 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocal Poisson Deconvolution for Discrete Signals
Aug 01, 2025We analyze the statistical problem of recovering an atomic signal, modeled as a discrete uniform distribution $\mu$, from a binned Poisson convolution model. This question is motivated, among others, by super-resolution laser microscopy applications, where precise estimation of $\mu$ provides insights into spatial formations of cellular protein assemblies. Our main results quantify the local minimax risk of estimating $\mu$ for a broad class of smooth convolution kernels. This local perspective enables us to sharply quantify optimal estimation rates as a function of the clustering structure of the underlying signal. Moreover, our results are expressed under a multiscale loss function, which reveals that different parts of the underlying signal can be recovered at different rates depending on their local geometry. Overall, these results paint an optimistic perspective on the Poisson deconvolution problem, showing that accurate recovery is achievable under a much broader class of signals than suggested by existing global minimax analyses. Beyond Poisson deconvolution, our results also allow us to establish the local minimax rate of parameter estimation in Gaussian mixture models with uniform weights. We apply our methods to experimental super-resolution microscopy data to identify the location and configuration of individual DNA origamis. In addition, we complement our findings with numerical experiments on runtime and statistical recovery that showcase the practical performance of our estimators and their trade-offs.
Statistical Inference for Optimal Transport Maps: Recent Advances and Perspectives
Jun 23, 2025
In many applications of optimal transport (OT), the object of primary interest is the optimal transport map. This map rearranges mass from one probability distribution to another in the most efficient way possible by minimizing a specified cost. In this paper we review recent advances in estimating and developing limit theorems for the OT map, using samples from the underlying distributions. We also review parallel lines of work that establish similar results for special cases and variants of the basic OT setup. We conclude with a discussion of key directions for future research with the goal of providing practitioners with reliable inferential tools.
Stability Bounds for Smooth Optimal Transport Maps and their Statistical Implications
Feb 17, 2025We study estimators of the optimal transport (OT) map between two probability distributions. We focus on plugin estimators derived from the OT map between estimates of the underlying distributions. We develop novel stability bounds for OT maps which generalize those in past work, and allow us to reduce the problem of optimally estimating the transport map to that of optimally estimating densities in the Wasserstein distance. In contrast, past work provided a partial connection between these problems and relied on regularity theory for the Monge-Ampere equation to bridge the gap, a step which required unnatural assumptions to obtain sharp guarantees. We also provide some new insights into the connections between stability bounds which arise in the analysis of plugin estimators and growth bounds for the semi-dual functional which arise in the analysis of Brenier potential-based estimators of the transport map. We illustrate the applicability of our new stability bounds by revisiting the smooth setting studied by Manole et al., analyzing two of their estimators under more general conditions. Critically, our bounds do not require smoothness or boundedness assumptions on the underlying measures. As an illustrative application, we develop and analyze a novel tuning parameter-free estimator for the OT map between two strongly log-concave distributions.
Refined Convergence Rates for Maximum Likelihood Estimation under Finite Mixture Models
Feb 17, 2022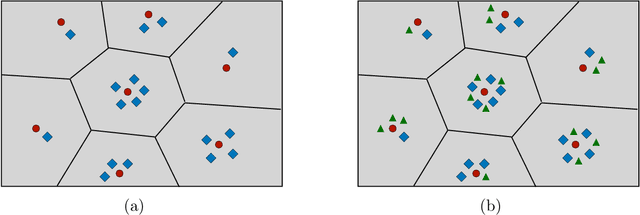
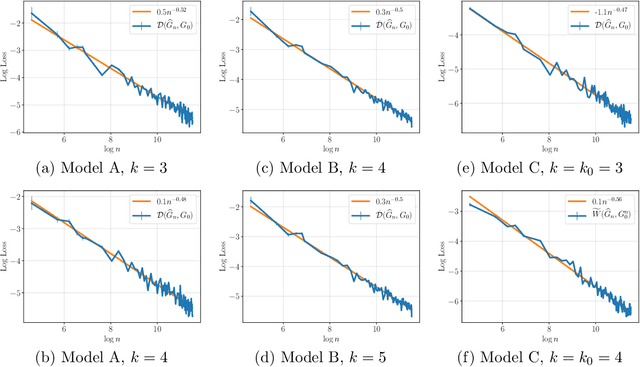
We revisit convergence rates for maximum likelihood estimation (MLE) under finite mixture models. The Wasserstein distance has become a standard loss function for the analysis of parameter estimation in these models, due in part to its ability to circumvent label switching and to accurately characterize the behaviour of fitted mixture components with vanishing weights. However, the Wasserstein metric is only able to capture the worst-case convergence rate among the remaining fitted mixture components. We demonstrate that when the log-likelihood function is penalized to discourage vanishing mixing weights, stronger loss functions can be derived to resolve this shortcoming of the Wasserstein distance. These new loss functions accurately capture the heterogeneity in convergence rates of fitted mixture components, and we use them to sharpen existing pointwise and uniform convergence rates in various classes of mixture models. In particular, these results imply that a subset of the components of the penalized MLE typically converge significantly faster than could have been anticipated from past work. We further show that some of these conclusions extend to the traditional MLE. Our theoretical findings are supported by a simulation study to illustrate these improved convergence rates.
Plugin Estimation of Smooth Optimal Transport Maps
Jul 26, 2021We analyze a number of natural estimators for the optimal transport map between two distributions and show that they are minimax optimal. We adopt the plugin approach: our estimators are simply optimal couplings between measures derived from our observations, appropriately extended so that they define functions on $\mathbb{R}^d$. When the underlying map is assumed to be Lipschitz, we show that computing the optimal coupling between the empirical measures, and extending it using linear smoothers, already gives a minimax optimal estimator. When the underlying map enjoys higher regularity, we show that the optimal coupling between appropriate nonparametric density estimates yields faster rates. Our work also provides new bounds on the risk of corresponding plugin estimators for the quadratic Wasserstein distance, and we show how this problem relates to that of estimating optimal transport maps using stability arguments for smooth and strongly convex Brenier potentials. As an application of our results, we derive a central limit theorem for a density plugin estimator of the squared Wasserstein distance, which is centered at its population counterpart when the underlying distributions have sufficiently smooth densities. In contrast to known central limit theorems for empirical estimators, this result easily lends itself to statistical inference for Wasserstein distances.
Sequential Estimation of Convex Divergences using Reverse Submartingales and Exchangeable Filtrations
Mar 16, 2021We present a unified technique for sequential estimation of convex divergences between distributions, including integral probability metrics like the kernel maximum mean discrepancy, $\varphi$-divergences like the Kullback-Leibler divergence, and optimal transport costs, such as powers of Wasserstein distances. The technical underpinnings of our approach lie in the observation that empirical convex divergences are (partially ordered) reverse submartingales with respect to the exchangeable filtration, coupled with maximal inequalities for such processes. These techniques appear to be powerful additions to the existing literature on both confidence sequences and convex divergences. We construct an offline-to-sequential device that converts a wide array of existing offline concentration inequalities into time-uniform confidence sequences that can be continuously monitored, providing valid inference at arbitrary stopping times. The resulting sequential bounds pay only an iterated logarithmic price over the corresponding fixed-time bounds, retaining the same dependence on problem parameters (like dimension or alphabet size if applicable).
Uniform Convergence Rates for Maximum Likelihood Estimation under Two-Component Gaussian Mixture Models
Jun 01, 2020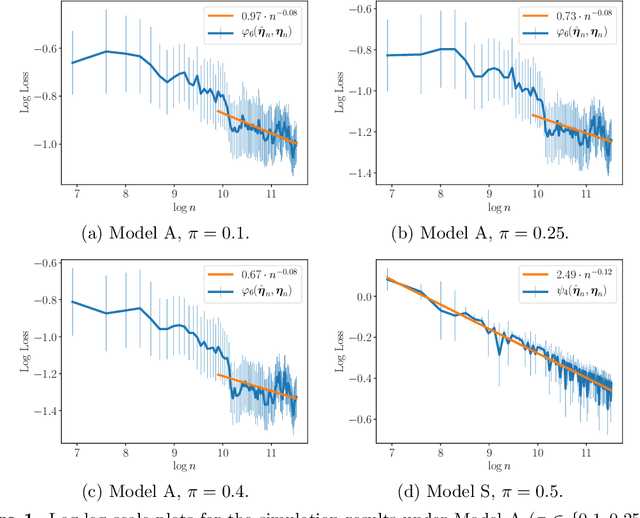
We derive uniform convergence rates for the maximum likelihood estimator and minimax lower bounds for parameter estimation in two-component location-scale Gaussian mixture models with unequal variances. We assume the mixing proportions of the mixture are known and fixed, but make no separation assumption on the underlying mixture components. A phase transition is shown to exist in the optimal parameter estimation rate, depending on whether or not the mixture is balanced. Key to our analysis is a careful study of the dependence between the parameters of location-scale Gaussian mixture models, as captured through systems of polynomial equalities and inequalities whose solution set drives the rates we obtain. A simulation study illustrates the theoretical findings of this work.
Estimating the Number of Components in Finite Mixture Models via the Group-Sort-Fuse Procedure
May 24, 2020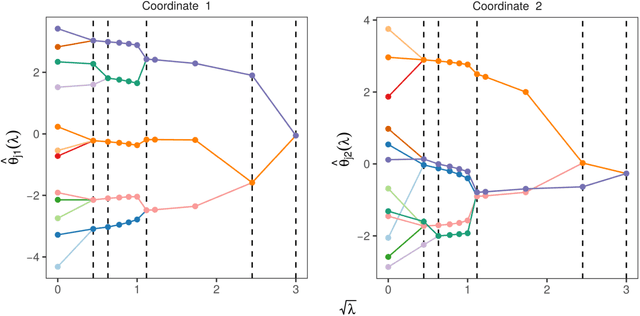

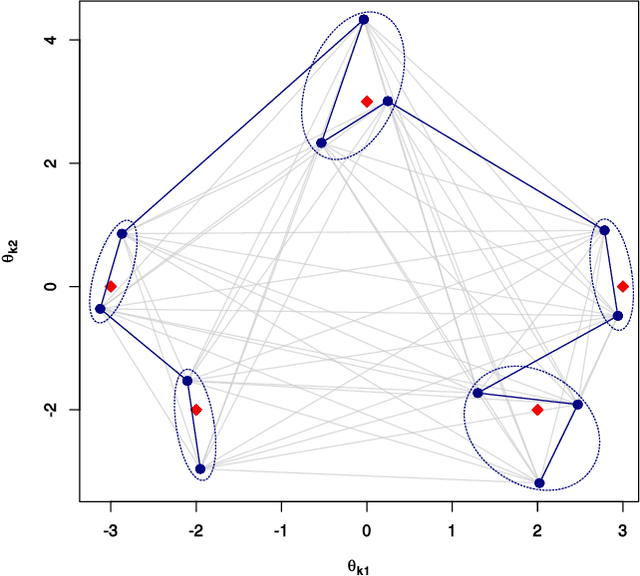

Estimation of the number of components (or order) of a finite mixture model is a long standing and challenging problem in statistics. We propose the Group-Sort-Fuse (GSF) procedure---a new penalized likelihood approach for simultaneous estimation of the order and mixing measure in multidimensional finite mixture models. Unlike methods which fit and compare mixtures with varying orders using criteria involving model complexity, our approach directly penalizes a continuous function of the model parameters. More specifically, given a conservative upper bound on the order, the GSF groups and sorts mixture component parameters to fuse those which are redundant. For a wide range of finite mixture models, we show that the GSF is consistent in estimating the true mixture order and achieves the $n^{-1/2}$ convergence rate for parameter estimation up to polylogarithmic factors. The GSF is implemented for several univariate and multivariate mixture models in the R package GroupSortFuse. Its finite sample performance is supported by a thorough simulation study, and its application is illustrated on two real data examples.
Minimax Confidence Intervals for the Sliced Wasserstein Distance
Sep 17, 2019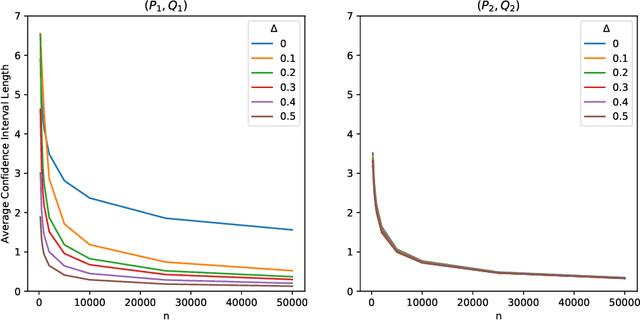
The Wasserstein distance has risen in popularity in the statistics and machine learning communities as a useful metric for comparing probability distributions. We study the problem of uncertainty quantification for the Sliced Wasserstein distance--an easily computable approximation of the Wasserstein distance. Specifically, we construct confidence intervals for the Sliced Wasserstein distance which have finite-sample validity under no assumptions or mild moment assumptions, and are adaptive in length to the smoothness of the underlying distributions. We also bound the minimax risk of estimating the Sliced Wasserstein distance, and show that the length of our proposed confidence intervals is minimax optimal over appropriate distribution classes. To motivate the choice of these classes, we also study minimax rates of estimating a distribution under the Sliced Wasserstein distance. These theoretical findings are complemented with a simulation study.