 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdapterEM: Pre-trained Language Model Adaptation for Generalized Entity Matching using Adapter-tuning
May 30, 2023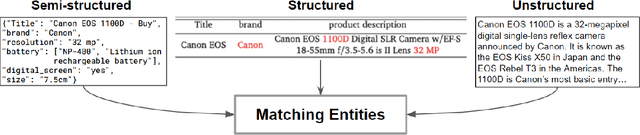
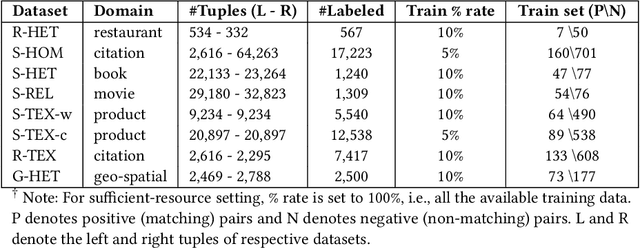
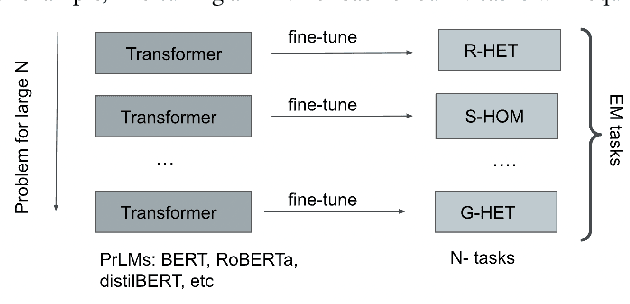
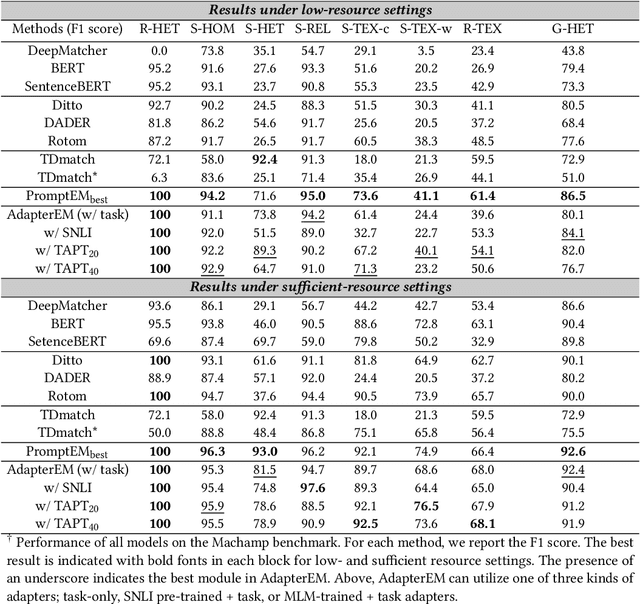
Entity Matching (EM) involves identifying different data representations referring to the same entity from multiple data sources and is typically formulated as a binary classification problem. It is a challenging problem in data integration due to the heterogeneity of data representations. State-of-the-art solutions have adopted NLP techniques based on pre-trained language models (PrLMs) via the fine-tuning paradigm, however, sequential fine-tuning of overparameterized PrLMs can lead to catastrophic forgetting, especially in low-resource scenarios. In this study, we propose a parameter-efficient paradigm for fine-tuning PrLMs based on adapters, small neural networks encapsulated between layers of a PrLM, by optimizing only the adapter and classifier weights while the PrLMs parameters are frozen. Adapter-based methods have been successfully applied to multilingual speech problems achieving promising results, however, the effectiveness of these methods when applied to EM is not yet well understood, particularly for generalized EM with heterogeneous data. Furthermore, we explore using (i) pre-trained adapters and (ii) invertible adapters to capture token-level language representations and demonstrate their benefits for transfer learning on the generalized EM benchmark. Our results show that our solution achieves comparable or superior performance to full-scale PrLM fine-tuning and prompt-tuning baselines while utilizing a significantly smaller computational footprint $\approx 13\%$ of the PrLM parameters.