 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProgressive Sparse Local Attention for Video object detection
Mar 25, 2019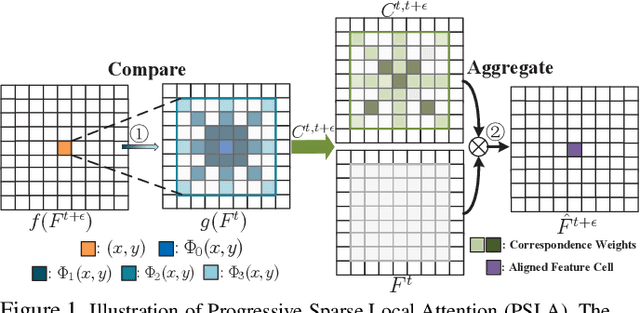
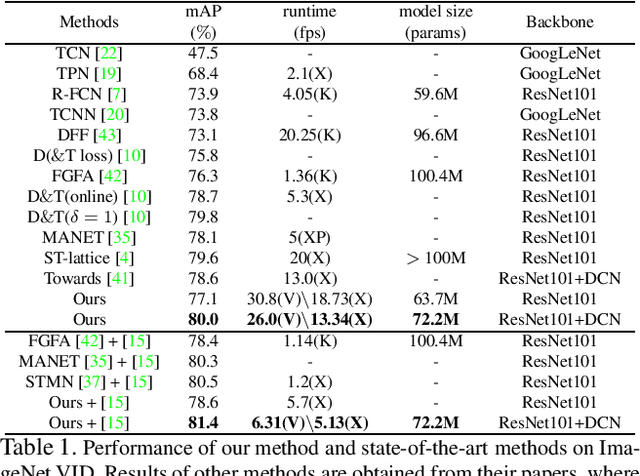
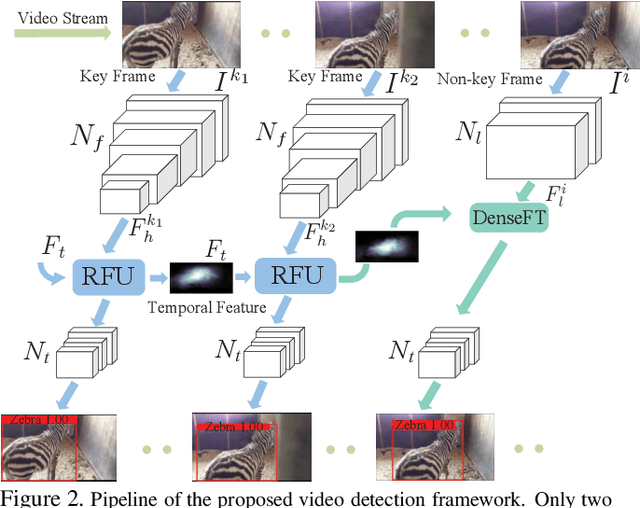
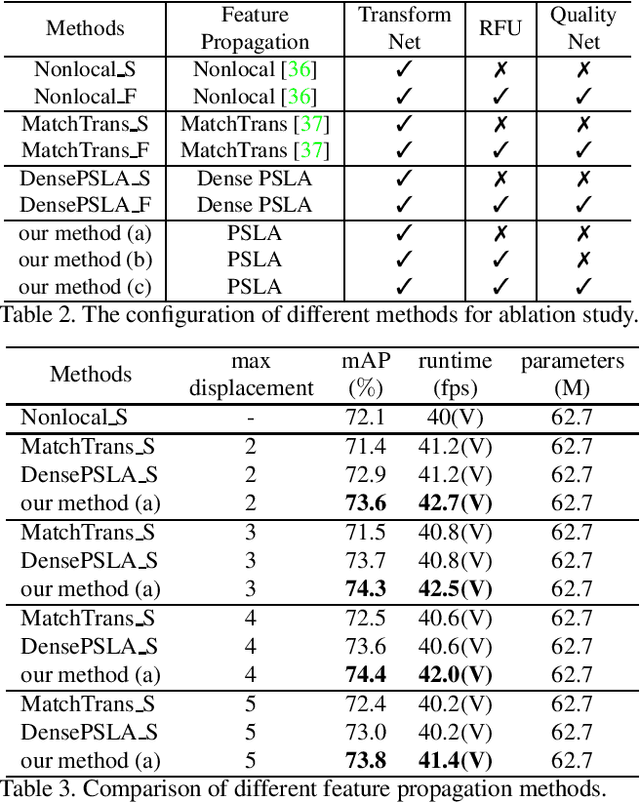
Transferring image-based object detectors to the domain of videos remains a challenging problem. Previous efforts mostly exploit optical flow to propagate features across frames, aiming to achieve a good trade-off between accuracy and efficiency. However, introducing an extra model to estimate optical flow would significantly increase the overall model size. The gap between optical flow and high-level features can also hinder it from establishing spatial correspondence accurately. Instead of relying on optical flow, this paper proposes a novel module called Progressive Sparse Local Attention (PSLA), which establishes the spatial correspondence between features across frames in a local region with progressive sparser stride and uses the correspondence to propagate features. Based on PSLA, Recursive Feature Updating (RFU) and Dense Feature Transforming (DFT) are proposed to model temporal appearance and enrich feature representation respectively in a novel video object detection framework. Experiments on ImageNet VID show that our method achieves the best accuracy compared to existing methods with smaller model size and acceptable runtime speed.
Motion Selective Prediction for Video Frame Synthesis
Dec 25, 2018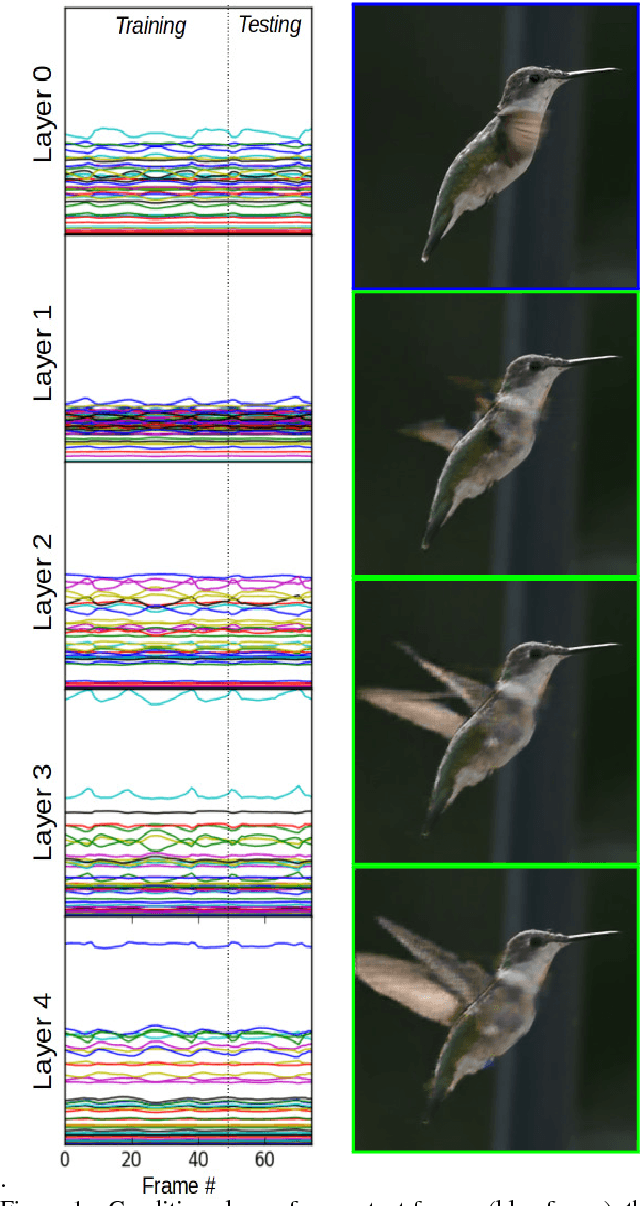
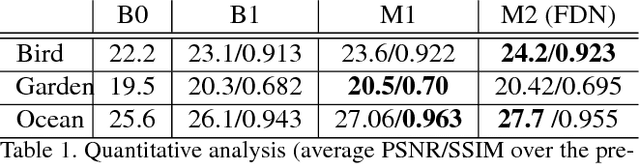


Existing conditional video prediction approaches train a network from large databases and generalize to previously unseen data. We take the opposite stance, and introduce a model that learns from the first frames of a given video and extends its content and motion, to, eg, double its length. To this end, we propose a dual network that can use in a flexible way both dynamic and static convolutional motion kernels, to predict future frames. The construct of our model gives us the the means to efficiently analyze its functioning and interpret its output. We demonstrate experimentally the robustness of our approach on challenging videos in-the-wild and show that it is competitive wrt related baselines.