 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Learning based Forecasting: a case study from the online fashion industry
May 23, 2023Demand forecasting in the online fashion industry is particularly amendable to global, data-driven forecasting models because of the industry's set of particular challenges. These include the volume of data, the irregularity, the high amount of turn-over in the catalog and the fixed inventory assumption. While standard deep learning forecasting approaches cater for many of these, the fixed inventory assumption requires a special treatment via controlling the relationship between price and demand closely. In this case study, we describe the data and our modelling approach for this forecasting problem in detail and present empirical results that highlight the effectiveness of our approach.
Probabilistic Time Series Forecasting with Implicit Quantile Networks
Jul 08, 2021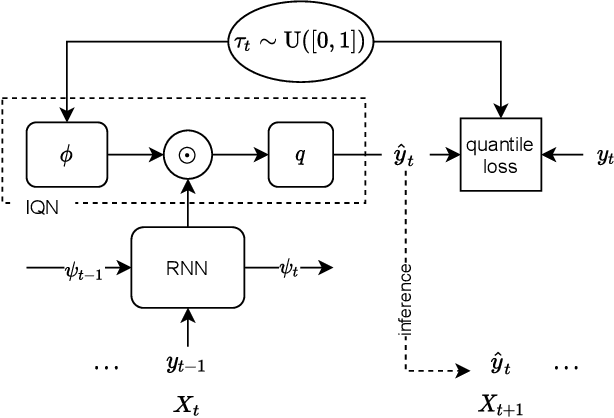
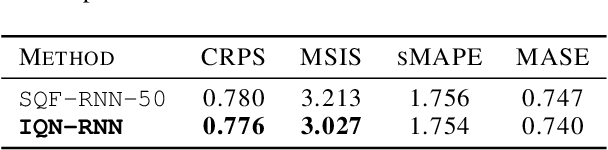
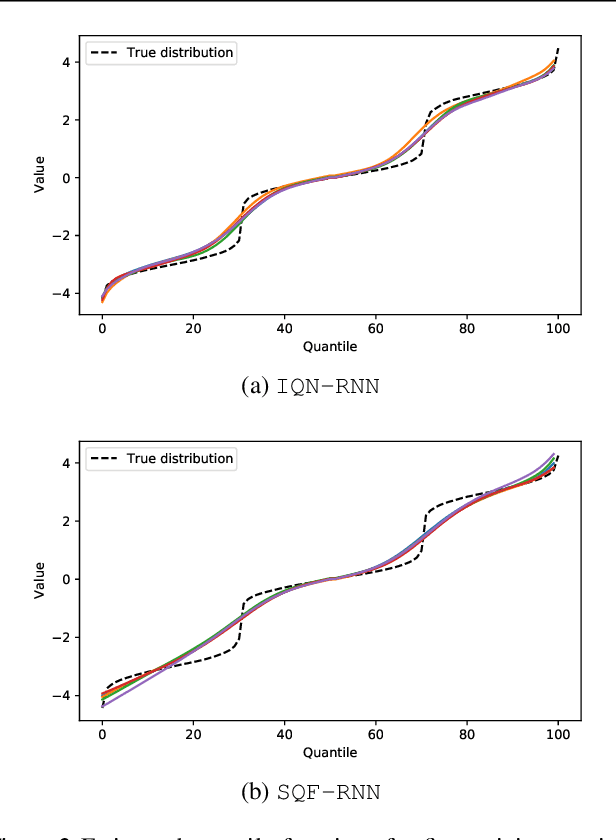
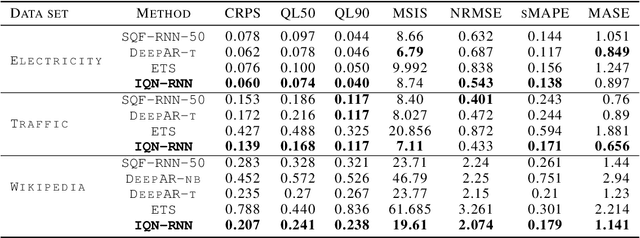
Here, we propose a general method for probabilistic time series forecasting. We combine an autoregressive recurrent neural network to model temporal dynamics with Implicit Quantile Networks to learn a large class of distributions over a time-series target. When compared to other probabilistic neural forecasting models on real- and simulated data, our approach is favorable in terms of point-wise prediction accuracy as well as on estimating the underlying temporal distribution.
Automatic Pronunciation Generation by Utilizing a Semi-supervised Deep Neural Networks
Jun 15, 2016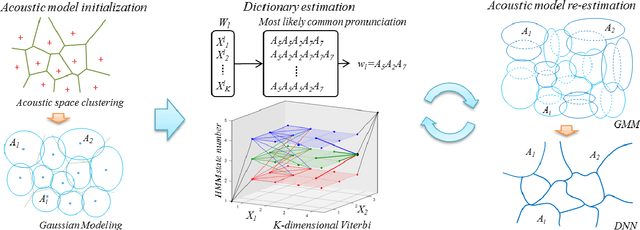

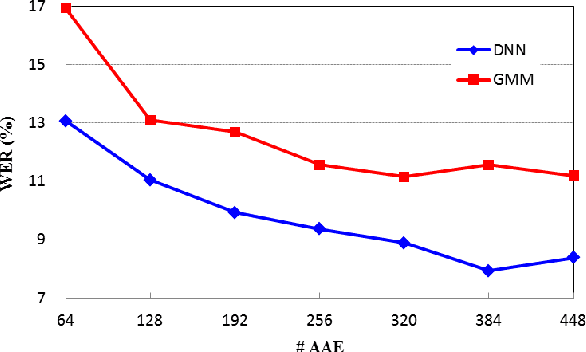
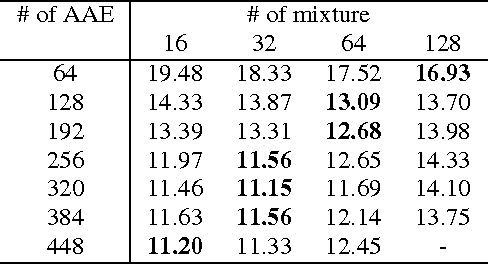
Phonemic or phonetic sub-word units are the most commonly used atomic elements to represent speech signals in modern ASRs. However they are not the optimal choice due to several reasons such as: large amount of effort required to handcraft a pronunciation dictionary, pronunciation variations, human mistakes and under-resourced dialects and languages. Here, we propose a data-driven pronunciation estimation and acoustic modeling method which only takes the orthographic transcription to jointly estimate a set of sub-word units and a reliable dictionary. Experimental results show that the proposed method which is based on semi-supervised training of a deep neural network largely outperforms phoneme based continuous speech recognition on the TIMIT dataset.
A Boosting Framework on Grounds of Online Learning
Nov 23, 2014By exploiting the duality between boosting and online learning, we present a boosting framework which proves to be extremely powerful thanks to employing the vast knowledge available in the online learning area. Using this framework, we develop various algorithms to address multiple practically and theoretically interesting questions including sparse boosting, smooth-distribution boosting, agnostic learning and some generalization to double-projection online learning algorithms, as a by-product.
A Semidefinite Programming Based Search Strategy for Feature Selection with Mutual Information Measure
Nov 12, 2014
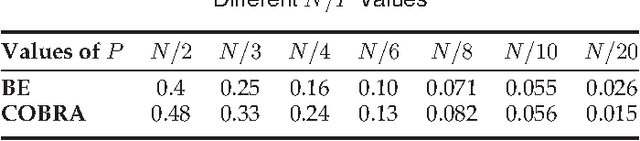

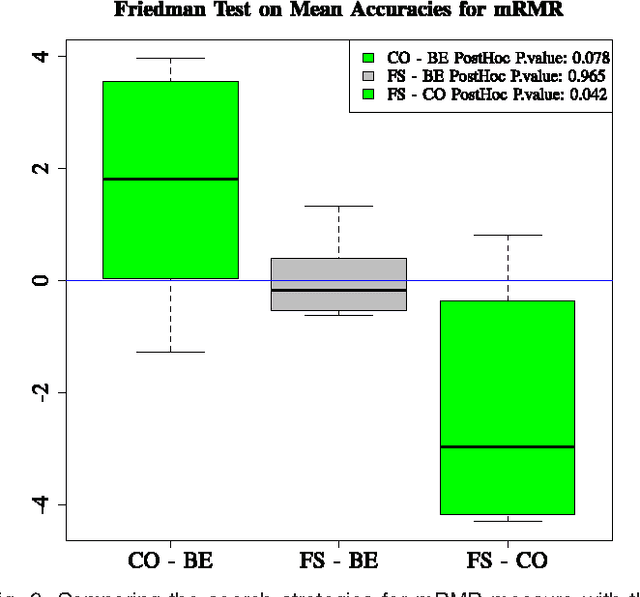
Feature subset selection, as a special case of the general subset selection problem, has been the topic of a considerable number of studies due to the growing importance of data-mining applications. In the feature subset selection problem there are two main issues that need to be addressed: (i) Finding an appropriate measure function than can be fairly fast and robustly computed for high-dimensional data. (ii) A search strategy to optimize the measure over the subset space in a reasonable amount of time. In this article mutual information between features and class labels is considered to be the measure function. Two series expansions for mutual information are proposed, and it is shown that most heuristic criteria suggested in the literature are truncated approximations of these expansions. It is well-known that searching the whole subset space is an NP-hard problem. Here, instead of the conventional sequential search algorithms, we suggest a parallel search strategy based on semidefinite programming (SDP) that can search through the subset space in polynomial time. By exploiting the similarities between the proposed algorithm and an instance of the maximum-cut problem in graph theory, the approximation ratio of this algorithm is derived and is compared with the approximation ratio of the backward elimination method. The experiments show that it can be misleading to judge the quality of a measure solely based on the classification accuracy, without taking the effect of the non-optimum search strategy into account.