 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCooperation and Exploitation in LLM Policy Synthesis for Sequential Social Dilemmas
Mar 19, 2026We study LLM policy synthesis: using a large language model to iteratively generate programmatic agent policies for multi-agent environments. Rather than training neural policies via reinforcement learning, our framework prompts an LLM to produce Python policy functions, evaluates them in self-play, and refines them using performance feedback across iterations. We investigate feedback engineering (the design of what evaluation information is shown to the LLM during refinement) comparing sparse feedback (scalar reward only) against dense feedback (reward plus social metrics: efficiency, equality, sustainability, peace). Across two canonical Sequential Social Dilemmas (Gathering and Cleanup) and two frontier LLMs (Claude Sonnet 4.6, Gemini 3.1 Pro), dense feedback consistently matches or exceeds sparse feedback on all metrics. The advantage is largest in the Cleanup public goods game, where providing social metrics helps the LLM calibrate the costly cleaning-harvesting tradeoff. Rather than triggering over-optimization of fairness, social metrics serve as a coordination signal that guides the LLM toward more effective cooperative strategies, including territory partitioning, adaptive role assignment, and the avoidance of wasteful aggression. We further perform an adversarial experiment to determine whether LLMs can reward hack these environments. We characterize five attack classes and discuss mitigations, highlighting an inherent tension in LLM policy synthesis between expressiveness and safety. Code at https://github.com/vicgalle/llm-policies-social-dilemmas.
Distilling Feedback into Memory-as-a-Tool
Jan 09, 2026We propose a framework that amortizes the cost of inference-time reasoning by converting transient critiques into retrievable guidelines, through a file-based memory system and agent-controlled tool calls. We evaluate this method on the Rubric Feedback Bench, a novel dataset for rubric-based learning. Experiments demonstrate that our augmented LLMs rapidly match the performance of test-time refinement pipelines while drastically reducing inference cost.
Configurable Preference Tuning with Rubric-Guided Synthetic Data
Jun 13, 2025



Models of human feedback for AI alignment, such as those underpinning Direct Preference Optimization (DPO), often bake in a singular, static set of preferences, limiting adaptability. This paper challenges the assumption of monolithic preferences by introducing Configurable Preference Tuning (CPT), a novel framework for endowing language models with the ability to dynamically adjust their behavior based on explicit, human-interpretable directives. CPT leverages synthetically generated preference data, conditioned on system prompts derived from structured, fine-grained rubrics that define desired attributes like writing style. By fine-tuning with these rubric-guided preferences, the LLM learns to modulate its outputs at inference time in response to the system prompt, without retraining. This approach not only offers fine-grained control but also provides a mechanism for modeling more nuanced and context-dependent human feedback. Several experimental artifacts, such as training code, generated datasets and fine-tuned models are released at https://github.com/vicgalle/configurable-preference-tuning
MetaSC: Test-Time Safety Specification Optimization for Language Models
Feb 11, 2025We propose a novel dynamic safety framework that optimizes language model (LM) safety reasoning at inference time without modifying model weights. Building on recent advances in self-critique methods, our approach leverages a meta-critique mechanism that iteratively updates safety prompts-termed specifications-to drive the critique and revision process adaptively. This test-time optimization not only improves performance against adversarial jailbreak requests but also in diverse general safety-related tasks, such as avoiding moral harm or pursuing honest responses. Our empirical evaluations across several language models demonstrate that dynamically optimized safety prompts yield significantly higher safety scores compared to fixed system prompts and static self-critique defenses. Code to be released at https://github.com/vicgalle/meta-self-critique.git .
Refined Direct Preference Optimization with Synthetic Data for Behavioral Alignment of LLMs
Feb 12, 2024In this paper, we introduce \emph{refined Direct Preference Optimization} (rDPO), a method for improving the behavioral alignment of Large Language Models (LLMs) without the need for human-annotated data. The method involves creating synthetic data using self-critique prompting by a teacher LLM and then utilising a generalized DPO loss function to distil to a student LLM. The loss function incorporates an additional external reward model to improve the quality of synthetic data, making rDPO robust to potential noise in the synthetic dataset. rDPO is shown to be effective in a diverse set of behavioural alignment tasks, such as improved safety, robustness against role-playing, and reduced sycophancy. Code to be released at https://github.com/vicgalle/refined-dpo.
How do tuna schools associate to dFADs? A study using echo-sounder buoys to identify global patterns
Jul 14, 2022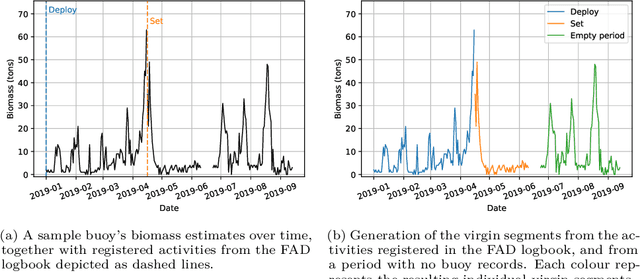
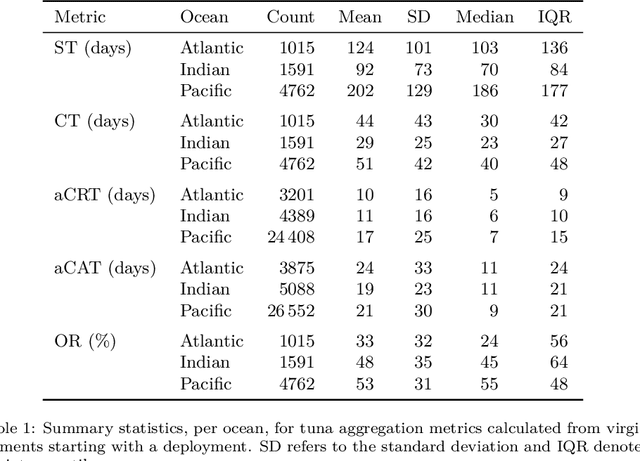


Based on the data gathered by echo-sounder buoys attached to drifting Fish Aggregating Devices (dFADs) across tropical oceans, the current study applies a Machine Learning protocol to examine the temporal trends of tuna schools' association to drifting objects. Using a binary output, metrics typically used in the literature were adapted to account for the fact that the entire tuna aggregation under the dFAD was considered. The median time it took tuna to colonize the dFADs for the first time varied between 25 and 43 days, depending on the ocean, and the longest soak and colonization times were registered in the Pacific Ocean. The tuna schools' Continuous Residence Times were generally shorter than Continuous Absence Times (median values between 5 and 7 days, and 9 and 11 days, respectively), in line with the results found by previous studies. Using a regression output, two novel metrics, namely aggregation time and disaggregation time, were estimated to obtain further insight into the symmetry of the aggregation process. Across all oceans, the time it took for the tuna aggregation to depart from the dFADs was not significantly longer than the time it took for the aggregation to form. The value of these results in the context of the "ecological trap" hypothesis is discussed, and further analyses to enrich and make use of this data source are proposed.
Contributions to Large Scale Bayesian Inference and Adversarial Machine Learning
Sep 25, 2021

The rampant adoption of ML methodologies has revealed that models are usually adopted to make decisions without taking into account the uncertainties in their predictions. More critically, they can be vulnerable to adversarial examples. Thus, we believe that developing ML systems that take into account predictive uncertainties and are robust against adversarial examples is a must for critical, real-world tasks. We start with a case study in retailing. We propose a robust implementation of the Nerlove-Arrow model using a Bayesian structural time series model. Its Bayesian nature facilitates incorporating prior information reflecting the manager's views, which can be updated with relevant data. However, this case adopted classical Bayesian techniques, such as the Gibbs sampler. Nowadays, the ML landscape is pervaded with neural networks and this chapter also surveys current developments in this sub-field. Then, we tackle the problem of scaling Bayesian inference to complex models and large data regimes. In the first part, we propose a unifying view of two different Bayesian inference algorithms, Stochastic Gradient Markov Chain Monte Carlo (SG-MCMC) and Stein Variational Gradient Descent (SVGD), leading to improved and efficient novel sampling schemes. In the second part, we develop a framework to boost the efficiency of Bayesian inference in probabilistic models by embedding a Markov chain sampler within a variational posterior approximation. After that, we present an alternative perspective on adversarial classification based on adversarial risk analysis, and leveraging the scalable Bayesian approaches from chapter 2. In chapter 4 we turn to reinforcement learning, introducing Threatened Markov Decision Processes, showing the benefits of accounting for adversaries in RL while the agent learns.
Data sharing games
Jan 26, 2021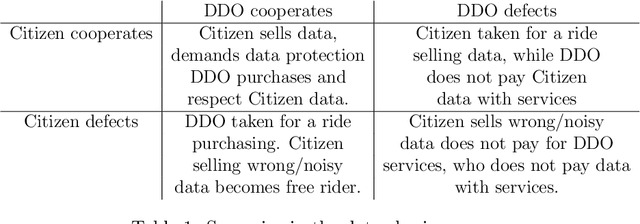
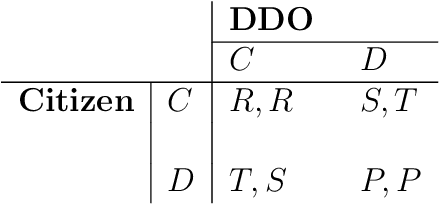
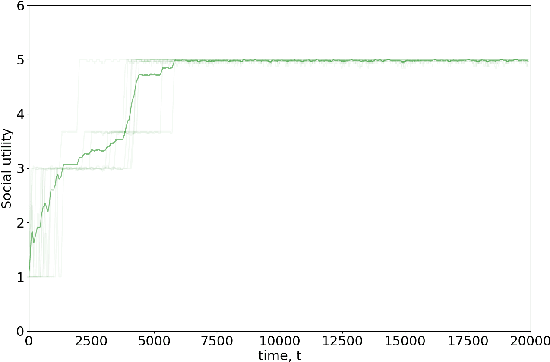
Data sharing issues pervade online social and economic environments. To foster social progress, it is important to develop models of the interaction between data producers and consumers that can promote the rise of cooperation between the involved parties. We formalize this interaction as a game, the data sharing game, based on the Iterated Prisoner's Dilemma and deal with it through multi-agent reinforcement learning techniques. We consider several strategies for how the citizens may behave, depending on the degree of centralization sought. Simulations suggest mechanisms for cooperation to take place and, thus, achieve maximum social utility: data consumers should perform some kind of opponent modeling, or a regulator should transfer utility between both players and incentivise them.
Reinforcement Learning under Threats
Sep 05, 2018


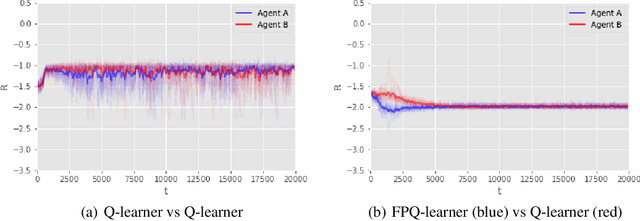
In several reinforcement learning (RL) scenarios, mainly in security settings, there may be adversaries trying to interfere with the reward generating process. In this paper, we introduce Threatened Markov Decision Processes (TMDPs), which provide a framework to support a decision maker against a potential adversary in RL. Furthermore, we propose a level-$k$ thinking scheme resulting in a new learning framework to deal with TMDPs. After introducing our framework and deriving theoretical results, relevant empirical evidence is given via extensive experiments, showing the benefits of accounting for adversaries while the agent learns.
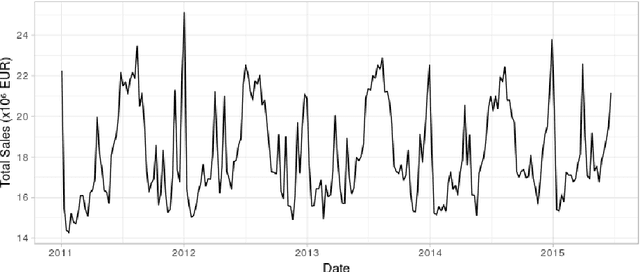
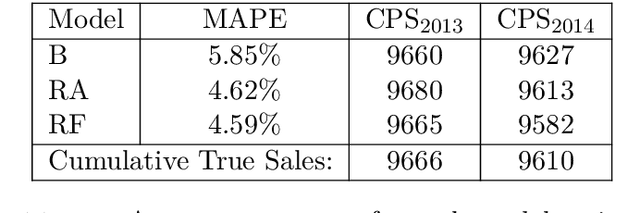
Assessing the effect of advertising expenditures upon sales: a Bayesian structural time series model
Apr 23, 2018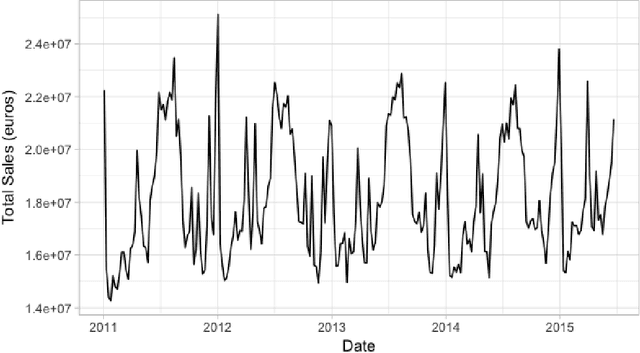
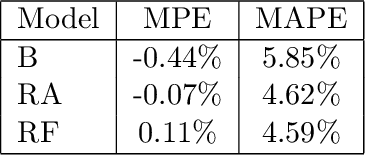
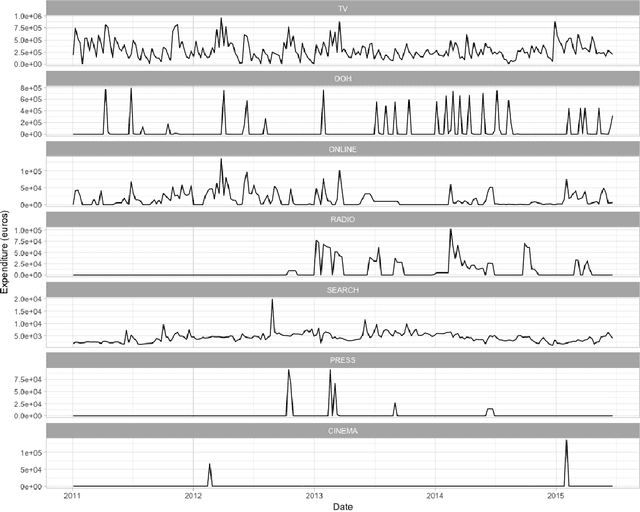
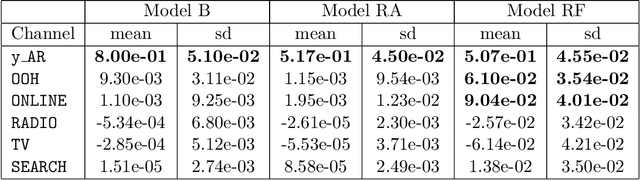
We propose a robust implementation of the Nerlove--Arrow model using a Bayesian structural time series model to explain the relationship between advertising expenditures of a country-wide fast-food franchise network with its weekly sales. Thanks to the flexibility and modularity of the model, it is well suited to generalization to other markets or situations. Its Bayesian nature facilitates incorporating \emph{a priori} information (the manager's views), which can be updated with relevant data. This aspect of the model will be used to present a strategy of budget scheduling across time and channels.