 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNonstochastic Bandits with Infinitely Many Experts
Feb 09, 2021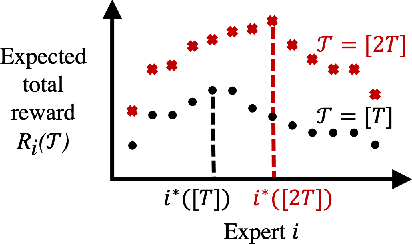
We study the problem of nonstochastic bandits with infinitely many experts: A learner aims to maximize the total reward by taking actions sequentially based on bandit feedback while benchmarking against a countably infinite set of experts. We propose a variant of Exp4.P that, for finitely many experts, enables inference of correct expert rankings while preserving the order of the regret upper bound. We then incorporate the variant into a meta-algorithm that works on infinitely many experts. We prove a high-probability upper bound of $\tilde{\mathcal{O}} \big( i^*K + \sqrt{KT} \big)$ on the regret, up to polylog factors, where $i^*$ is the unknown position of the best expert, $K$ is the number of actions, and $T$ is the time horizon. We also provide an example of structured experts and discuss how to expedite learning in such case. Our meta-learning algorithm achieves the tightest regret upper bound for the setting considered when $i^* = \tilde{\mathcal{O}} \big( \sqrt{T/K} \big)$. If a prior distribution is assumed to exist for $i^*$, the probability of satisfying a tight regret bound increases with $T$, the rate of which can be fast.
Learning nonlinear dynamical systems from a single trajectory
Apr 30, 2020We introduce algorithms for learning nonlinear dynamical systems of the form $x_{t+1}=\sigma(\Theta^{\star}x_t)+\varepsilon_t$, where $\Theta^{\star}$ is a weight matrix, $\sigma$ is a nonlinear link function, and $\varepsilon_t$ is a mean-zero noise process. We give an algorithm that recovers the weight matrix $\Theta^{\star}$ from a single trajectory with optimal sample complexity and linear running time. The algorithm succeeds under weaker statistical assumptions than in previous work, and in particular i) does not require a bound on the spectral norm of the weight matrix $\Theta^{\star}$ (rather, it depends on a generalization of the spectral radius) and ii) enjoys guarantees for non-strictly-increasing link functions such as the ReLU. Our analysis has two key components: i) we give a general recipe whereby global stability for nonlinear dynamical systems can be used to certify that the state-vector covariance is well-conditioned, and ii) using these tools, we extend well-known algorithms for efficiently learning generalized linear models to the dependent setting.
Lossy Compression via Sparse Linear Regression: Computationally Efficient Encoding and Decoding
Mar 28, 2014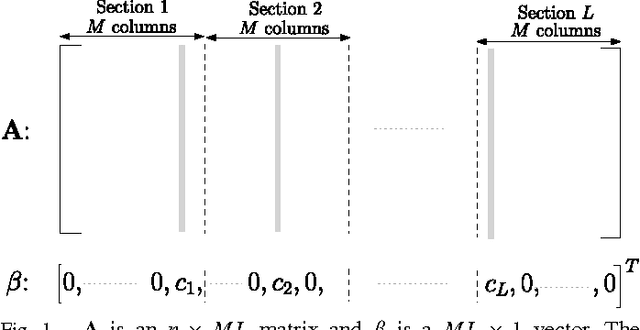
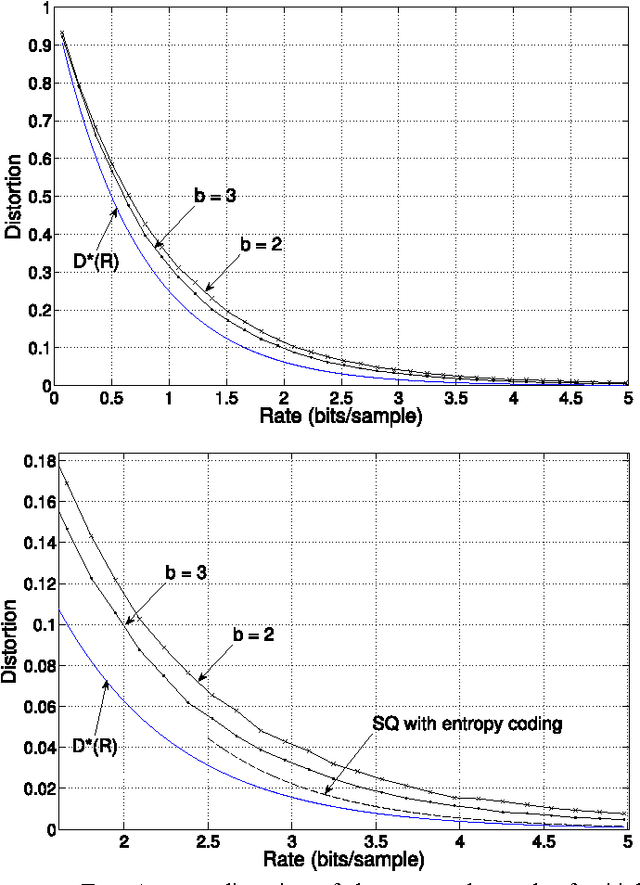
We propose computationally efficient encoders and decoders for lossy compression using a Sparse Regression Code. The codebook is defined by a design matrix and codewords are structured linear combinations of columns of this matrix. The proposed encoding algorithm sequentially chooses columns of the design matrix to successively approximate the source sequence. It is shown to achieve the optimal distortion-rate function for i.i.d Gaussian sources under the squared-error distortion criterion. For a given rate, the parameters of the design matrix can be varied to trade off distortion performance with encoding complexity. An example of such a trade-off as a function of the block length n is the following. With computational resource (space or time) per source sample of O((n/\log n)^2), for a fixed distortion-level above the Gaussian distortion-rate function, the probability of excess distortion decays exponentially in n. The Sparse Regression Code is robust in the following sense: for any ergodic source, the proposed encoder achieves the optimal distortion-rate function of an i.i.d Gaussian source with the same variance. Simulations show that the encoder has good empirical performance, especially at low and moderate rates.
* 14 pages, to appear in IEEE Transactions on Information Theory