 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUltrasound Image-to-Video Synthesis via Latent Dynamic Diffusion Models
Mar 19, 2025Ultrasound video classification enables automated diagnosis and has emerged as an important research area. However, publicly available ultrasound video datasets remain scarce, hindering progress in developing effective video classification models. We propose addressing this shortage by synthesizing plausible ultrasound videos from readily available, abundant ultrasound images. To this end, we introduce a latent dynamic diffusion model (LDDM) to efficiently translate static images to dynamic sequences with realistic video characteristics. We demonstrate strong quantitative results and visually appealing synthesized videos on the BUSV benchmark. Notably, training video classification models on combinations of real and LDDM-synthesized videos substantially improves performance over using real data alone, indicating our method successfully emulates dynamics critical for discrimination. Our image-to-video approach provides an effective data augmentation solution to advance ultrasound video analysis. Code is available at https://github.com/MedAITech/U_I2V.
Past and Future Motion Guided Network for Audio Visual Event Localization
May 08, 2022
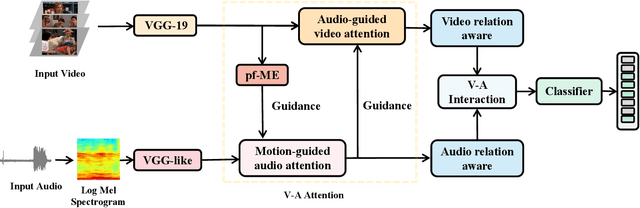
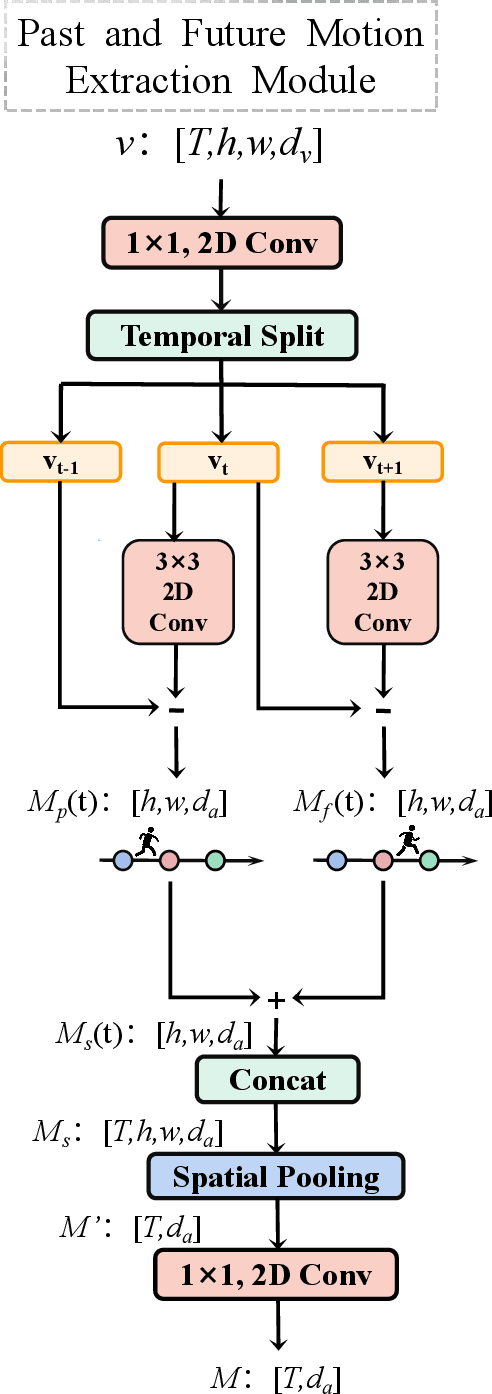
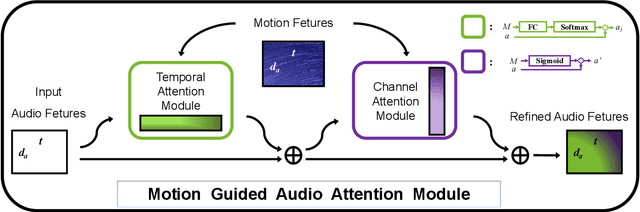
In recent years, audio-visual event localization has attracted much attention. It's purpose is to detect the segment containing audio-visual events and recognize the event category from untrimmed videos. Existing methods use audio-guided visual attention to lead the model pay attention to the spatial area of the ongoing event, devoting to the correlation between audio and visual information but ignoring the correlation between audio and spatial motion. We propose a past and future motion extraction (pf-ME) module to mine the visual motion from videos ,embedded into the past and future motion guided network (PFAGN), and motion guided audio attention (MGAA) module to achieve focusing on the information related to interesting events in audio modality through the past and future visual motion. We choose AVE as the experimental verification dataset and the experiments show that our method outperforms the state-of-the-arts in both supervised and weakly-supervised settings.