 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData-driven control of COVID-19 in buildings: a reinforcement-learning approach
Dec 27, 2022In addition to its public health crisis, COVID-19 pandemic has led to the shutdown and closure of workplaces with an estimated total cost of more than $16 trillion. Given the long hours an average person spends in buildings and indoor environments, this research article proposes data-driven control strategies to design optimal indoor airflow to minimize the exposure of occupants to viral pathogens in built environments. A general control framework is put forward for designing an optimal velocity field and proximal policy optimization, a reinforcement learning algorithm is employed to solve the control problem in a data-driven fashion. The same framework is used for optimal placement of disinfectants to neutralize the viral pathogens as an alternative to the airflow design when the latter is practically infeasible or hard to implement. We show, via simulation experiments, that the control agent learns the optimal policy in both scenarios within a reasonable time. The proposed data-driven control framework in this study will have significant societal and economic benefits by setting the foundation for an improved methodology in designing case-specific infection control guidelines that can be realized by affordable ventilation devices and disinfectants.
Nonstochastic Bandits with Infinitely Many Experts
Feb 09, 2021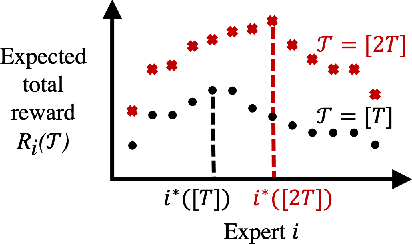
We study the problem of nonstochastic bandits with infinitely many experts: A learner aims to maximize the total reward by taking actions sequentially based on bandit feedback while benchmarking against a countably infinite set of experts. We propose a variant of Exp4.P that, for finitely many experts, enables inference of correct expert rankings while preserving the order of the regret upper bound. We then incorporate the variant into a meta-algorithm that works on infinitely many experts. We prove a high-probability upper bound of $\tilde{\mathcal{O}} \big( i^*K + \sqrt{KT} \big)$ on the regret, up to polylog factors, where $i^*$ is the unknown position of the best expert, $K$ is the number of actions, and $T$ is the time horizon. We also provide an example of structured experts and discuss how to expedite learning in such case. Our meta-learning algorithm achieves the tightest regret upper bound for the setting considered when $i^* = \tilde{\mathcal{O}} \big( \sqrt{T/K} \big)$. If a prior distribution is assumed to exist for $i^*$, the probability of satisfying a tight regret bound increases with $T$, the rate of which can be fast.
Data-driven control of micro-climate in buildings; an event-triggered reinforcement learning approach
Jan 28, 2020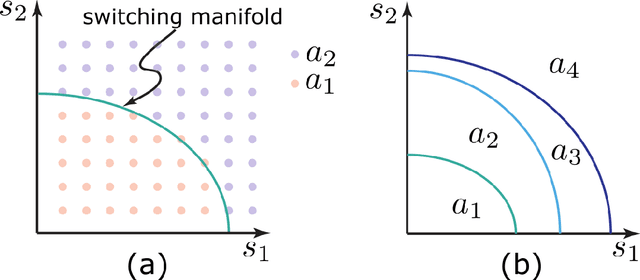

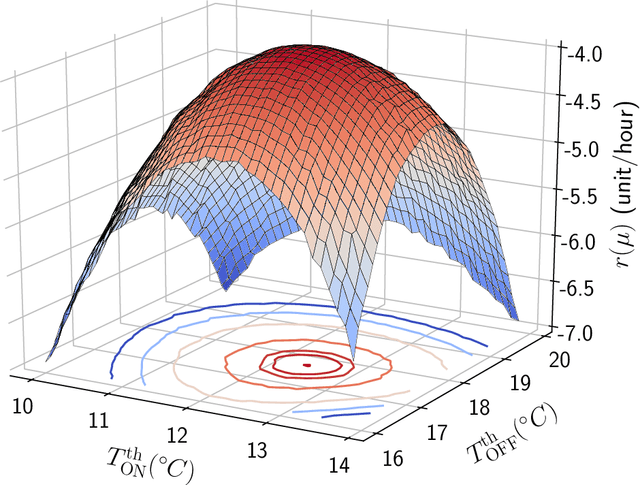
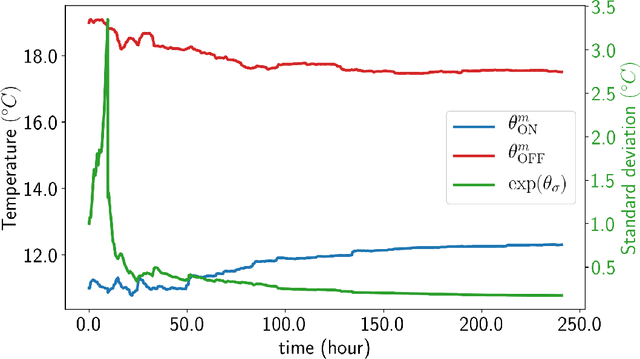
Smart buildings have great potential for shaping an energy-efficient, sustainable, and more economic future for our planet as buildings account for approximately 40% of the global energy consumption. A key challenge for large-scale plug and play deployment of the smart building technology is the ability to learn a good control policy in a short period of time, i.e. having a low sample complexity for the learning control agent. Motivated by this problem and to remedy the issue of high sample complexity in the general context of cyber-physical systems, we propose an event-triggered paradigm for learning and control with variable-time intervals, as opposed to the traditional constant-time sampling. The events occur when the system state crosses the a priori-parameterized switching manifolds; this crossing triggers the learning as well as the control processes. Policy gradient and temporal difference methods are employed to learn the optimal switching manifolds which define the optimal control policy. We propose two event-triggered learning algorithms for stochastic and deterministic control policies. We show the efficacy of our proposed approach via designing a smart learning thermostat for autonomous micro-climate control in buildings. The event-triggered algorithms are implemented on a single-zone building to decrease buildings' energy consumption as well as to increase occupants' comfort. Simulation results confirm the efficacy and improved sample efficiency of the proposed event-triggered approach for online learning and control.