 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards High Performance, Portability, and Productivity: Lightweight Augmented Neural Networks for Performance Prediction
Paper and Code

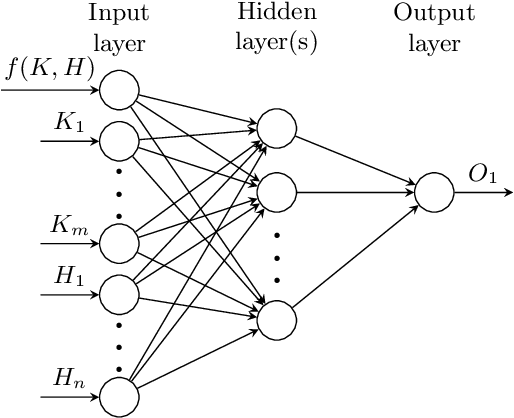
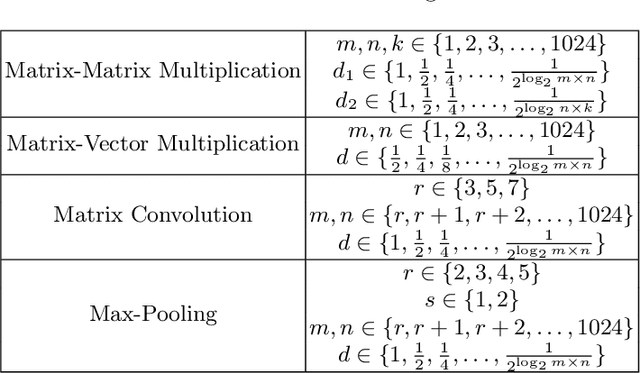
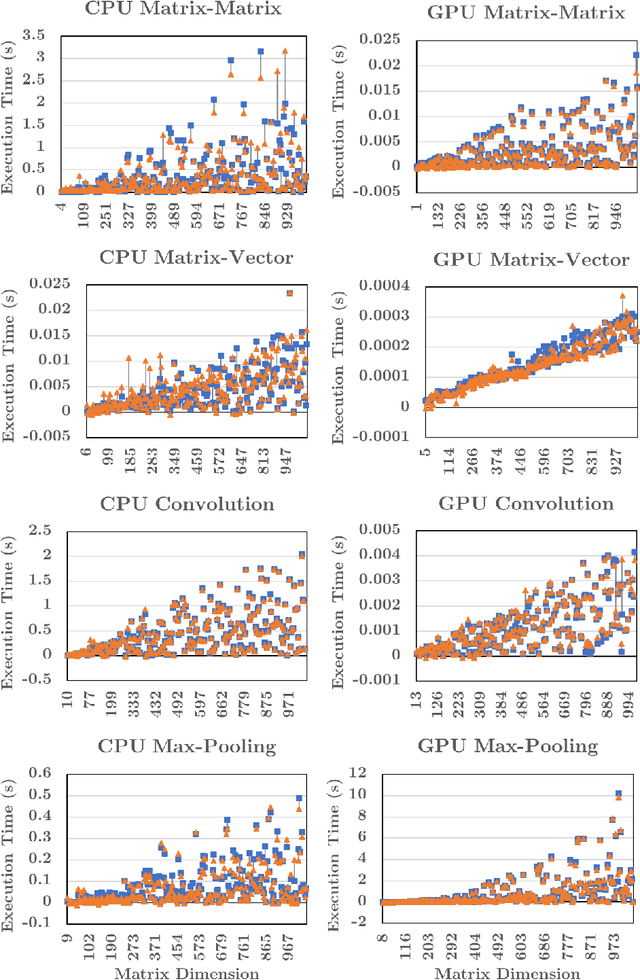
Writing high-performance code requires significant expertise of the programming language, compiler optimizations, and hardware knowledge. This often leads to poor productivity and portability and is inconvenient for a non-programmer domain-specialist such as a Physicist. More desirable is a high-level language where the domain-specialist simply specifies the workload in terms of high-level operations (e.g., matrix-multiply(A, B)) and the compiler identifies the best implementation fully utilizing the heterogeneous platform. For creating a compiler that supports productivity, portability, and performance simultaneously, it is crucial to predict performance of various available implementations (variants) of the dominant operations (kernels) contained in the workload on various hardware to decide (a) which variant should be chosen for each kernel in the workload, and (b) on which hardware resource the variant should run. To enable the performance prediction, we propose lightweight augmented neural networks for arbitrary combinations of kernel-variant-hardware. A key innovation is utilizing mathematical complexity of the kernels as a feature to achieve higher accuracy. These models are compact to reduce training time and fast inference during compile-time and run-time. Using models with less than 75 parameters, and only 250 training data instances, we are able to obtain a low MAPE of ~13% significantly outperforming traditional feed-forward neural networks on 40 kernel-variant-hardware combinations. We further demonstrate that our variant selection approach can be used in Halide implementations to obtain up to 1.5x speedup over Halide's autoscheduler.