 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredictive Modeling of Homeless Service Assignment: A Representation Learning Approach
Dec 10, 2024In recent years, there has been growing interest in leveraging machine learning for homeless service assignment. However, the categorical nature of administrative data recorded for homeless individuals hinders the development of accurate machine learning methods for this task. This work asserts that deriving latent representations of such features, while at the same time leveraging underlying relationships between instances is crucial in algorithmically enhancing the existing assignment decision-making process. Our proposed approach learns temporal and functional relationships between services from historical data, as well as unobserved but relevant relationships between individuals to generate features that significantly improve the prediction of the next service assignment compared to the state-of-the-art.
Dynamic Instance-Wise Classification in Correlated Feature Spaces
Jun 08, 2021

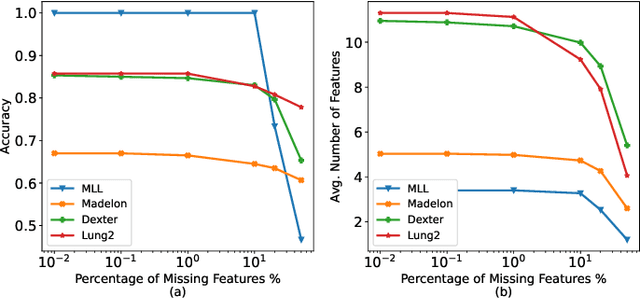
In a typical supervised machine learning setting, the predictions on all test instances are based on a common subset of features discovered during model training. However, using a different subset of features that is most informative for each test instance individually may not only improve prediction accuracy, but also the overall interpretability of the model. At the same time, feature selection methods for classification have been known to be the most effective when many features are irrelevant and/or uncorrelated. In fact, feature selection ignoring correlations between features can lead to poor classification performance. In this work, a Bayesian network is utilized to model feature dependencies. Using the dependency network, a new method is proposed that sequentially selects the best feature to evaluate for each test instance individually, and stops the selection process to make a prediction once it determines that no further improvement can be achieved with respect to classification accuracy. The optimum number of features to acquire and the optimum classification strategy are derived for each test instance. The theoretical properties of the optimum solution are analyzed, and a new algorithm is proposed that takes advantage of these properties to implement a robust and scalable solution for high dimensional settings. The effectiveness, generalizability, and scalability of the proposed method is illustrated on a variety of real-world datasets from diverse application domains.
On-the-Fly Joint Feature Selection and Classification
Apr 21, 2020



Joint feature selection and classification in an online setting is essential for time-sensitive decision making. However, most existing methods treat this coupled problem independently. Specifically, online feature selection methods can handle either streaming features or data instances offline to produce a fixed set of features for classification, while online classification methods classify incoming instances using full knowledge about the feature space. Nevertheless, all existing methods utilize a set of features, common for all data instances, for classification. Instead, we propose a framework to perform joint feature selection and classification on-the-fly, so as to minimize the number of features evaluated for every data instance and maximize classification accuracy. We derive the optimum solution of the associated optimization problem and analyze its structure. Two algorithms are proposed, ETANA and F-ETANA, which are based on the optimum solution and its properties. We evaluate the performance of the proposed algorithms on several public datasets, demonstrating (i) the dominance of the proposed algorithms over the state-of-the-art, and (ii) its applicability to broad range of application domains including clinical research and natural language processing.
Not all Embeddings are created Equal: Extracting Entity-specific Substructures for RDF Graph Embedding
Apr 14, 2018



Knowledge Graphs (KGs) are becoming essential to information systems that require access to structured data. Several approaches have been recently proposed, for obtaining vector representations of KGs suitable for Machine Learning tasks, based on identifying and extracting relevant graph substructures using uniform and biased random walks. However, such approaches lead to representations comprising mostly "popular", instead of "relevant", entities in the KG. In KGs, in which different types of entities often exist (such as in Linked Open Data), a given target entity may have its own distinct set of most "relevant" nodes and edges. We propose specificity as an accurate measure of identifying most relevant, entity-specific, nodes and edges. We develop a scalable method based on bidirectional random walks to compute specificity. Our experimental evaluation results show that specificity-based biased random walks extract more "meaningful" (in terms of size and relevance) RDF substructures compared to the state-of-the-art and, the graph embedding learned from the extracted substructures, outperform existing techniques in the task of entity recommendation in DBpedia.