 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStreaMRAK a Streaming Multi-Resolution Adaptive Kernel Algorithm
Sep 07, 2021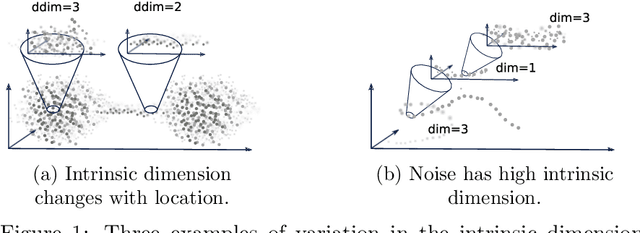
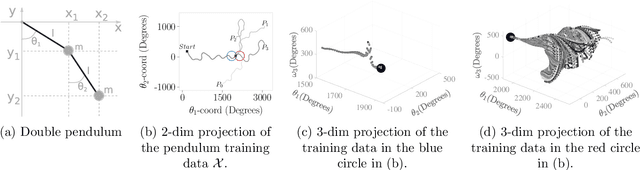

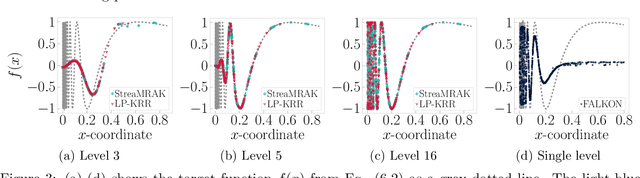
Kernel ridge regression (KRR) is a popular scheme for non-linear non-parametric learning. However, existing implementations of KRR require that all the data is stored in the main memory, which severely limits the use of KRR in contexts where data size far exceeds the memory size. Such applications are increasingly common in data mining, bioinformatics, and control. A powerful paradigm for computing on data sets that are too large for memory is the streaming model of computation, where we process one data sample at a time, discarding each sample before moving on to the next one. In this paper, we propose StreaMRAK - a streaming version of KRR. StreaMRAK improves on existing KRR schemes by dividing the problem into several levels of resolution, which allows continual refinement to the predictions. The algorithm reduces the memory requirement by continuously and efficiently integrating new samples into the training model. With a novel sub-sampling scheme, StreaMRAK reduces memory and computational complexities by creating a sketch of the original data, where the sub-sampling density is adapted to the bandwidth of the kernel and the local dimensionality of the data. We present a showcase study on two synthetic problems and the prediction of the trajectory of a double pendulum. The results show that the proposed algorithm is fast and accurate.
Nonlinear generalization of the single index model
Feb 24, 2019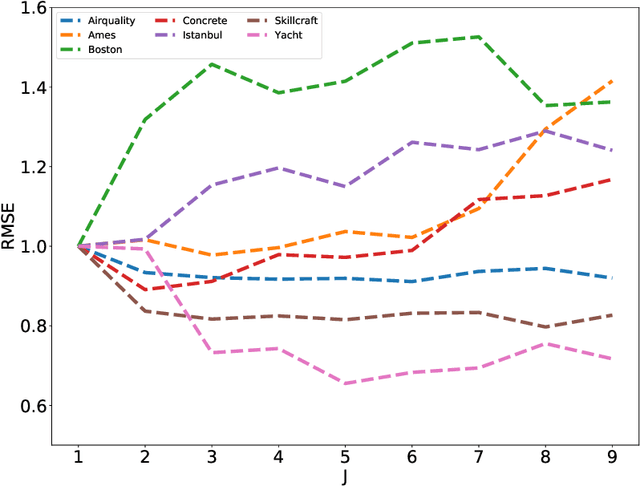

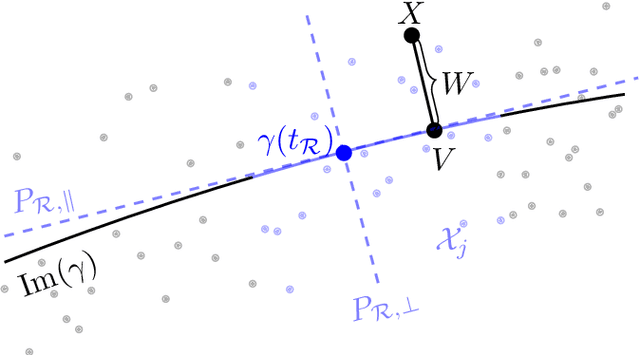

Single index model is a powerful yet simple model, widely used in statistics, machine learning, and other scientific fields. It models the regression function as $g(<a,x>)$, where a is an unknown index vector and x are the features. This paper deals with a nonlinear generalization of this framework to allow for a regressor that uses multiple index vectors, adapting to local changes in the responses. To do so we exploit the conditional distribution over function-driven partitions, and use linear regression to locally estimate index vectors. We then regress by applying a kNN type estimator that uses a localized proxy of the geodesic metric. We present theoretical guarantees for estimation of local index vectors and out-of-sample prediction, and demonstrate the performance of our method with experiments on synthetic and real-world data sets, comparing it with state-of-the-art methods.
Adaptive multi-penalty regularization based on a generalized Lasso path
Oct 11, 2017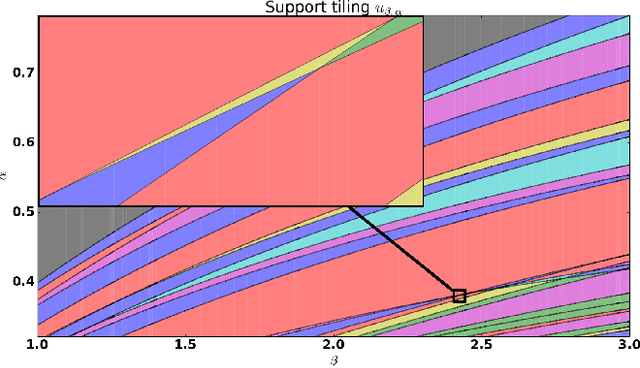
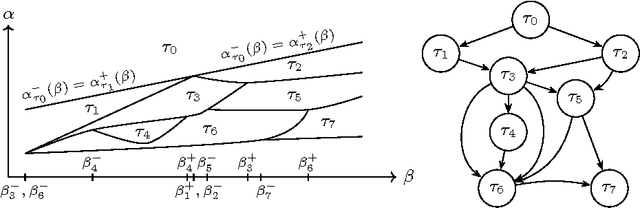
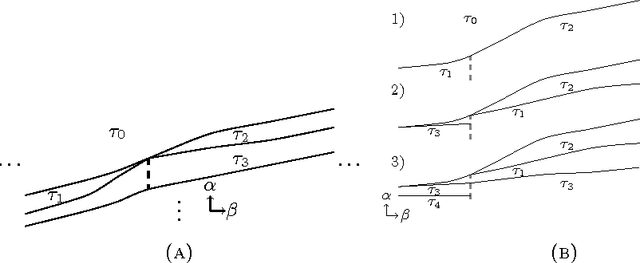
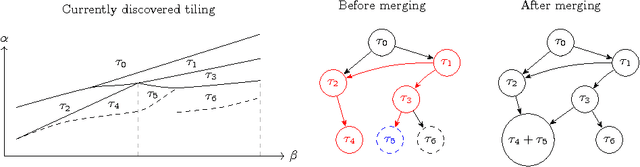
For many algorithms, parameter tuning remains a challenging and critical task, which becomes tedious and infeasible in a multi-parameter setting. Multi-penalty regularization, successfully used for solving undetermined sparse regression of problems of unmixing type where signal and noise are additively mixed, is one of such examples. In this paper, we propose a novel algorithmic framework for an adaptive parameter choice in multi-penalty regularization with a focus on the correct support recovery. Building upon the theory of regularization paths and algorithms for single-penalty functionals, we extend these ideas to a multi-penalty framework by providing an efficient procedure for the construction of regions containing structurally similar solutions, i.e., solutions with the same sparsity and sign pattern, over the whole range of parameters. Combining this with a model selection criterion, we can choose regularization parameters in a data-adaptive manner. Another advantage of our algorithm is that it provides an overview on the solution stability over the whole range of parameters. This can be further exploited to obtain additional insights into the problem of interest. We provide a numerical analysis of our method and compare it to the state-of-the-art single-penalty algorithms for compressed sensing problems in order to demonstrate the robustness and power of the proposed algorithm.
Dictionary Learning from Incomplete Data
Jan 19, 2017
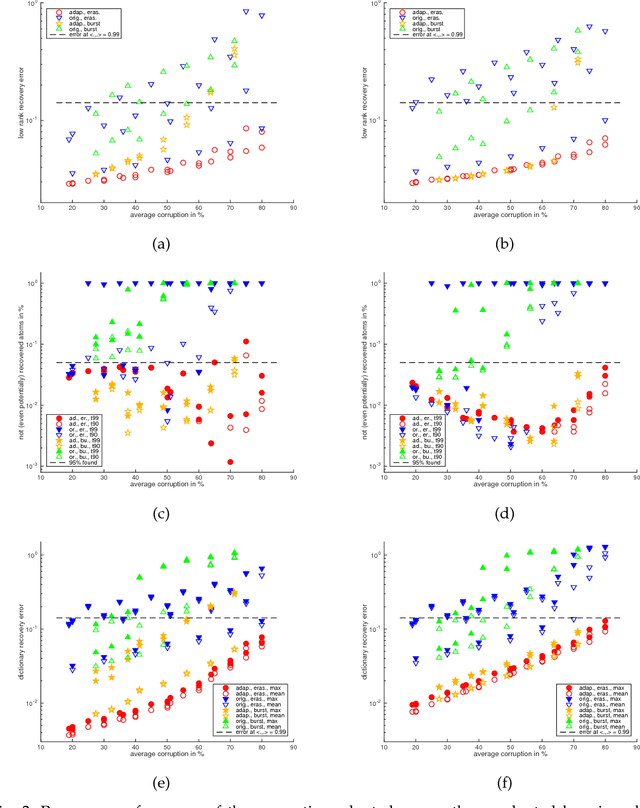
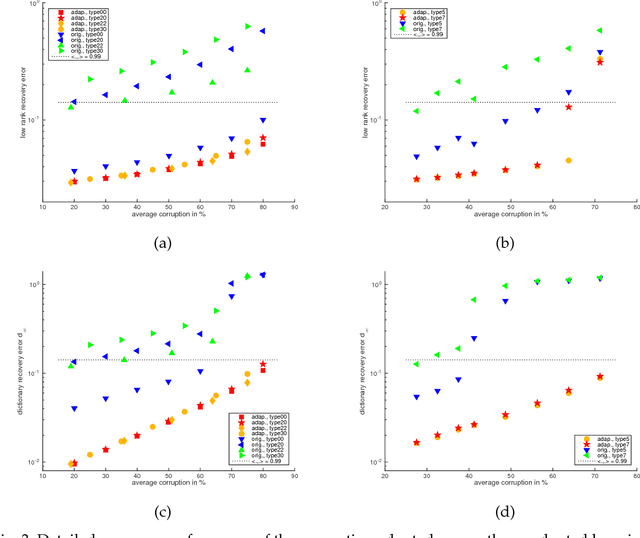

This paper extends the recently proposed and theoretically justified iterative thresholding and $K$ residual means algorithm ITKrM to learning dicionaries from incomplete/masked training data (ITKrMM). It further adapts the algorithm to the presence of a low rank component in the data and provides a strategy for recovering this low rank component again from incomplete data. Several synthetic experiments show the advantages of incorporating information about the corruption into the algorithm. Finally, image inpainting is considered as application example, which demonstrates the superior performance of ITKrMM in terms of speed at similar or better reconstruction quality compared to its closest dictionary learning counterpart.