 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Laws for Emulation of Stellar Spectra
Mar 24, 2025Neural network-based emulators for the inference of stellar parameters and elemental abundances represent an increasingly popular methodology in modern spectroscopic surveys. However, these approaches are often constrained by their emulation precision and domain transfer capabilities. Greater generalizability has previously been achieved only with significantly larger model architectures, as demonstrated by Transformer-based models in natural language processing. This observation aligns with neural scaling laws, where model performance predictably improves with increased model size, computational resources allocated to model training, and training data volume. In this study, we demonstrate that these scaling laws also apply to Transformer-based spectral emulators in astronomy. Building upon our previous work with TransformerPayne and incorporating Maximum Update Parametrization techniques from natural language models, we provide training guidelines for scaling models to achieve optimal performance. Our results show that within the explored parameter space, clear scaling relationships emerge. These findings suggest that optimal computational resource allocation requires balanced scaling. Specifically, given a tenfold increase in training compute, achieving an optimal seven-fold reduction in mean squared error necessitates an approximately 2.5-fold increase in dataset size and a 3.8-fold increase in model size. This study establishes a foundation for developing spectral foundational models with enhanced domain transfer capabilities.
AstroLLaMA: Towards Specialized Foundation Models in Astronomy
Sep 12, 2023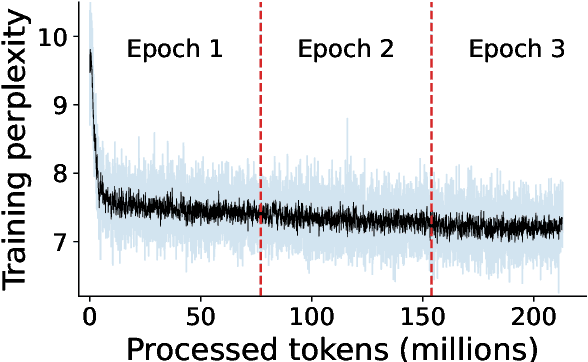

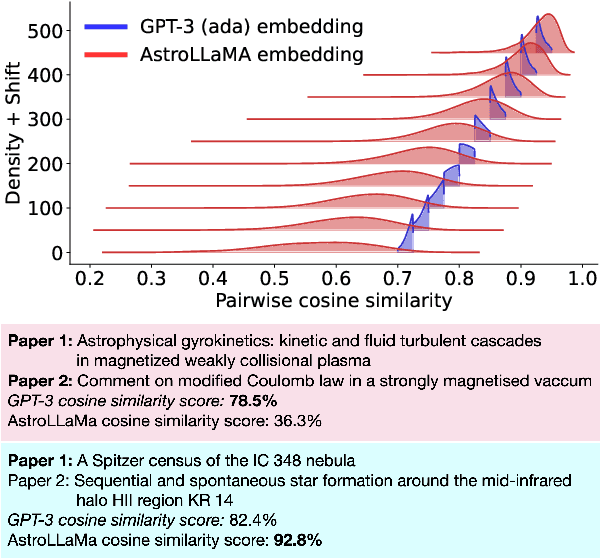
Large language models excel in many human-language tasks but often falter in highly specialized domains like scholarly astronomy. To bridge this gap, we introduce AstroLLaMA, a 7-billion-parameter model fine-tuned from LLaMA-2 using over 300,000 astronomy abstracts from arXiv. Optimized for traditional causal language modeling, AstroLLaMA achieves a 30% lower perplexity than Llama-2, showing marked domain adaptation. Our model generates more insightful and scientifically relevant text completions and embedding extraction than state-of-the-arts foundation models despite having significantly fewer parameters. AstroLLaMA serves as a robust, domain-specific model with broad fine-tuning potential. Its public release aims to spur astronomy-focused research, including automatic paper summarization and conversational agent development.