 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMining experimental data from Materials Science literature with Large Language Models
Jan 19, 2024This study is dedicated to evaluating the capabilities of advanced large language models (LLMs) such as GPT-3.5-Turbo, GPT-4, and GPT-4-Turbo in the extraction of structured information from scientific documents within the field of materials science. We introduce a novel methodology for the comparative analysis of intricate material expressions, emphasising the standardisation of chemical formulas to tackle the complexities inherent in materials science information assessment. To this end, we primarily focus on two critical tasks of information extraction: (i) a named entity recognition (NER) of studied materials and physical properties and (ii) a relation extraction (RE) between these entities. The performance of LLMs in executing these tasks is benchmarked against traditional models based on the BERT architecture and rule-based approaches. For NER, LLMs fail to outperform the baseline with zero-shot prompting and exhibit only limited improvement with few-shot prompting. However, for RE, a GPT-3.5-Turbo fine-tuned with the appropriate strategy outperforms all models, including the baseline. Without any fine-tuning, GPT-4 and GPT-4-Turbo display remarkable reasoning and relationship extraction capabilities after being provided with merely a couple of examples, surpassing the baseline. Overall, the results suggest that although LLMs demonstrate relevant reasoning skills in connecting concepts, for tasks requiring extracting complex domain-specific entities like materials, specialised models are currently a better choice.
Semi-automatic staging area for high-quality structured data extraction from scientific literature
Sep 19, 2023In this study, we propose a staging area for ingesting new superconductors' experimental data in SuperCon that is machine-collected from scientific articles. Our objective is to enhance the efficiency of updating SuperCon while maintaining or enhancing the data quality. We present a semi-automatic staging area driven by a workflow combining automatic and manual processes on the extracted database. An anomaly detection automatic process aims to pre-screen the collected data. Users can then manually correct any errors through a user interface tailored to simplify the data verification on the original PDF documents. Additionally, when a record is corrected, its raw data is collected and utilised to improve machine learning models as training data. Evaluation experiments demonstrate that our staging area significantly improves curation quality. We compare the interface with the traditional manual approach of reading PDF documents and recording information in an Excel document. Using the interface boosts the precision and recall by 6% and 50%, respectively to an average increase of 40% in F1-score.
AdapterEM: Pre-trained Language Model Adaptation for Generalized Entity Matching using Adapter-tuning
May 30, 2023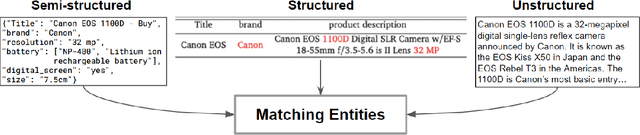
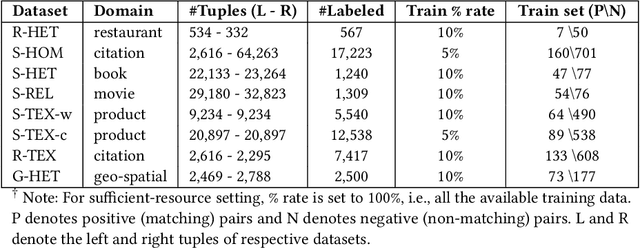
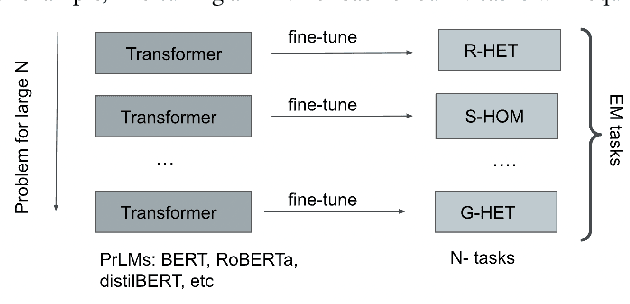
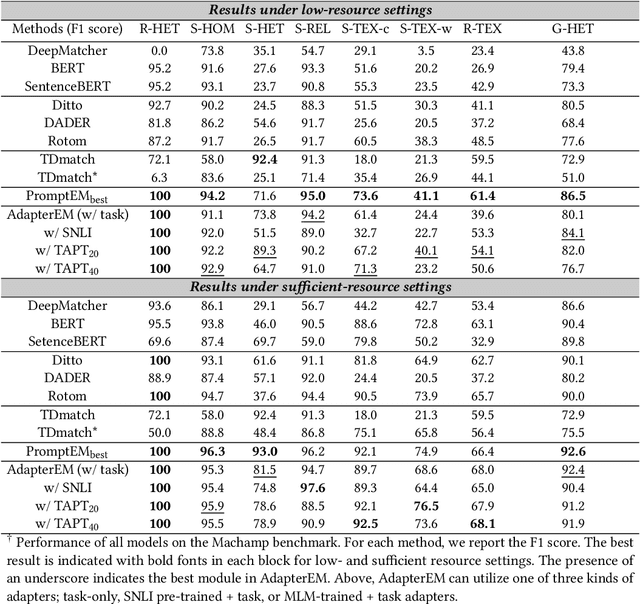
Entity Matching (EM) involves identifying different data representations referring to the same entity from multiple data sources and is typically formulated as a binary classification problem. It is a challenging problem in data integration due to the heterogeneity of data representations. State-of-the-art solutions have adopted NLP techniques based on pre-trained language models (PrLMs) via the fine-tuning paradigm, however, sequential fine-tuning of overparameterized PrLMs can lead to catastrophic forgetting, especially in low-resource scenarios. In this study, we propose a parameter-efficient paradigm for fine-tuning PrLMs based on adapters, small neural networks encapsulated between layers of a PrLM, by optimizing only the adapter and classifier weights while the PrLMs parameters are frozen. Adapter-based methods have been successfully applied to multilingual speech problems achieving promising results, however, the effectiveness of these methods when applied to EM is not yet well understood, particularly for generalized EM with heterogeneous data. Furthermore, we explore using (i) pre-trained adapters and (ii) invertible adapters to capture token-level language representations and demonstrate their benefits for transfer learning on the generalized EM benchmark. Our results show that our solution achieves comparable or superior performance to full-scale PrLM fine-tuning and prompt-tuning baselines while utilizing a significantly smaller computational footprint $\approx 13\%$ of the PrLM parameters.