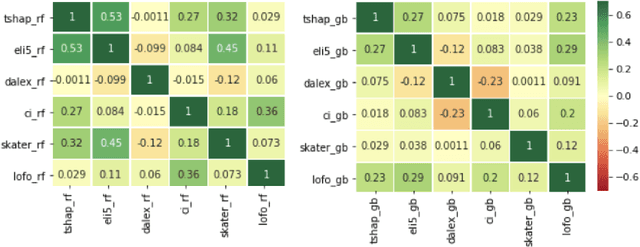
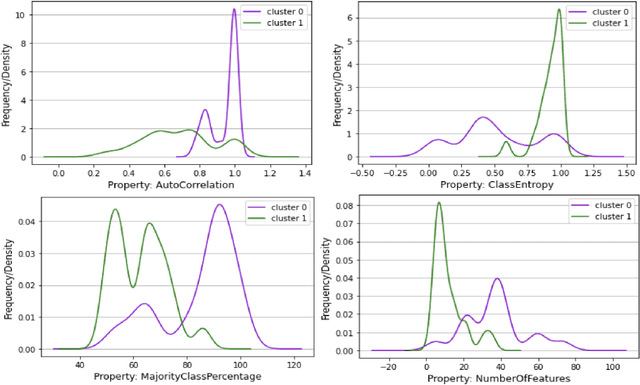
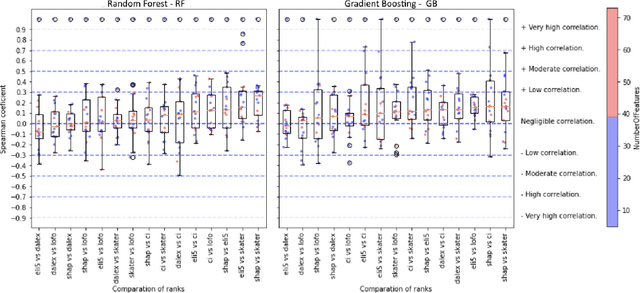
Strategies based on Explainable Artificial Intelligence - XAI have emerged in computing to promote a better understanding of predictions made by black box models. Most XAI-based tools used today explain these types of models, generating attribute rankings aimed at explaining the same, that is, the analysis of Attribute Importance. There is no consensus on which XAI tool generates a general rank of explainability, for this reason, several proposals for tools have emerged (Ciu, Dalex, Eli5, Lofo, Shap and Skater). Here, we present an experimental benchmark of explainable AI techniques capable of producing model-agnostic global explainability ranks based on tabular data related to different problems. Seeking to answer questions such as "Are the explanations generated by the different tools the same, similar or different?" and "How does data complexity play along model explainability?". The results from the construction of 82 computational models and 592 ranks give us some light on the other side of the problem of explainability: dataset complexity!
Towards a reinforcement learning de novo genome assembler
Feb 02, 2021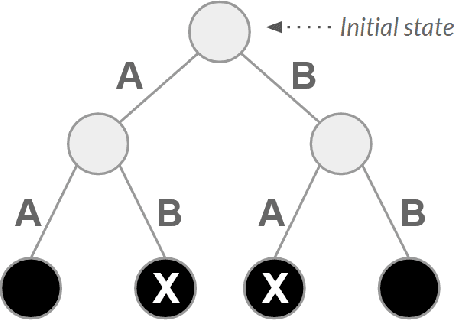
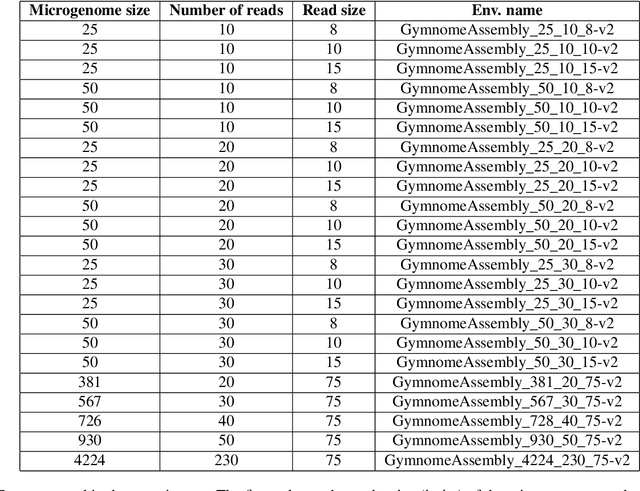
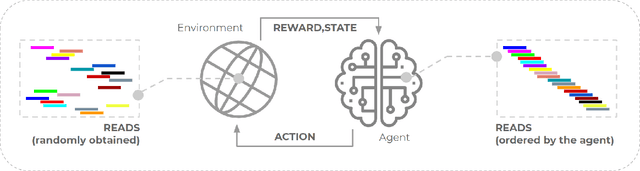

The use of reinforcement learning has proven to be very promising for solving complex activities without human supervision during their learning process. However, their successful applications are predominantly focused on fictional and entertainment problems - such as games. Based on the above, this work aims to shed light on the application of reinforcement learning to solve this relevant real-world problem, the genome assembly. By expanding the only approach found in the literature that addresses this problem, we carefully explored the aspects of intelligent agent learning, performed by the Q-learning algorithm, to understand its suitability to be applied in scenarios whose characteristics are more similar to those faced by real genome projects. The improvements proposed here include changing the previously proposed reward system and including state space exploration optimization strategies based on dynamic pruning and mutual collaboration with evolutionary computing. These investigations were tried on 23 new environments with larger inputs than those used previously. All these environments are freely available on the internet for the evolution of this research by the scientific community. The results suggest consistent performance progress using the proposed improvements, however, they also demonstrate the limitations of them, especially related to the high dimensionality of state and action spaces. We also present, later, the paths that can be traced to tackle genome assembly efficiently in real scenarios considering recent, successfully reinforcement learning applications - including deep reinforcement learning - from other domains dealing with high-dimensional inputs.
Prediction of Homicides in Urban Centers: A Machine Learning Approach
Aug 19, 2020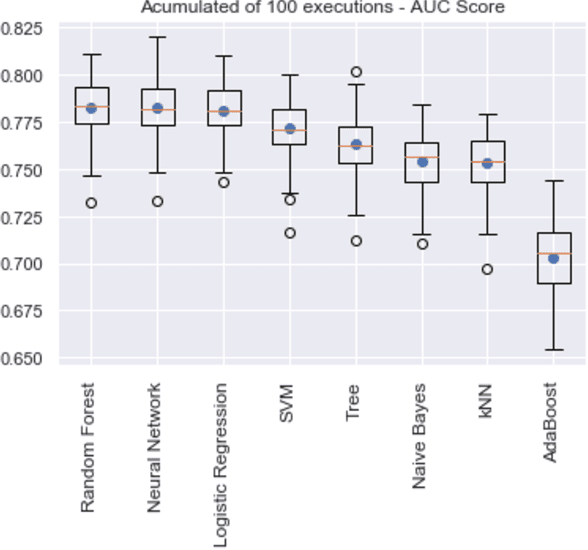
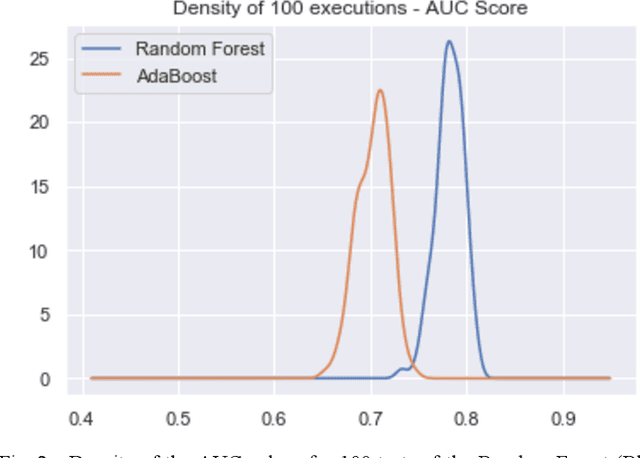
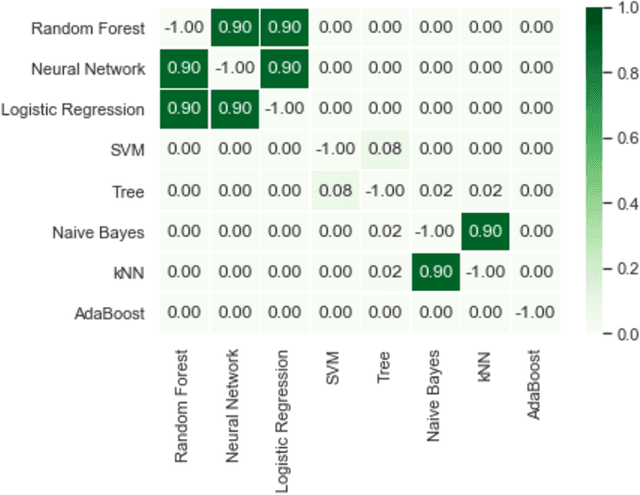
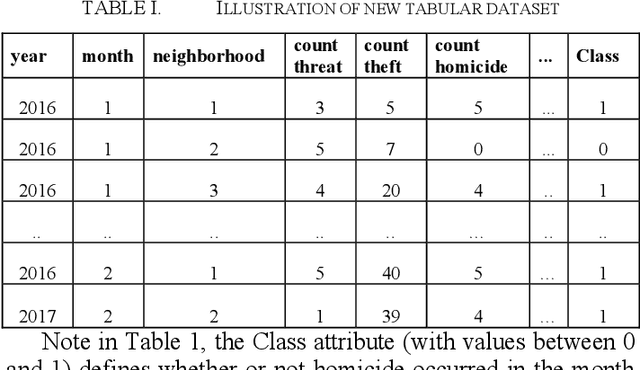
Relevant research has been standing out in the computing community aiming to develop computational models capable of predicting occurrence of crimes, analyzing contexts of crimes, extracting profiles of individuals linked to crimes, and analyzing crimes according to time. This, due to the social impact and also the complex origin of the data, thus showing itself as an interesting computational challenge. This research presents a computational model for the prediction of homicide crimes, based on tabular data of crimes registered in the city of Bel\'em - Par\'a, Brazil. Statistical tests were performed with 8 different classification methods, both Random Forest, Logistic Regression, and Neural Network presented best results, AUC ~ 0.8. Results considered as a baseline for the proposed problem.