 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvolutionary Action Selection for Gradient-based Policy Learning
Jan 20, 2022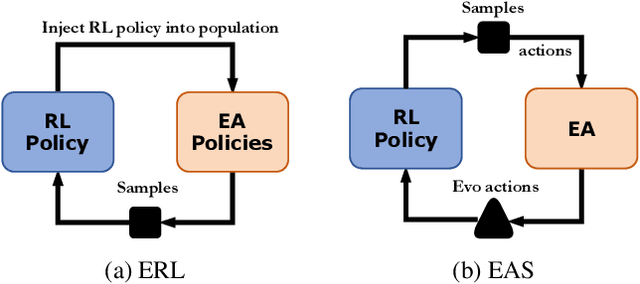
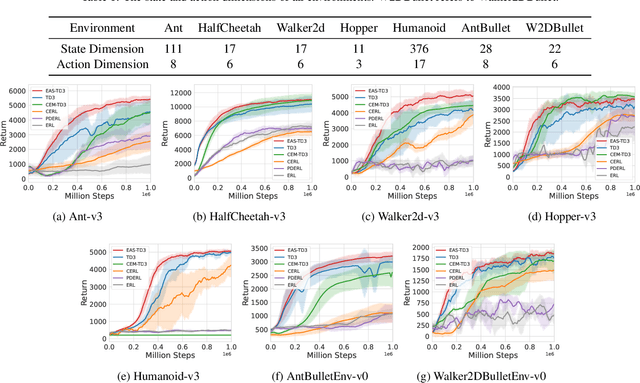
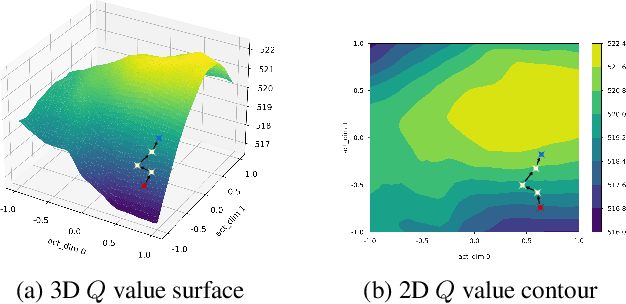
Evolutionary Algorithms (EAs) and Deep Reinforcement Learning (DRL) have recently been combined to integrate the advantages of the two solutions for better policy learning. However, in existing hybrid methods, EA is used to directly train the policy network, which will lead to sample inefficiency and unpredictable impact on the policy performance. To better integrate these two approaches and avoid the drawbacks caused by the introduction of EA, we devote ourselves to devising a more efficient and reasonable method of combining EA and DRL. In this paper, we propose Evolutionary Action Selection-Twin Delayed Deep Deterministic Policy Gradient (EAS-TD3), a novel combination of EA and DRL. In EAS, we focus on optimizing the action chosen by the policy network and attempt to obtain high-quality actions to guide policy learning through an evolutionary algorithm. We conduct several experiments on challenging continuous control tasks. The result shows that EAS-TD3 shows superior performance over other state-of-art methods.