 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTabConv: Low-Computation CNN Inference via Table Lookups
Apr 08, 2024Convolutional Neural Networks (CNNs) have demonstrated remarkable ability throughout the field of computer vision. However, CNN inference requires a large number of arithmetic operations, making them expensive to deploy in hardware. Current approaches alleviate this issue by developing hardware-supported, algorithmic processes to simplify spatial convolution functions. However, these methods still heavily rely on matrix multiplication, leading to significant computational overhead. To bridge the gap between hardware, algorithmic acceleration, and approximate matrix multiplication, we propose TabConv, a novel, table-based approximation for convolution to significantly reduce arithmetic operations during inference. Additionally, we introduce a priority masking technique based on cosine similarity to select layers for table-based approximation, thereby maintaining the model performance. We evaluate our approach on popular CNNs: ResNet-18, ResNet-34, and NetworkInNetwork (NIN). TabConv preserves over 93% of the original model's performance while reducing arithmetic operations by 36.5%, 25.8%, and 99.4% for ResNet-18 on CIFAR-10, CIFAR-100, and MNIST, respectively, 35.6% and 99.3% for ResNet-34 on CIFAR-10 and MNIST, and 98.9% for NIN on MNIST, achieving low-computation inference.
PaCKD: Pattern-Clustered Knowledge Distillation for Compressing Memory Access Prediction Models
Feb 21, 2024



Deep neural networks (DNNs) have proven to be effective models for accurate Memory Access Prediction (MAP), a critical task in mitigating memory latency through data prefetching. However, existing DNN-based MAP models suffer from the challenges such as significant physical storage space and poor inference latency, primarily due to their large number of parameters. These limitations render them impractical for deployment in real-world scenarios. In this paper, we propose PaCKD, a Pattern-Clustered Knowledge Distillation approach to compress MAP models while maintaining the prediction performance. The PaCKD approach encompasses three steps: clustering memory access sequences into distinct partitions involving similar patterns, training large pattern-specific teacher models for memory access prediction for each partition, and training a single lightweight student model by distilling the knowledge from the trained pattern-specific teachers. We evaluate our approach on LSTM, MLP-Mixer, and ResNet models, as they exhibit diverse structures and are widely used for image classification tasks in order to test their effectiveness in four widely used graph applications. Compared to the teacher models with 5.406M parameters and an F1-score of 0.4626, our student models achieve a 552$\times$ model size compression while maintaining an F1-score of 0.4538 (with a 1.92% performance drop). Our approach yields an 8.70% higher result compared to student models trained with standard knowledge distillation and an 8.88% higher result compared to student models trained without any form of knowledge distillation.
* 6 pages, 2 figures, HPEC '23
ME-ViT: A Single-Load Memory-Efficient FPGA Accelerator for Vision Transformers
Feb 15, 2024



Vision Transformers (ViTs) have emerged as a state-of-the-art solution for object classification tasks. However, their computational demands and high parameter count make them unsuitable for real-time inference, prompting the need for efficient hardware implementations. Existing hardware accelerators for ViTs suffer from frequent off-chip memory access, restricting the achievable throughput by memory bandwidth. In devices with a high compute-to-communication ratio (e.g., edge FPGAs with limited bandwidth), off-chip memory access imposes a severe bottleneck on overall throughput. This work proposes ME-ViT, a novel \underline{M}emory \underline{E}fficient FPGA accelerator for \underline{ViT} inference that minimizes memory traffic. We propose a \textit{single-load policy} in designing ME-ViT: model parameters are only loaded once, intermediate results are stored on-chip, and all operations are implemented in a single processing element. To achieve this goal, we design a memory-efficient processing element (ME-PE), which processes multiple key operations of ViT inference on the same architecture through the reuse of \textit{multi-purpose buffers}. We also integrate the Softmax and LayerNorm functions into the ME-PE, minimizing stalls between matrix multiplications. We evaluate ME-ViT on systolic array sizes of 32 and 16, achieving up to a 9.22$\times$ and 17.89$\times$ overall improvement in memory bandwidth, and a 2.16$\times$ improvement in throughput per DSP for both designs over state-of-the-art ViT accelerators on FPGA. ME-ViT achieves a power efficiency improvement of up to 4.00$\times$ (1.03$\times$) over a GPU (FPGA) baseline. ME-ViT enables up to 5 ME-PE instantiations on a Xilinx Alveo U200, achieving a 5.10$\times$ improvement in throughput over the state-of-the art FPGA baseline, and a 5.85$\times$ (1.51$\times$) improvement in power efficiency over the GPU (FPGA) baseline.
Attention, Distillation, and Tabularization: Towards Practical Neural Network-Based Prefetching
Jan 16, 2024



Attention-based Neural Networks (NN) have demonstrated their effectiveness in accurate memory access prediction, an essential step in data prefetching. However, the substantial computational overheads associated with these models result in high inference latency, limiting their feasibility as practical prefetchers. To close the gap, we propose a new approach based on tabularization that significantly reduces model complexity and inference latency without sacrificing prediction accuracy. Our novel tabularization methodology takes as input a distilled, yet highly accurate attention-based model for memory access prediction and efficiently converts its expensive matrix multiplications into a hierarchy of fast table lookups. As an exemplar of the above approach, we develop DART, a prefetcher comprised of a simple hierarchy of tables. With a modest 0.09 drop in F1-score, DART reduces 99.99% of arithmetic operations from the large attention-based model and 91.83% from the distilled model. DART accelerates the large model inference by 170x and the distilled model by 9.4x. DART has comparable latency and storage costs as state-of-the-art rule-based prefetcher BO but surpasses it by 6.1% in IPC improvement. DART outperforms state-of-the-art NN-based prefetchers TransFetch by 33.1% and Voyager by 37.2% in terms of IPC improvement, primarily due to its low prefetching latency.
Phases, Modalities, Temporal and Spatial Locality: Domain Specific ML Prefetcher for Accelerating Graph Analytics
Dec 10, 2022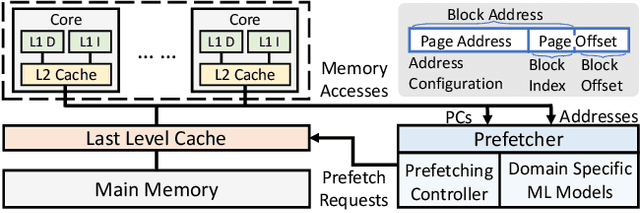
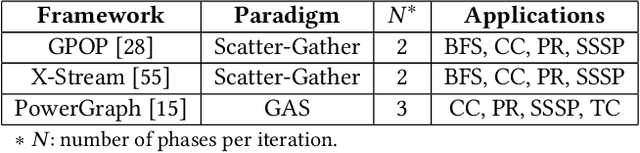
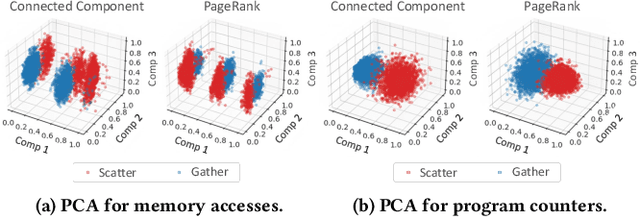
Graph processing applications are severely bottlenecked by memory system performance due to low data reuse and irregular memory accesses. While state-of-the-art prefetchers using Machine Learning (ML) have made great progress, they do not perform well on graph analytics applications due to phase transitions in the execution and irregular data access that is hard to predict. We propose MPGraph: a novel ML-based Prefetcher for Graph analytics. MPGraph makes three novel optimizations based on domain knowledge of graph analytics. It detects the transition of graph processing phases during execution using a novel soft detection technique, predicts memory accesses and pages using phase-specific multi-modality predictors, and prefetches using a novel chain spatio-temporal prefetching strategy. We evaluate our approach using three widely-used graph processing frameworks and a variety of graph datasets. Our approach achieves 34.17%-82.15% higher precision in phase transition detection than the KSWIN and decision tree baselines. Our predictors achieve 6.80%-16.02% higher F1-score for access prediction and 11.68%-15.41% higher accuracy-at-10 for page prediction compared with the baselines LSTM-based and vanilla attention-based models. Simulations show that MPGraph achieves on the average 87.16% (prefetch accuracy) and 73.29% (prefetch coverage), leading to 12.52%-21.23% IPC improvement. It outperforms the widely-used non-ML prefetcher BO by 7.58%-12.03%, and outperforms state-of-the-art ML-based prefetchers Voyager by 3.27%-4.42% and TransFetch by 3.73%-4.58% with respect to IPC improvement.
TransforMAP: Transformer for Memory Access Prediction
May 29, 2022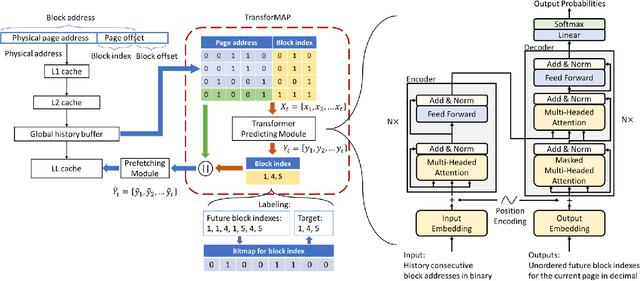
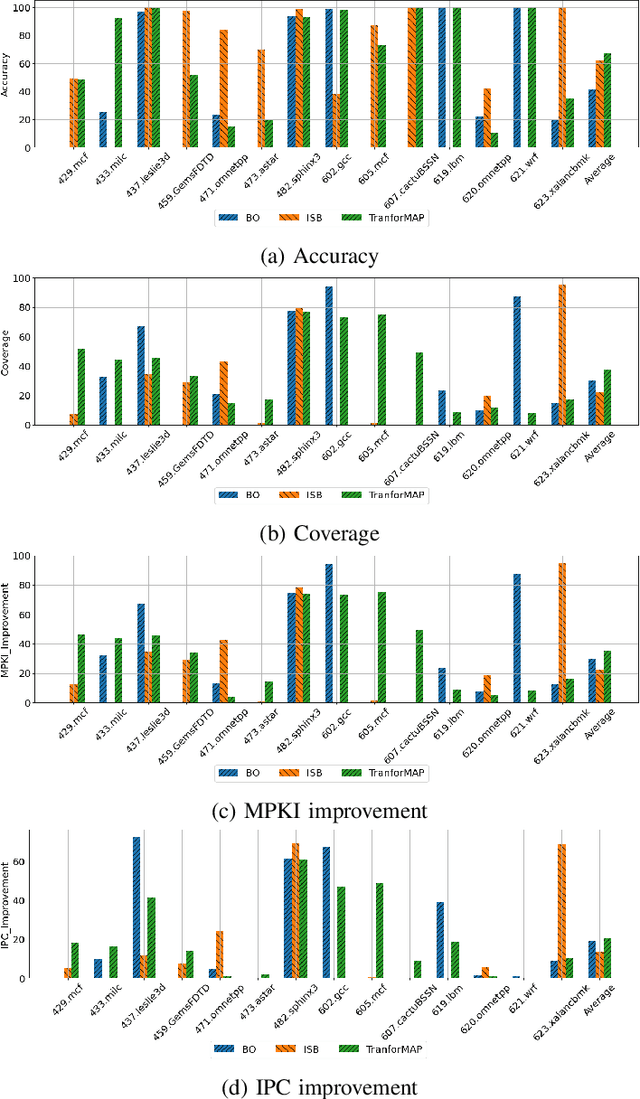
Data Prefetching is a technique that can hide memory latency by fetching data before it is needed by a program. Prefetching relies on accurate memory access prediction, to which task machine learning based methods are increasingly applied. Unlike previous approaches that learn from deltas or offsets and perform one access prediction, we develop TransforMAP, based on the powerful Transformer model, that can learn from the whole address space and perform multiple cache line predictions. We propose to use the binary of memory addresses as model input, which avoids information loss and saves a token table in hardware. We design a block index bitmap to collect unordered future page offsets under the current page address as learning labels. As a result, our model can learn temporal patterns as well as spatial patterns within a page. In a practical implementation, this approach has the potential to hide prediction latency because it prefetches multiple cache lines likely to be used in a long horizon. We show that our approach achieves 35.67% MPKI improvement and 20.55% IPC improvement in simulation, higher than state-of-the-art Best-Offset prefetcher and ISB prefetcher.
Fine-Grained Address Segmentation for Attention-Based Variable-Degree Prefetching
May 01, 2022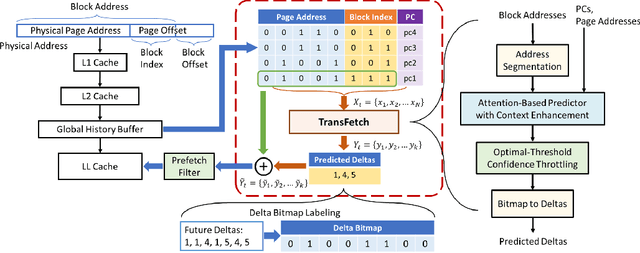
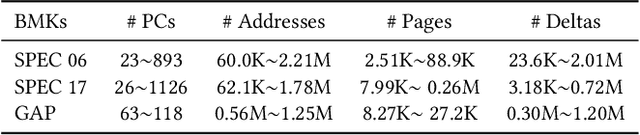
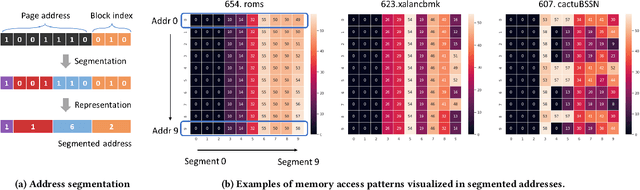
Machine learning algorithms have shown potential to improve prefetching performance by accurately predicting future memory accesses. Existing approaches are based on the modeling of text prediction, considering prefetching as a classification problem for sequence prediction. However, the vast and sparse memory address space leads to large vocabulary, which makes this modeling impractical. The number and order of outputs for multiple cache line prefetching are also fundamentally different from text prediction. We propose TransFetch, a novel way to model prefetching. To reduce vocabulary size, we use fine-grained address segmentation as input. To predict unordered sets of future addresses, we use delta bitmaps for multiple outputs. We apply an attention-based network to learn the mapping between input and output. Prediction experiments demonstrate that address segmentation achieves 26% - 36% higher F1-score than delta inputs and 15% - 24% higher F1-score than page & offset inputs for SPEC 2006, SPEC 2017, and GAP benchmarks. Simulation results show that TransFetch achieves 38.75% IPC improvement compared with no prefetching, outperforming the best-performing rule-based prefetcher BOP by 10.44%, and ML-based prefetcher Voyager by 6.64%.