 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow do tuna schools associate to dFADs? A study using echo-sounder buoys to identify global patterns
Jul 14, 2022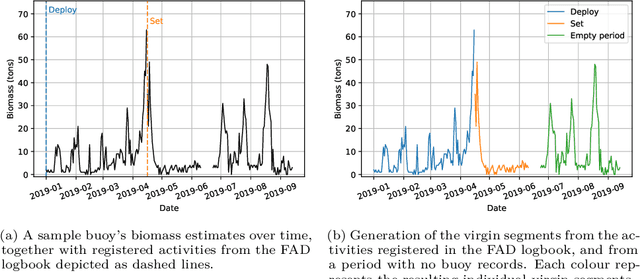
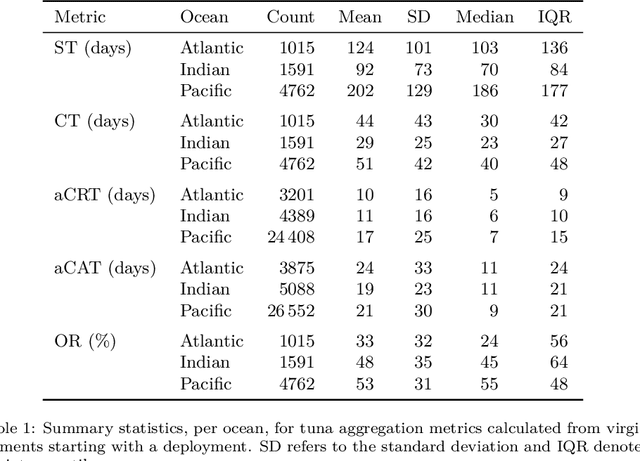


Based on the data gathered by echo-sounder buoys attached to drifting Fish Aggregating Devices (dFADs) across tropical oceans, the current study applies a Machine Learning protocol to examine the temporal trends of tuna schools' association to drifting objects. Using a binary output, metrics typically used in the literature were adapted to account for the fact that the entire tuna aggregation under the dFAD was considered. The median time it took tuna to colonize the dFADs for the first time varied between 25 and 43 days, depending on the ocean, and the longest soak and colonization times were registered in the Pacific Ocean. The tuna schools' Continuous Residence Times were generally shorter than Continuous Absence Times (median values between 5 and 7 days, and 9 and 11 days, respectively), in line with the results found by previous studies. Using a regression output, two novel metrics, namely aggregation time and disaggregation time, were estimated to obtain further insight into the symmetry of the aggregation process. Across all oceans, the time it took for the tuna aggregation to depart from the dFADs was not significantly longer than the time it took for the aggregation to form. The value of these results in the context of the "ecological trap" hypothesis is discussed, and further analyses to enrich and make use of this data source are proposed.
Tuna-AI: tuna biomass estimation with Machine Learning models trained on oceanography and echosounder FAD data
Sep 29, 2021Echo-sounder data registered by buoys attached to drifting FADs provide a very valuable source of information on populations of tuna and their behaviour. This value increases whenthese data are supplemented with oceanographic data coming from CMEMS. We use these sources to develop Tuna-AI, a Machine Learning model aimed at predicting tuna biomass under a given buoy, which uses a 3-day window of echo-sounder data to capture the daily spatio-temporal patterns characteristic of tuna schools. As the supervised signal for training, we employ more than 5000 set events with their corresponding tuna catch reported by the AGAC tuna purse seine fleet.
Faster SVM Training via Conjugate SMO
Mar 19, 2020
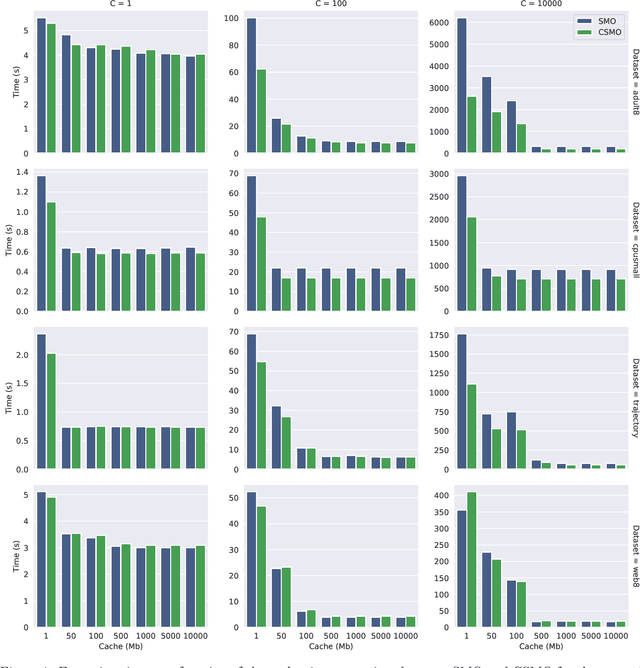
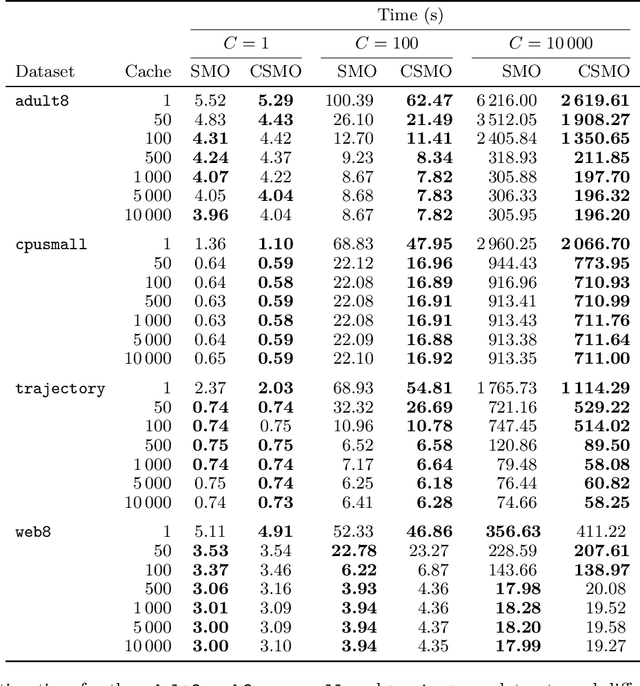
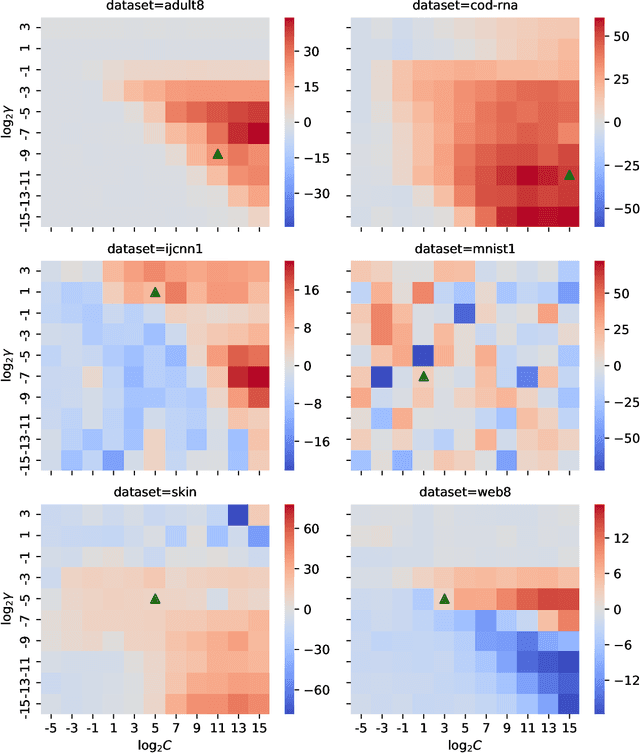
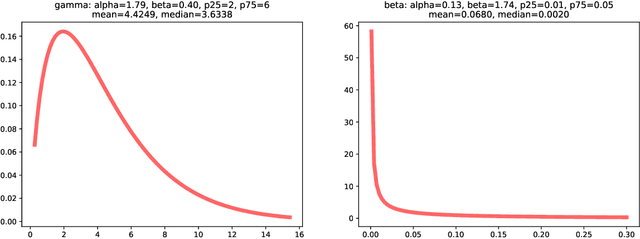
We propose an improved version of the SMO algorithm for training classification and regression SVMs, based on a Conjugate Descent procedure. This new approach only involves a modest increase on the computational cost of each iteration but, in turn, usually results in a substantial decrease in the number of iterations required to converge to a given precision. Besides, we prove convergence of the iterates of this new Conjugate SMO as well as a linear rate when the kernel matrix is positive definite. We have implemented Conjugate SMO within the LIBSVM library and show experimentally that it is faster for many hyper-parameter configurations, being often a better option than second order SMO when performing a grid-search for SVM tuning.
Assessing Supply Chain Cyber Risks
Nov 26, 2019

Risk assessment is a major challenge for supply chain managers, as it potentially affects business factors such as service costs, supplier competition and customer expectations. The increasing interconnectivity between organisations has put into focus methods for supply chain cyber risk management. We introduce a general approach to support such activity taking into account various techniques of attacking an organisation and its suppliers, as well as the impacts of such attacks. Since data is lacking in many respects, we use structured expert judgment methods to facilitate its implementation. We couple a family of forecasting models to enrich risk monitoring. The approach may be used to set up risk alarms, negotiate service level agreements, rank suppliers and identify insurance needs, among other management possibilities.