 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Morph-Patch Transformer for Aortic Vessel Segmentation
Nov 11, 2025Accurate segmentation of aortic vascular structures is critical for diagnosing and treating cardiovascular diseases.Traditional Transformer-based models have shown promise in this domain by capturing long-range dependencies between vascular features. However, their reliance on fixed-size rectangular patches often influences the integrity of complex vascular structures, leading to suboptimal segmentation accuracy. To address this challenge, we propose the adaptive Morph Patch Transformer (MPT), a novel architecture specifically designed for aortic vascular segmentation. Specifically, MPT introduces an adaptive patch partitioning strategy that dynamically generates morphology-aware patches aligned with complex vascular structures. This strategy can preserve semantic integrity of complex vascular structures within individual patches. Moreover, a Semantic Clustering Attention (SCA) method is proposed to dynamically aggregate features from various patches with similar semantic characteristics. This method enhances the model's capability to segment vessels of varying sizes, preserving the integrity of vascular structures. Extensive experiments on three open-source dataset(AVT, AortaSeg24 and TBAD) demonstrate that MPT achieves state-of-the-art performance, with improvements in segmenting intricate vascular structures.
SpineMamba: Enhancing 3D Spinal Segmentation in Clinical Imaging through Residual Visual Mamba Layers and Shape Priors
Aug 28, 2024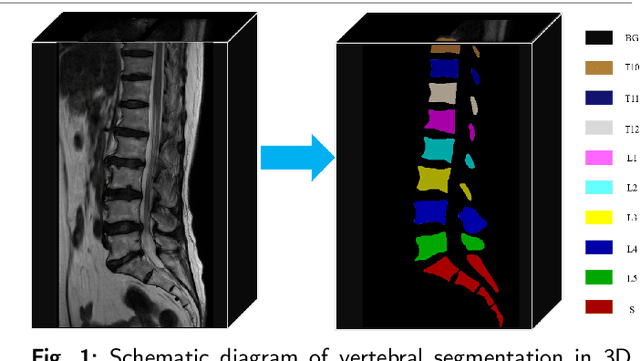
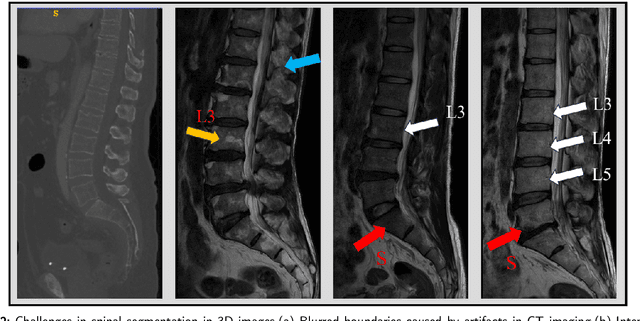

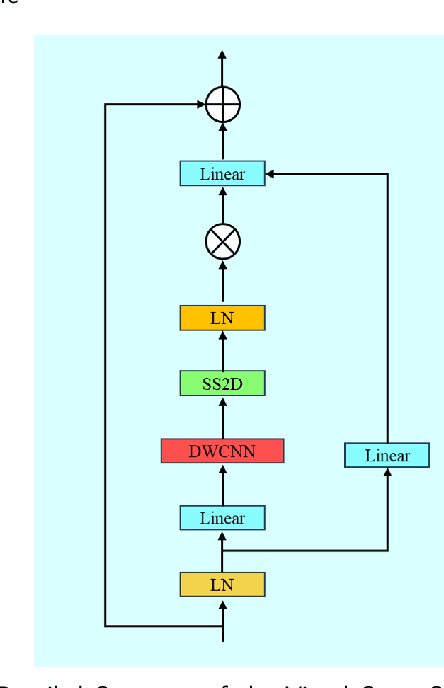
Accurate segmentation of 3D clinical medical images is critical in the diagnosis and treatment of spinal diseases. However, the inherent complexity of spinal anatomy and uncertainty inherent in current imaging technologies, poses significant challenges for semantic segmentation of spinal images. Although convolutional neural networks (CNNs) and Transformer-based models have made some progress in spinal segmentation, their limitations in handling long-range dependencies hinder further improvements in segmentation accuracy.To address these challenges, we introduce a residual visual Mamba layer to effectively capture and model the deep semantic features and long-range spatial dependencies of 3D spinal data. To further enhance the structural semantic understanding of the vertebrae, we also propose a novel spinal shape prior module that captures specific anatomical information of the spine from medical images, significantly enhancing the model's ability to extract structural semantic information of the vertebrae. Comparative and ablation experiments on two datasets demonstrate that SpineMamba outperforms existing state-of-the-art models. On the CT dataset, the average Dice similarity coefficient for segmentation reaches as high as 94.40, while on the MR dataset, it reaches 86.95. Notably, compared to the renowned nnU-Net, SpineMamba achieves superior segmentation performance, exceeding it by up to 2 percentage points. This underscores its accuracy, robustness, and excellent generalization capabilities.
Introducing Shape Prior Module in Diffusion Model for Medical Image Segmentation
Sep 12, 2023



Medical image segmentation is critical for diagnosing and treating spinal disorders. However, the presence of high noise, ambiguity, and uncertainty makes this task highly challenging. Factors such as unclear anatomical boundaries, inter-class similarities, and irrational annotations contribute to this challenge. Achieving both accurate and diverse segmentation templates is essential to support radiologists in clinical practice. In recent years, denoising diffusion probabilistic modeling (DDPM) has emerged as a prominent research topic in computer vision. It has demonstrated effectiveness in various vision tasks, including image deblurring, super-resolution, anomaly detection, and even semantic representation generation at the pixel level. Despite the robustness of existing diffusion models in visual generation tasks, they still struggle with discrete masks and their various effects. To address the need for accurate and diverse spine medical image segmentation templates, we propose an end-to-end framework called VerseDiff-UNet, which leverages the denoising diffusion probabilistic model (DDPM). Our approach integrates the diffusion model into a standard U-shaped architecture. At each step, we combine the noise-added image with the labeled mask to guide the diffusion direction accurately towards the target region. Furthermore, to capture specific anatomical a priori information in medical images, we incorporate a shape a priori module. This module efficiently extracts structural semantic information from the input spine images. We evaluate our method on a single dataset of spine images acquired through X-ray imaging. Our results demonstrate that VerseDiff-UNet significantly outperforms other state-of-the-art methods in terms of accuracy while preserving the natural features and variations of anatomy.