 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGlobal Explanation of Tree-Ensembles Models Based on Item Response Theory
Oct 18, 2022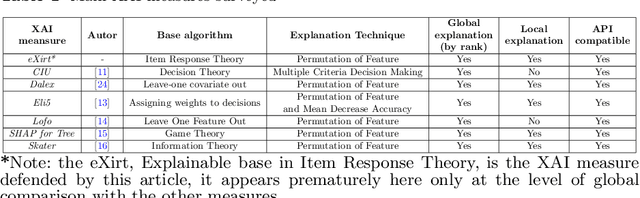
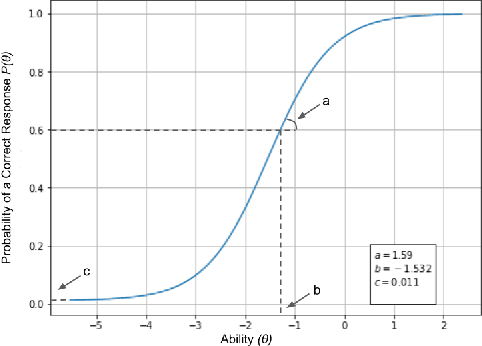

Explainable Artificial Intelligence - XAI is aimed at studying and developing techniques to explain black box models, that is, models that provide limited self-explanation of their predictions. In recent years, XAI researchers have been formalizing proposals and developing new measures to explain how these models make specific predictions. In previous studies, evidence has been found on how model (dataset and algorithm) complexity affects global explanations generated by XAI measures Ciu, Dalex, Eli5, Lofo, Shap and Skater, suggesting that there is room for the development of a new XAI measure that builds on the complexity of the model. Thus, this research proposes a measure called Explainable based on Item Response Theory - eXirt, which is capable of explaining tree-ensemble models by using the properties of Item Response Theory (IRT). For this purpose, a benchmark was created using 40 different datasets and 2 different algorithms (Random Forest and Gradient Boosting), thus generating 6 different explainability ranks using known XAI measures along with 1 data purity rank and 1 rank of the measure eXirt, amounting to 8 global ranks for each model, i.e., 640 ranks altogether. The results show that eXirt displayed different ranks than those of the other measures, which demonstrates that the advocated methodology generates global explanations of tree-ensemble models that have not yet been explored, either for the more difficult models to explain or even the easier ones.
Does Dataset Complexity Matters for Model Explainers?
Jul 06, 2021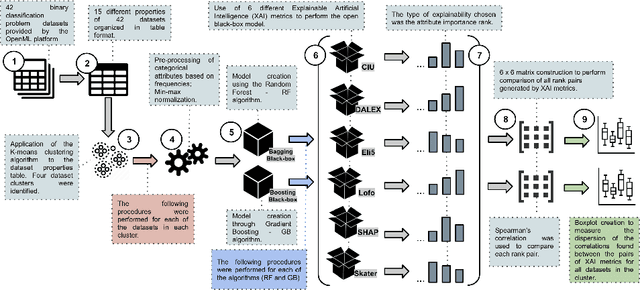
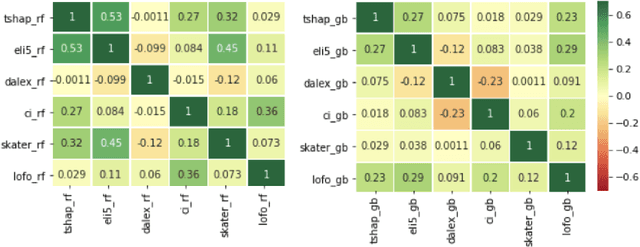
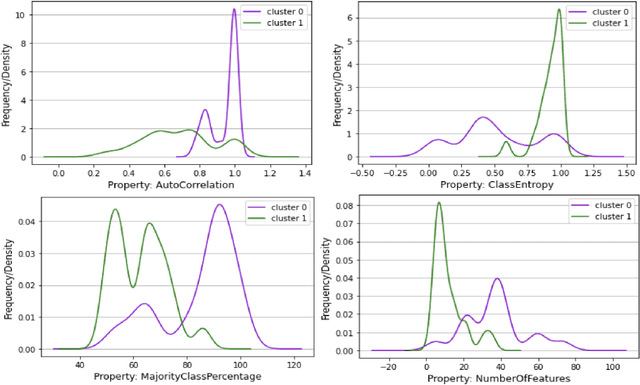
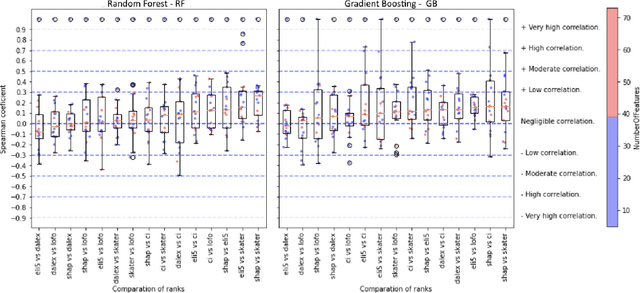
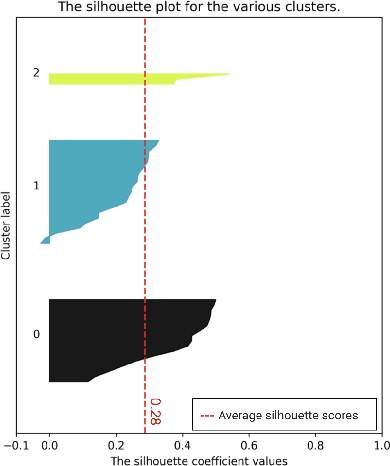
Strategies based on Explainable Artificial Intelligence - XAI have emerged in computing to promote a better understanding of predictions made by black box models. Most XAI-based tools used today explain these types of models, generating attribute rankings aimed at explaining the same, that is, the analysis of Attribute Importance. There is no consensus on which XAI tool generates a general rank of explainability, for this reason, several proposals for tools have emerged (Ciu, Dalex, Eli5, Lofo, Shap and Skater). Here, we present an experimental benchmark of explainable AI techniques capable of producing model-agnostic global explainability ranks based on tabular data related to different problems. Seeking to answer questions such as "Are the explanations generated by the different tools the same, similar or different?" and "How does data complexity play along model explainability?". The results from the construction of 82 computational models and 592 ranks give us some light on the other side of the problem of explainability: dataset complexity!