 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBlack-box Model Merging for Language-Model-as-a-Service with Massive Model Repositories
Sep 16, 2025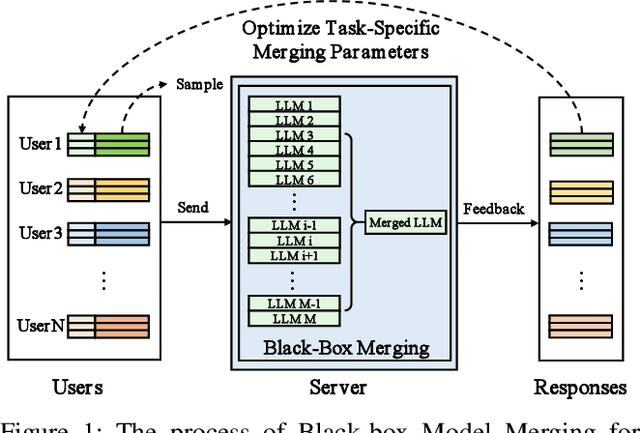
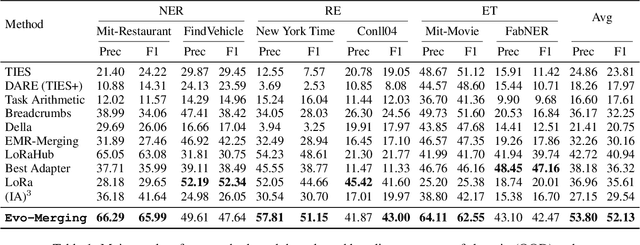
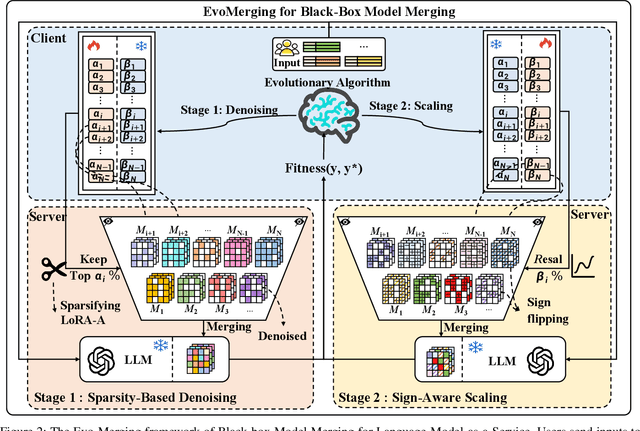
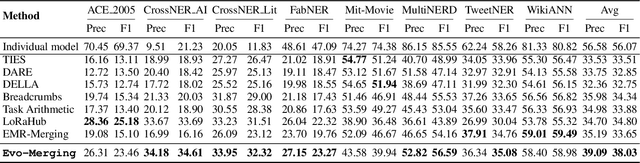
Model merging refers to the process of integrating multiple distinct models into a unified model that preserves and combines the strengths and capabilities of the individual models. Most existing approaches rely on task vectors to combine models, typically under the assumption that model parameters are accessible. However, for extremely large language models (LLMs) such as GPT-4, which are often provided solely as black-box services through API interfaces (Language-Model-as-a-Service), model weights are not available to end users. This presents a significant challenge, which we refer to as black-box model merging (BMM) with massive LLMs. To address this challenge, we propose a derivative-free optimization framework based on the evolutionary algorithm (Evo-Merging) that enables effective model merging using only inference-time API queries. Our method consists of two key components: (1) sparsity-based denoising, designed to identify and filter out irrelevant or redundant information across models, and (2) sign-aware scaling, which dynamically computes optimal combination weights for the relevant models based on their performance. We also provide a formal justification, along with a theoretical analysis, for our asymmetric sparsification. Extensive experimental evaluations demonstrate that our approach achieves state-of-the-art results on a range of tasks, significantly outperforming existing strong baselines.
Building Self-Evolving Agents via Experience-Driven Lifelong Learning: A Framework and Benchmark
Aug 26, 2025As AI advances toward general intelligence, the focus is shifting from systems optimized for static tasks to creating open-ended agents that learn continuously. In this paper, we introduce Experience-driven Lifelong Learning (ELL), a framework for building self-evolving agents capable of continuous growth through real-world interaction. The framework is built on four core principles: (1) Experience Exploration: Agents learn through continuous, self-motivated interaction with dynamic environments, navigating interdependent tasks and generating rich experiential trajectories. (2) Long-term Memory: Agents preserve and structure historical knowledge, including personal experiences, domain expertise, and commonsense reasoning, into a persistent memory system. (3) Skill Learning: Agents autonomously improve by abstracting recurring patterns from experience into reusable skills, which are actively refined and validated for application in new tasks. (4) Knowledge Internalization: Agents internalize explicit and discrete experiences into implicit and intuitive capabilities as "second nature". We also introduce StuLife, a benchmark dataset for ELL that simulates a student's holistic college journey, from enrollment to academic and personal development, across three core phases and ten detailed sub-scenarios. StuLife is designed around three key paradigm shifts: From Passive to Proactive, From Context to Memory, and From Imitation to Learning. In this dynamic environment, agents must acquire and distill practical skills and maintain persistent memory to make decisions based on evolving state variables. StuLife provides a comprehensive platform for evaluating lifelong learning capabilities, including memory retention, skill transfer, and self-motivated behavior. Beyond evaluating SOTA LLMs on the StuLife benchmark, we also explore the role of context engineering in advancing AGI.
Task-Core Memory Management and Consolidation for Long-term Continual Learning
May 15, 2025



In this paper, we focus on a long-term continual learning (CL) task, where a model learns sequentially from a stream of vast tasks over time, acquiring new knowledge while retaining previously learned information in a manner akin to human learning. Unlike traditional CL settings, long-term CL involves handling a significantly larger number of tasks, which exacerbates the issue of catastrophic forgetting. Our work seeks to address two critical questions: 1) How do existing CL methods perform in the context of long-term CL? and 2) How can we mitigate the catastrophic forgetting that arises from prolonged sequential updates? To tackle these challenges, we propose a novel framework inspired by human memory mechanisms for long-term continual learning (Long-CL). Specifically, we introduce a task-core memory management strategy to efficiently index crucial memories and adaptively update them as learning progresses. Additionally, we develop a long-term memory consolidation mechanism that selectively retains hard and discriminative samples, ensuring robust knowledge retention. To facilitate research in this area, we construct and release two multi-modal and textual benchmarks, MMLongCL-Bench and TextLongCL-Bench, providing a valuable resource for evaluating long-term CL approaches. Experimental results show that Long-CL outperforms the previous state-of-the-art by 7.4\% and 6.5\% AP on the two benchmarks, respectively, demonstrating the effectiveness of our approach.
Recent Advances of Foundation Language Models-based Continual Learning: A Survey
May 28, 2024Recently, foundation language models (LMs) have marked significant achievements in the domains of natural language processing (NLP) and computer vision (CV). Unlike traditional neural network models, foundation LMs obtain a great ability for transfer learning by acquiring rich commonsense knowledge through pre-training on extensive unsupervised datasets with a vast number of parameters. However, they still can not emulate human-like continuous learning due to catastrophic forgetting. Consequently, various continual learning (CL)-based methodologies have been developed to refine LMs, enabling them to adapt to new tasks without forgetting previous knowledge. However, a systematic taxonomy of existing approaches and a comparison of their performance are still lacking, which is the gap that our survey aims to fill. We delve into a comprehensive review, summarization, and classification of the existing literature on CL-based approaches applied to foundation language models, such as pre-trained language models (PLMs), large language models (LLMs) and vision-language models (VLMs). We divide these studies into offline CL and online CL, which consist of traditional methods, parameter-efficient-based methods, instruction tuning-based methods and continual pre-training methods. Offline CL encompasses domain-incremental learning, task-incremental learning, and class-incremental learning, while online CL is subdivided into hard task boundary and blurry task boundary settings. Additionally, we outline the typical datasets and metrics employed in CL research and provide a detailed analysis of the challenges and future work for LMs-based continual learning.