 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierRouter: Coordinated Routing of Specialized Large Language Models via Reinforcement Learning
Nov 13, 2025Large Language Models (LLMs) deliver state-of-the-art performance across many tasks but impose high computational and memory costs, limiting their deployment in resource-constrained or real-time settings. To address this, we propose HierRouter, a hierarchical routing approach that dynamically assembles inference pipelines from a pool of specialized, lightweight language models. Formulated as a finite-horizon Markov Decision Process (MDP), our approach trains a Proximal Policy Optimization (PPO)-based reinforcement learning agent to iteratively select which models to invoke at each stage of multi-hop inference. The agent conditions on the evolving context and accumulated cost to make context-aware routing decisions. Experiments with three open-source candidate LLMs across six benchmarks, including QA, code generation, and mathematical reasoning, show that HierRouter improves response quality by up to 2.4x compared to using individual models independently, while incurring only a minimal additional inference cost on average. These results highlight the promise of hierarchical routing for cost-efficient, high-performance LLM inference. All codes can be found here https://github.com/ Nikunj-Gupta/hierouter.
Attention, Distillation, and Tabularization: Towards Practical Neural Network-Based Prefetching
Jan 16, 2024



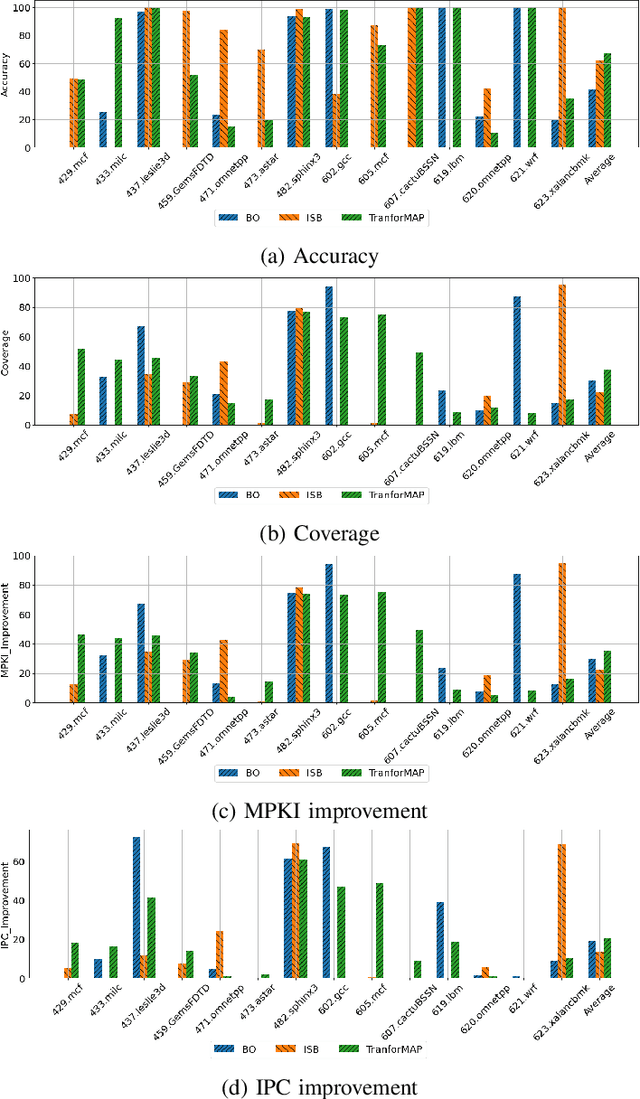
Attention-based Neural Networks (NN) have demonstrated their effectiveness in accurate memory access prediction, an essential step in data prefetching. However, the substantial computational overheads associated with these models result in high inference latency, limiting their feasibility as practical prefetchers. To close the gap, we propose a new approach based on tabularization that significantly reduces model complexity and inference latency without sacrificing prediction accuracy. Our novel tabularization methodology takes as input a distilled, yet highly accurate attention-based model for memory access prediction and efficiently converts its expensive matrix multiplications into a hierarchy of fast table lookups. As an exemplar of the above approach, we develop DART, a prefetcher comprised of a simple hierarchy of tables. With a modest 0.09 drop in F1-score, DART reduces 99.99% of arithmetic operations from the large attention-based model and 91.83% from the distilled model. DART accelerates the large model inference by 170x and the distilled model by 9.4x. DART has comparable latency and storage costs as state-of-the-art rule-based prefetcher BO but surpasses it by 6.1% in IPC improvement. DART outperforms state-of-the-art NN-based prefetchers TransFetch by 33.1% and Voyager by 37.2% in terms of IPC improvement, primarily due to its low prefetching latency.
Phases, Modalities, Temporal and Spatial Locality: Domain Specific ML Prefetcher for Accelerating Graph Analytics
Dec 10, 2022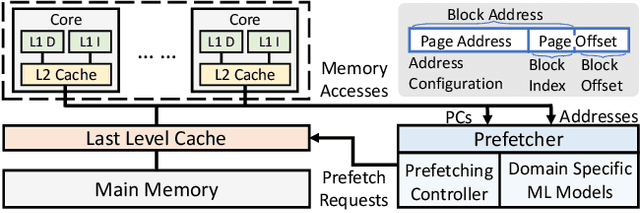
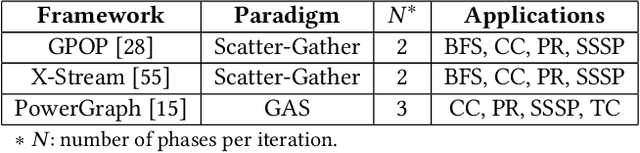
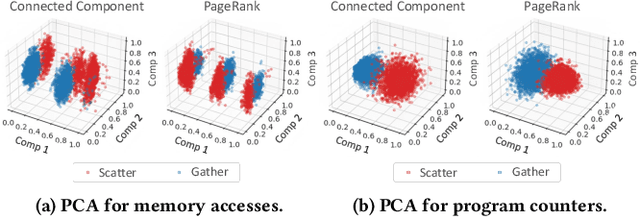
Graph processing applications are severely bottlenecked by memory system performance due to low data reuse and irregular memory accesses. While state-of-the-art prefetchers using Machine Learning (ML) have made great progress, they do not perform well on graph analytics applications due to phase transitions in the execution and irregular data access that is hard to predict. We propose MPGraph: a novel ML-based Prefetcher for Graph analytics. MPGraph makes three novel optimizations based on domain knowledge of graph analytics. It detects the transition of graph processing phases during execution using a novel soft detection technique, predicts memory accesses and pages using phase-specific multi-modality predictors, and prefetches using a novel chain spatio-temporal prefetching strategy. We evaluate our approach using three widely-used graph processing frameworks and a variety of graph datasets. Our approach achieves 34.17%-82.15% higher precision in phase transition detection than the KSWIN and decision tree baselines. Our predictors achieve 6.80%-16.02% higher F1-score for access prediction and 11.68%-15.41% higher accuracy-at-10 for page prediction compared with the baselines LSTM-based and vanilla attention-based models. Simulations show that MPGraph achieves on the average 87.16% (prefetch accuracy) and 73.29% (prefetch coverage), leading to 12.52%-21.23% IPC improvement. It outperforms the widely-used non-ML prefetcher BO by 7.58%-12.03%, and outperforms state-of-the-art ML-based prefetchers Voyager by 3.27%-4.42% and TransFetch by 3.73%-4.58% with respect to IPC improvement.
TransforMAP: Transformer for Memory Access Prediction
May 29, 2022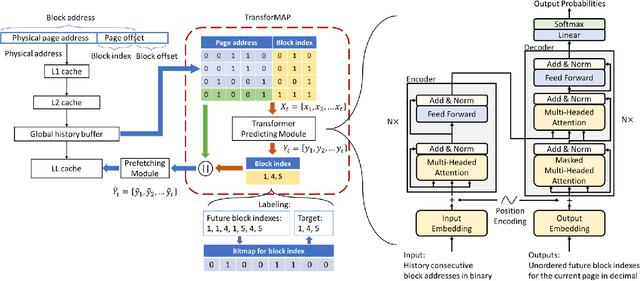
Data Prefetching is a technique that can hide memory latency by fetching data before it is needed by a program. Prefetching relies on accurate memory access prediction, to which task machine learning based methods are increasingly applied. Unlike previous approaches that learn from deltas or offsets and perform one access prediction, we develop TransforMAP, based on the powerful Transformer model, that can learn from the whole address space and perform multiple cache line predictions. We propose to use the binary of memory addresses as model input, which avoids information loss and saves a token table in hardware. We design a block index bitmap to collect unordered future page offsets under the current page address as learning labels. As a result, our model can learn temporal patterns as well as spatial patterns within a page. In a practical implementation, this approach has the potential to hide prediction latency because it prefetches multiple cache lines likely to be used in a long horizon. We show that our approach achieves 35.67% MPKI improvement and 20.55% IPC improvement in simulation, higher than state-of-the-art Best-Offset prefetcher and ISB prefetcher.
Fine-Grained Address Segmentation for Attention-Based Variable-Degree Prefetching
May 01, 2022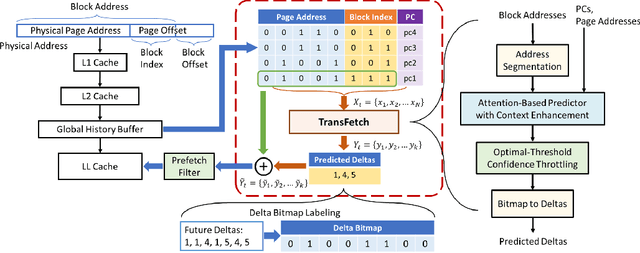
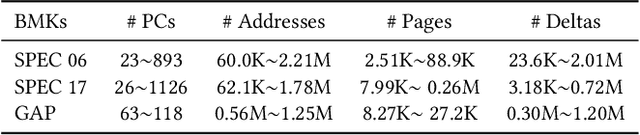
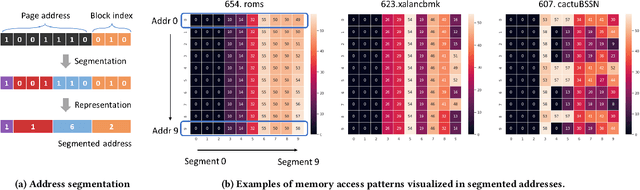
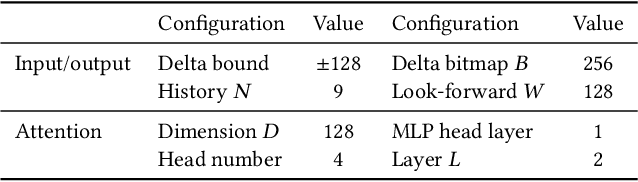
Machine learning algorithms have shown potential to improve prefetching performance by accurately predicting future memory accesses. Existing approaches are based on the modeling of text prediction, considering prefetching as a classification problem for sequence prediction. However, the vast and sparse memory address space leads to large vocabulary, which makes this modeling impractical. The number and order of outputs for multiple cache line prefetching are also fundamentally different from text prediction. We propose TransFetch, a novel way to model prefetching. To reduce vocabulary size, we use fine-grained address segmentation as input. To predict unordered sets of future addresses, we use delta bitmaps for multiple outputs. We apply an attention-based network to learn the mapping between input and output. Prediction experiments demonstrate that address segmentation achieves 26% - 36% higher F1-score than delta inputs and 15% - 24% higher F1-score than page & offset inputs for SPEC 2006, SPEC 2017, and GAP benchmarks. Simulation results show that TransFetch achieves 38.75% IPC improvement compared with no prefetching, outperforming the best-performing rule-based prefetcher BOP by 10.44%, and ML-based prefetcher Voyager by 6.64%.
The EpiBench Platform to Propel AI/ML-based Epidemic Forecasting: A Prototype Demonstration Reaching Human Expert-level Performance
Feb 04, 2021
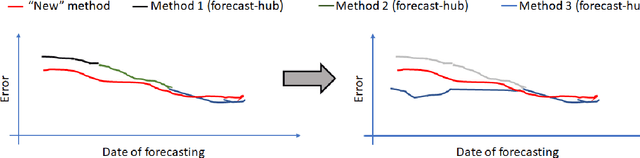
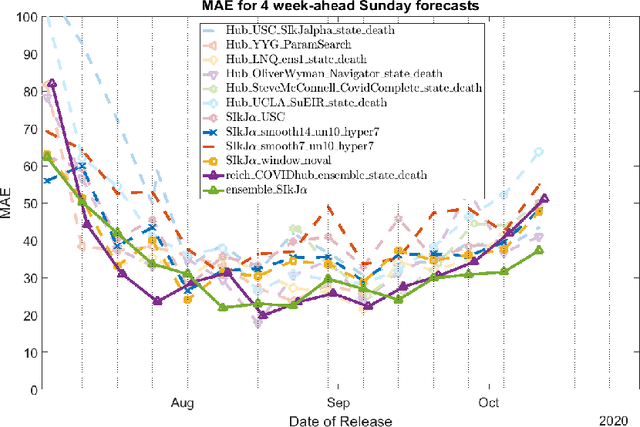
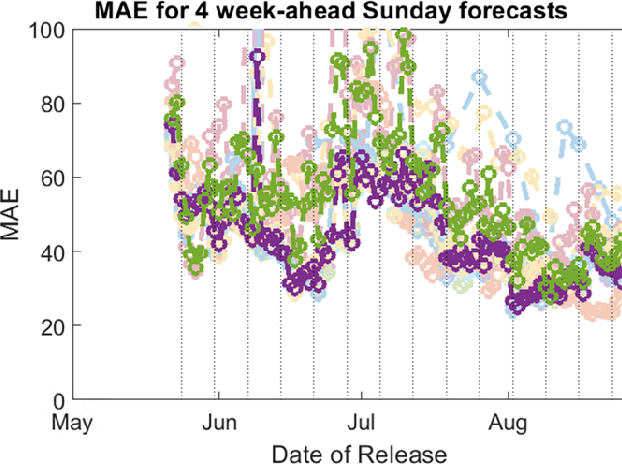
During the COVID-19 pandemic, a significant effort has gone into developing ML-driven epidemic forecasting techniques. However, benchmarks do not exist to claim if a new AI/ML technique is better than the existing ones. The "covid-forecast-hub" is a collection of more than 30 teams, including us, that submit their forecasts weekly to the CDC. It is not possible to declare whether one method is better than the other using those forecasts because each team's submission may correspond to different techniques over the period and involve human interventions as the teams are continuously changing/tuning their approach. Such forecasts may be considered "human-expert" forecasts and do not qualify as AI/ML approaches, although they can be used as an indicator of human expert performance. We are interested in supporting AI/ML research in epidemic forecasting which can lead to scalable forecasting without human intervention. Which modeling technique, learning strategy, and data pre-processing technique work well for epidemic forecasting is still an open problem. To help advance the state-of-the-art AI/ML applied to epidemiology, a benchmark with a collection of performance points is needed and the current "state-of-the-art" techniques need to be identified. We propose EpiBench a platform consisting of community-driven benchmarks for AI/ML applied to epidemic forecasting to standardize the challenge with a uniform evaluation protocol. In this paper, we introduce a prototype of EpiBench which is currently running and accepting submissions for the task of forecasting COVID-19 cases and deaths in the US states and We demonstrate that we can utilize the prototype to develop an ensemble relying on fully automated epidemic forecasts (no human intervention) that reaches human-expert level ensemble currently being used by the CDC.
Fast and Accurate Forecasting of COVID-19 Deaths Using the SIkJ$α$ Model
Jul 13, 2020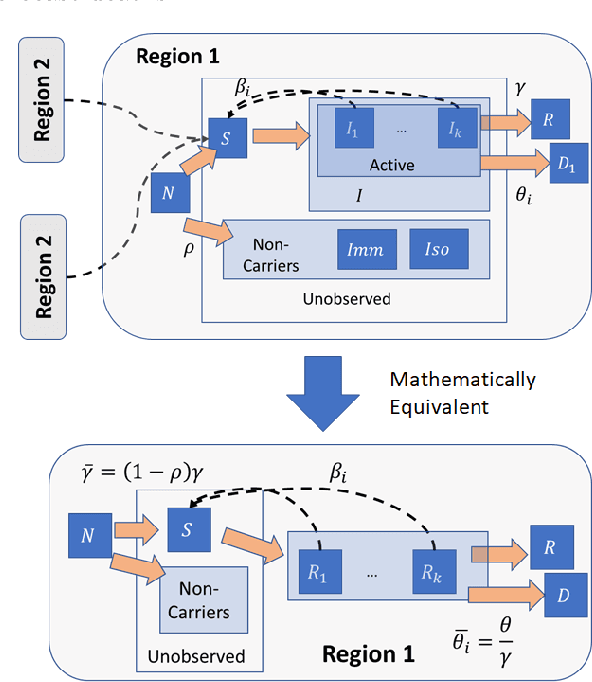
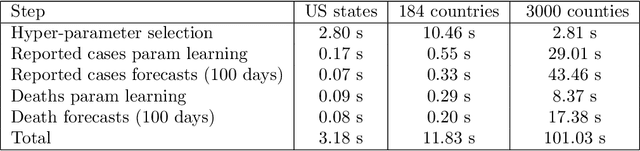
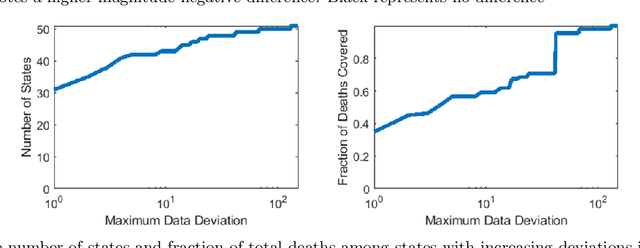
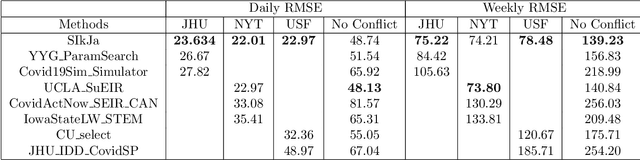
Forecasting the effect of COVID-19 is essential to design policies that may prepare us to handle the pandemic. Many methods have already been proposed, particularly, to forecast reported cases and deaths at country-level and state-level. Many of these methods are based on traditional epidemiological model which rely on simulations or Bayesian inference to simultaneously learn many parameters at a time. This makes them prone to over-fitting and slow execution. We propose an extension to our model SIkJ$\alpha$ to forecast deaths and show that it can consider the effect of many complexities of the epidemic process and yet be simplified to a few parameters that are learned using fast linear regressions. We also present an evaluation of our method against seven approaches currently being used by the CDC, based on their two weeks forecast at various times during the pandemic. We demonstrate that our method achieves better root mean squared error compared to these seven approaches during majority of the evaluation period. Further, on a 2 core desktop machine, our approach takes only 3.18s to tune hyper-parameters, learn parameters and generate 100 days of forecasts of reported cases and deaths for all the states in the US. The total execution time for 184 countries is 11.83s and for all the US counties ($>$ 3000) is 101.03s.
Data-driven Identification of Number of Unreported Cases for COVID-19: Bounds and Limitations
Jun 15, 2020
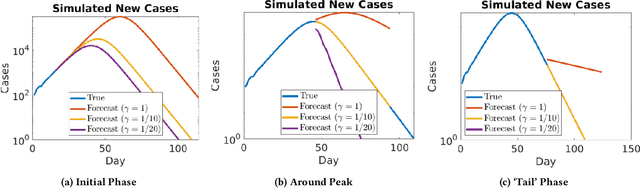

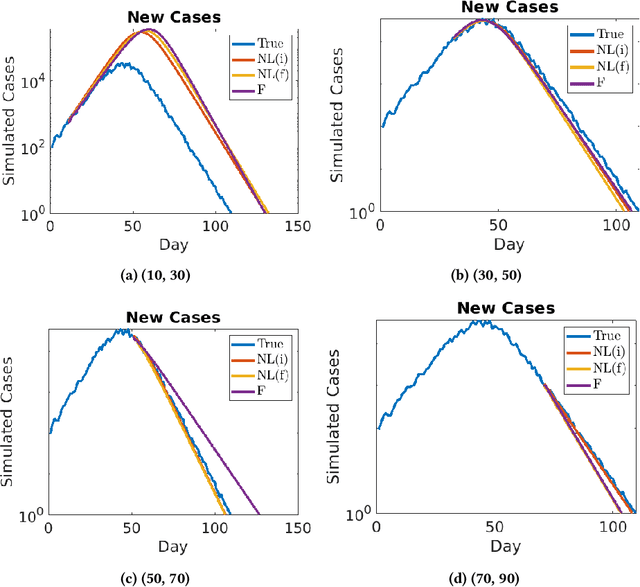
Accurate forecasts for COVID-19 are necessary for better preparedness and resource management. Specifically, deciding the response over months or several months requires accurate long-term forecasts which is particularly challenging as the model errors accumulate with time. A critical factor that can hinder accurate long-term forecasts, is the number of unreported/asymptomatic cases. While there have been early serology tests to estimate this number, more tests need to be conducted for more reliable results. To identify the number of unreported/asymptomatic cases, we take an epidemiology data-driven approach. We show that we can identify lower bounds on this ratio or upper bound on actual cases as a factor of reported cases. To do so, we propose an extension of our prior heterogeneous infection rate model, incorporating unreported/asymptomatic cases. We prove that the number of unreported cases can be reliably estimated only from a certain time period of the epidemic data. In doing so, we construct an algorithm called Fixed Infection Rate method, which identifies a reliable bound on the learned ratio. We also propose two heuristics to learn this ratio and show their effectiveness on simulated data. We use our approaches to identify the upper bounds on the ratio of actual to reported cases for New York City and several US states. Our results demonstrate with high confidence that the actual number of cases cannot be more than 35 times in New York, 40 times in Illinois, 38 times in Massachusetts and 29 times in New Jersey, than the reported cases.
Learning to Forecast and Forecasting to Learn from the COVID-19 Pandemic
May 04, 2020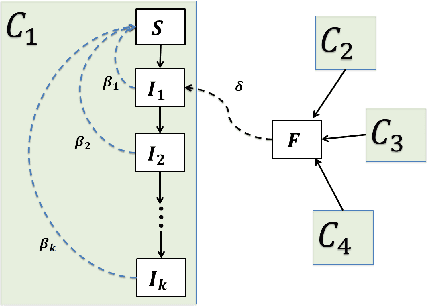
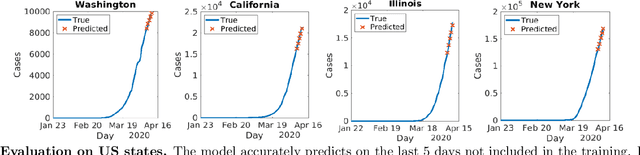
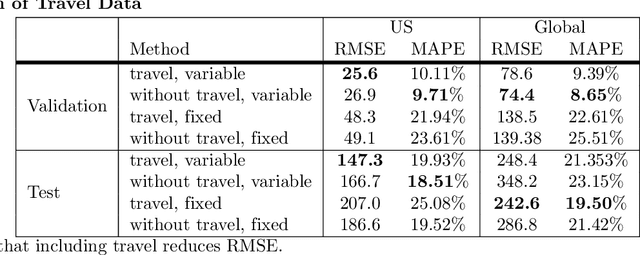
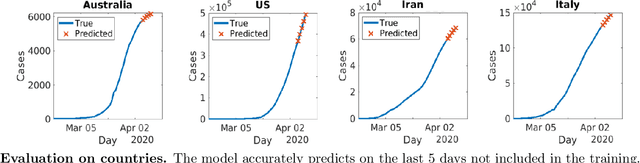
Accurate forecasts of COVID-19 is central to resource management and building strategies to deal with the epidemic. We propose a heterogeneous infection rate model with human mobility for epidemic modeling, a preliminary version of which we have successfully used during DARPA Grand Challenge 2014. By linearizing the model and using weighted least squares, our model is able to quickly adapt to changing trends and provide extremely accurate predictions of confirmed cases at the level of countries and states of the United States. We show that during the earlier part of the epidemic, using travel data increases the predictions. Training the model to forecast also enables learning characteristics of the epidemic. In particular, we show that changes in model parameters over time can help us quantify how well a state or a country has responded to the epidemic. The variations in parameters also allow us to forecast different scenarios such as what would happen if we were to disregard social distancing suggestions.
Towards High Performance, Portability, and Productivity: Lightweight Augmented Neural Networks for Performance Prediction
Mar 17, 2020
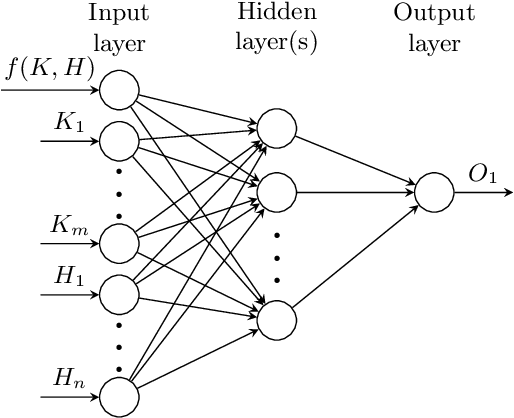
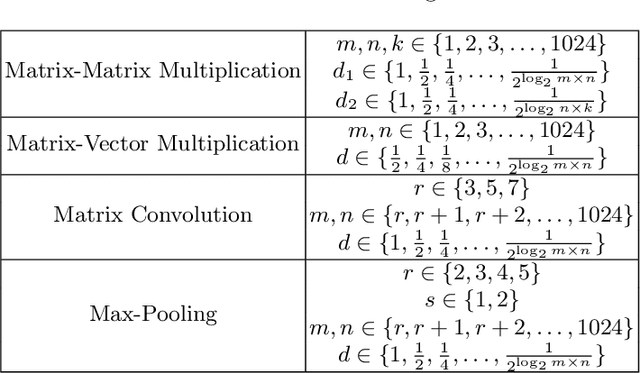
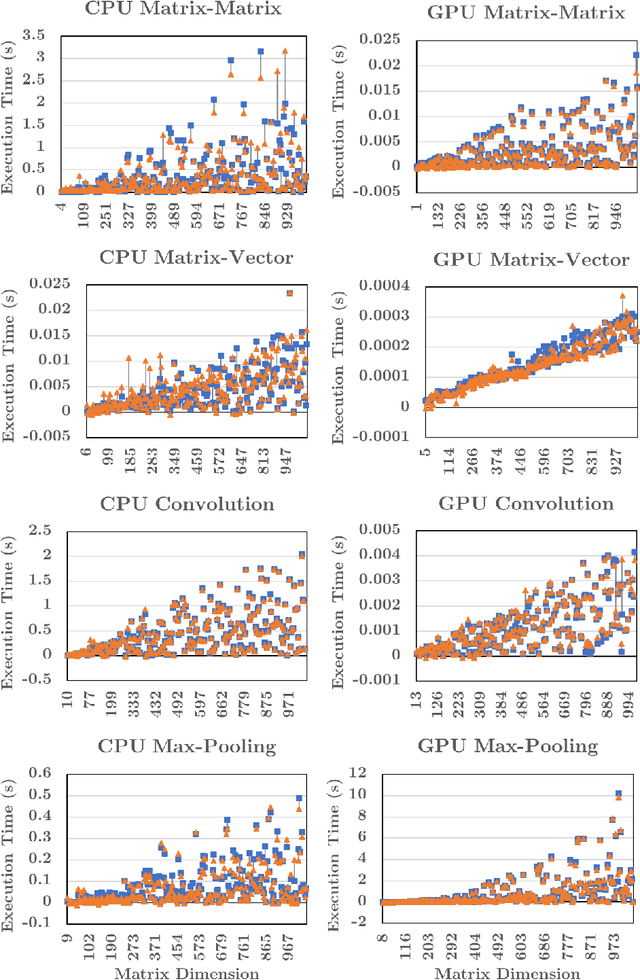
Writing high-performance code requires significant expertise of the programming language, compiler optimizations, and hardware knowledge. This often leads to poor productivity and portability and is inconvenient for a non-programmer domain-specialist such as a Physicist. More desirable is a high-level language where the domain-specialist simply specifies the workload in terms of high-level operations (e.g., matrix-multiply(A, B)) and the compiler identifies the best implementation fully utilizing the heterogeneous platform. For creating a compiler that supports productivity, portability, and performance simultaneously, it is crucial to predict performance of various available implementations (variants) of the dominant operations (kernels) contained in the workload on various hardware to decide (a) which variant should be chosen for each kernel in the workload, and (b) on which hardware resource the variant should run. To enable the performance prediction, we propose lightweight augmented neural networks for arbitrary combinations of kernel-variant-hardware. A key innovation is utilizing mathematical complexity of the kernels as a feature to achieve higher accuracy. These models are compact to reduce training time and fast inference during compile-time and run-time. Using models with less than 75 parameters, and only 250 training data instances, we are able to obtain a low MAPE of ~13% significantly outperforming traditional feed-forward neural networks on 40 kernel-variant-hardware combinations. We further demonstrate that our variant selection approach can be used in Halide implementations to obtain up to 1.5x speedup over Halide's autoscheduler.