 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpen-Ended Diverse Solution Discovery with Regulated Behavior Patterns for Cross-Domain Adaptation
Sep 24, 2022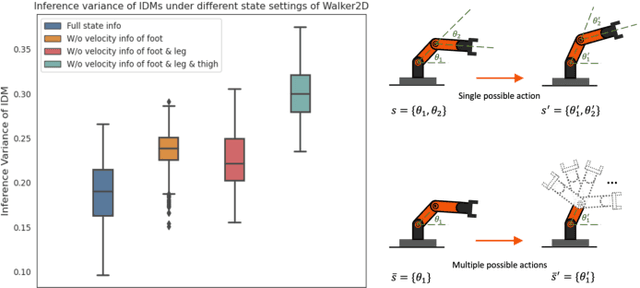
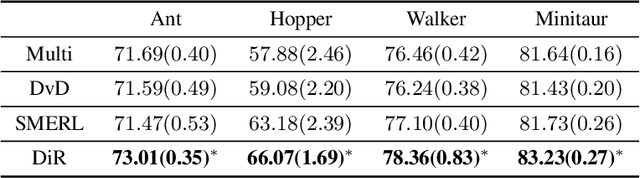
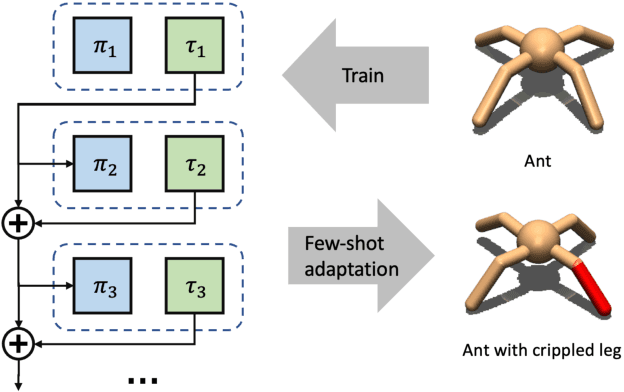
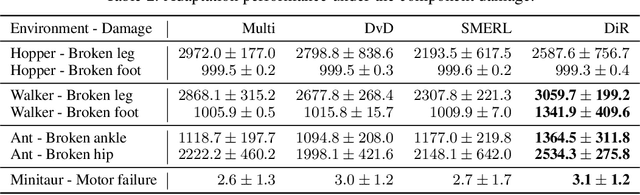
While Reinforcement Learning can achieve impressive results for complex tasks, the learned policies are generally prone to fail in downstream tasks with even minor model mismatch or unexpected perturbations. Recent works have demonstrated that a policy population with diverse behavior characteristics can generalize to downstream environments with various discrepancies. However, such policies might result in catastrophic damage during the deployment in practical scenarios like real-world systems due to the unrestricted behaviors of trained policies. Furthermore, training diverse policies without regulation of the behavior can result in inadequate feasible policies for extrapolating to a wide range of test conditions with dynamics shifts. In this work, we aim to train diverse policies under the regularization of the behavior patterns. We motivate our paradigm by observing the inverse dynamics in the environment with partial state information and propose Diversity in Regulation(DiR) training diverse policies with regulated behaviors to discover desired patterns that benefit the generalization. Considerable empirical results on various variations of different environments indicate that our method attains improvements over other diversity-driven counterparts.
Evolutionary Action Selection for Gradient-based Policy Learning
Jan 20, 2022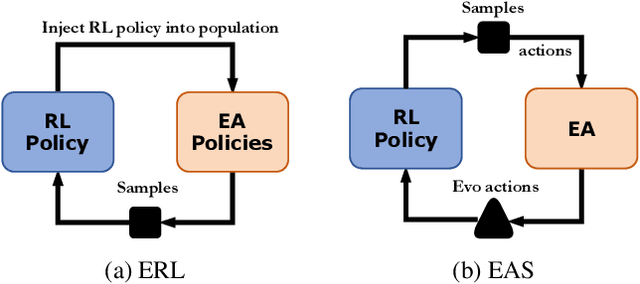
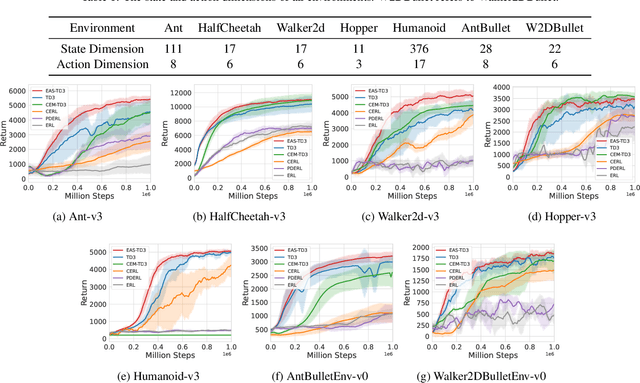
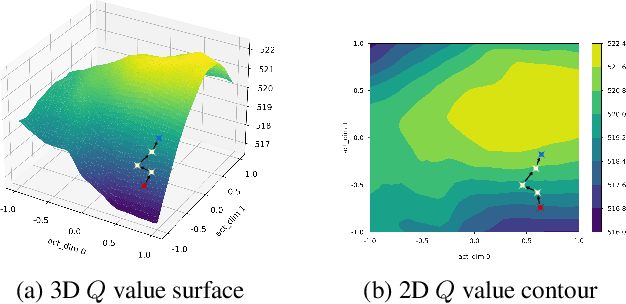
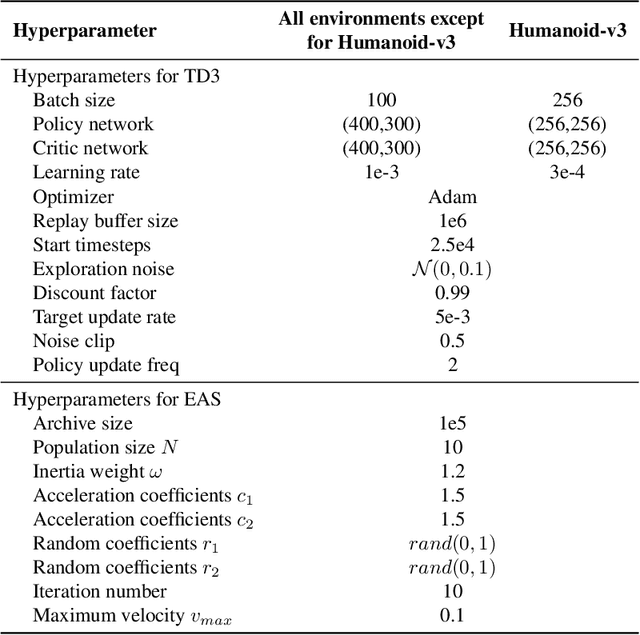
Evolutionary Algorithms (EAs) and Deep Reinforcement Learning (DRL) have recently been combined to integrate the advantages of the two solutions for better policy learning. However, in existing hybrid methods, EA is used to directly train the policy network, which will lead to sample inefficiency and unpredictable impact on the policy performance. To better integrate these two approaches and avoid the drawbacks caused by the introduction of EA, we devote ourselves to devising a more efficient and reasonable method of combining EA and DRL. In this paper, we propose Evolutionary Action Selection-Twin Delayed Deep Deterministic Policy Gradient (EAS-TD3), a novel combination of EA and DRL. In EAS, we focus on optimizing the action chosen by the policy network and attempt to obtain high-quality actions to guide policy learning through an evolutionary algorithm. We conduct several experiments on challenging continuous control tasks. The result shows that EAS-TD3 shows superior performance over other state-of-art methods.