 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCertificate-Guided Evaluation of Reinforcement Learning Generalization
May 30, 2026This work presents a logic-driven framework to evaluate the performance of reinforcement learning (RL) algorithms in their ability to generalize to unseen tasks. Our framework defines a family of inductive reach-avoid tasks, characterized by structural similarities in task dynamics, enabling evaluation of generalization capabilities. We introduce a neural certificate function that validates trajectories generated by RL algorithms by enforcing key conditions, thereby serving as a litmus test for RL generalization. We empirically demonstrate our method's capability in certifying generalization for several state-of-the-art generalizable RL algorithms on challenging continuous environments. Our results show that a lower percentage of certificate function violations correlates with a higher number of test tasks successfully solved, highlighting the effectiveness of our framework in evaluating and distinguishing generalization capabilities of RL algorithms. This work provides a principled approach for benchmarking RL generalization.
Decoupled Behavioral Cloning for Scalable Inductive Generalization in RL from Specifications
May 30, 2026Inductive generalization is a framework for reinforcement learning (RL) generalization in which inductively related task instances admit inductively related policies. Prior work captures this structure via a higher-order policy-evolution function learned directly with RL, but suffers from poor training scalability: as training tasks grow, aggregated reward feedback becomes noisy and conflicting, destabilizing training and weakening generalization. We propose DIBS, a decoupled behavioral cloning approach that separates learning task-specific policies from learning the evolution function. We first learn individual teacher policies per task via standard RL, then fit the evolution function via behavioral cloning on teacher-labeled state-action pairs. This replaces noisy reward aggregation with dense, stable supervision. DIBS achieves significant improvements in both training stability and zero-shot generalization against existing RL and meta-RL algorithms.
Inductive Generalization in Reinforcement Learning from Specifications
Jun 05, 2024We present a novel inductive generalization framework for RL from logical specifications. Many interesting tasks in RL environments have a natural inductive structure. These inductive tasks have similar overarching goals but they differ inductively in low-level predicates and distributions. We present a generalization procedure that leverages this inductive relationship to learn a higher-order function, a policy generator, that generates appropriately adapted policies for instances of an inductive task in a zero-shot manner. An evaluation of the proposed approach on a set of challenging control benchmarks demonstrates the promise of our framework in generalizing to unseen policies for long-horizon tasks.
Generalization for multiclass classification with overparameterized linear models
Jun 03, 2022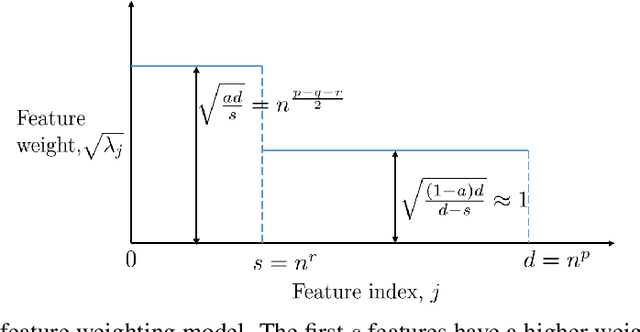
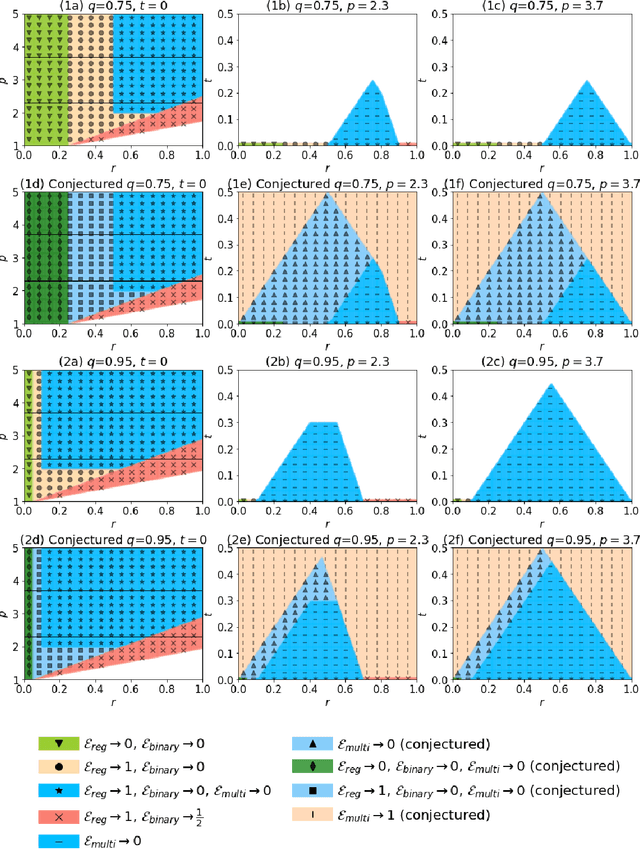
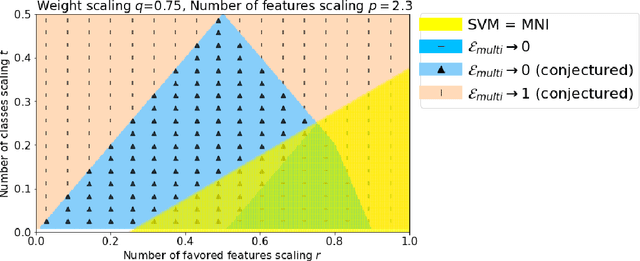
Via an overparameterized linear model with Gaussian features, we provide conditions for good generalization for multiclass classification of minimum-norm interpolating solutions in an asymptotic setting where both the number of underlying features and the number of classes scale with the number of training points. The survival/contamination analysis framework for understanding the behavior of overparameterized learning problems is adapted to this setting, revealing that multiclass classification qualitatively behaves like binary classification in that, as long as there are not too many classes (made precise in the paper), it is possible to generalize well even in some settings where the corresponding regression tasks would not generalize. Besides various technical challenges, it turns out that the key difference from the binary classification setting is that there are relatively fewer positive training examples of each class in the multiclass setting as the number of classes increases, making the multiclass problem "harder" than the binary one.
Classification vs regression in overparameterized regimes: Does the loss function matter?
May 16, 2020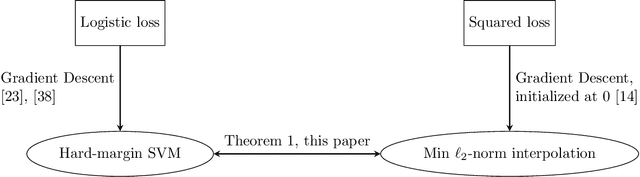
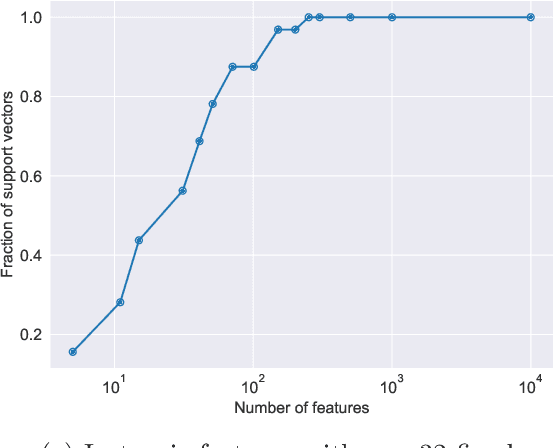
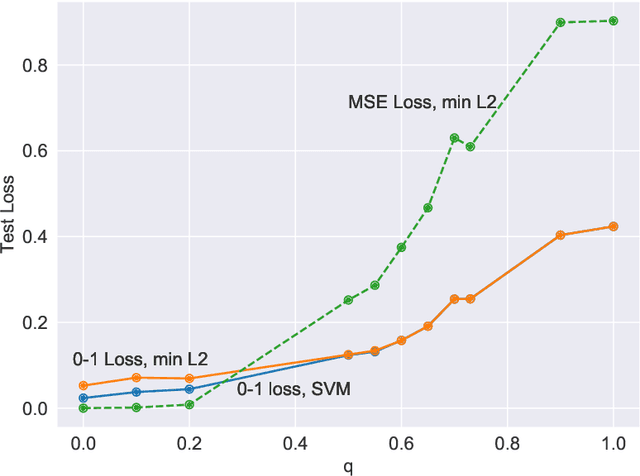
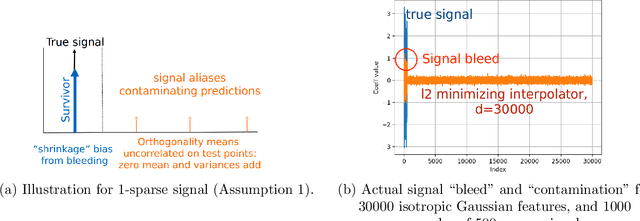
We compare classification and regression tasks in the overparameterized linear model with Gaussian features. On the one hand, we show that with sufficient overparameterization all training points are support vectors: solutions obtained by least-squares minimum-norm interpolation, typically used for regression, are identical to those produced by the hard-margin support vector machine (SVM) that minimizes the hinge loss, typically used for training classifiers. On the other hand, we show that there exist regimes where these solutions are near-optimal when evaluated by the 0-1 test loss function, but do not generalize if evaluated by the square loss function, i.e. they achieve the null risk. Our results demonstrate the very different roles and properties of loss functions used at the training phase (optimization) and the testing phase (generalization).