 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSymbol Grounding Association in Multimodal Sequences with Missing Elements
Dec 07, 2017



In this paper, we extend a symbolic association framework for being able to handle missing elements in multimodal sequences. The general scope of the work is the symbolic associations of object-word mappings as it happens in language development in infants. In other words, two different representations of the same abstract concepts can associate in both directions. This scenario has been long interested in Artificial Intelligence, Psychology, and Neuroscience. In this work, we extend a recent approach for multimodal sequences (visual and audio) to also cope with missing elements in one or both modalities. Our method uses two parallel Long Short-Term Memories (LSTMs) with a learning rule based on EM-algorithm. It aligns both LSTM outputs via Dynamic Time Warping (DTW). We propose to include an extra step for the combination with the max operation for exploiting the common elements between both sequences. The motivation behind is that the combination acts as a condition selector for choosing the best representation from both LSTMs. We evaluated the proposed extension in the following scenarios: missing elements in one modality (visual or audio) and missing elements in both modalities (visual and sound). The performance of our extension reaches better results than the original model and similar results to individual LSTM trained in each modality.
Active Canny: Edge Detection and Recovery with Open Active Contour Models
Sep 12, 2016



We introduce an edge detection and recovery framework based on open active contour models (snakelets). This is motivated by the noisy or broken edges output by standard edge detection algorithms, like Canny. The idea is to utilize the local continuity and smoothness cues provided by strong edges and grow them to recover the missing edges. This way, the strong edges are used to recover weak or missing edges by considering the local edge structures, instead of blindly linking them if gradient magnitudes are above some threshold. We initialize short snakelets on the gradient magnitudes or binary edges automatically and then deform and grow them under the influence of gradient vector flow. The output snakelets are able to recover most of the breaks or weak edges, and they provide a smooth edge representation of the image; they can also be used for higher level analysis, like contour segmentation.
Possible Mechanisms for Neural Reconfigurability and their Implications
Aug 12, 2015The paper introduces a biologically and evolutionarily plausible neural architecture that allows a single group of neurons, or an entire cortical pathway, to be dynamically reconfigured to perform multiple, potentially very different computations. The paper shows that reconfigurability can account for the observed stochastic and distributed coding behavior of neurons and provides a parsimonious explanation for timing phenomena in psychophysical experiments. It also shows that reconfigurable pathways correspond to classes of statistical classifiers that include decision lists, decision trees, and hierarchical Bayesian methods. Implications for the interpretation of neurophysiological and psychophysical results are discussed, and future experiments for testing the reconfigurability hypothesis are explored.
On the Convergence of SGD Training of Neural Networks
Aug 12, 2015



Neural networks are usually trained by some form of stochastic gradient descent (SGD)). A number of strategies are in common use intended to improve SGD optimization, such as learning rate schedules, momentum, and batching. These are motivated by ideas about the occurrence of local minima at different scales, valleys, and other phenomena in the objective function. Empirical results presented here suggest that these phenomena are not significant factors in SGD optimization of MLP-related objective functions, and that the behavior of stochastic gradient descent in these problems is better described as the simultaneous convergence at different rates of many, largely non-interacting subproblems
The Effects of Hyperparameters on SGD Training of Neural Networks
Aug 12, 2015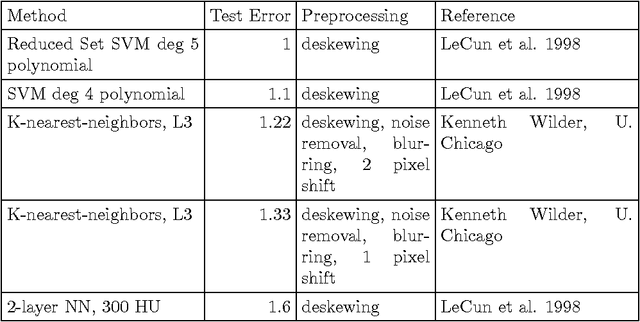



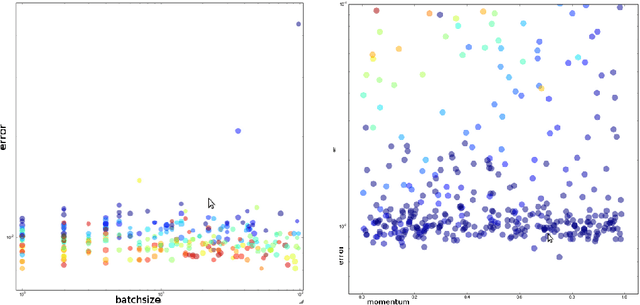
The performance of neural network classifiers is determined by a number of hyperparameters, including learning rate, batch size, and depth. A number of attempts have been made to explore these parameters in the literature, and at times, to develop methods for optimizing them. However, exploration of parameter spaces has often been limited. In this note, I report the results of large scale experiments exploring these different parameters and their interactions.
Benchmarking of LSTM Networks
Aug 11, 2015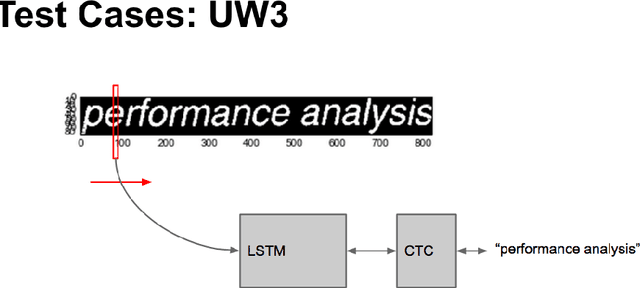
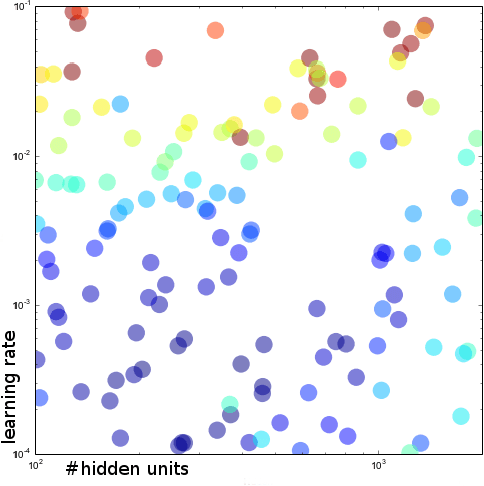
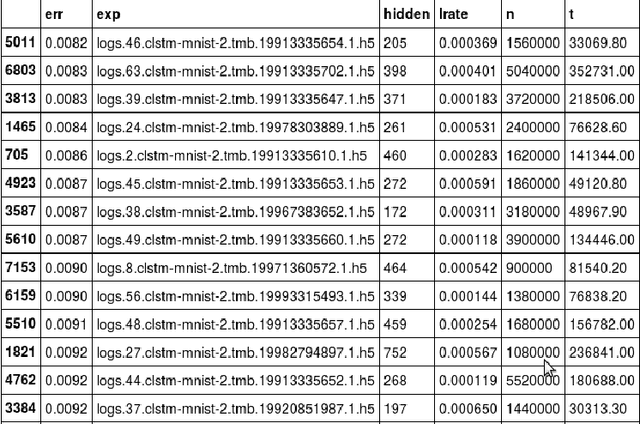
LSTM (Long Short-Term Memory) recurrent neural networks have been highly successful in a number of application areas. This technical report describes the use of the MNIST and UW3 databases for benchmarking LSTM networks and explores the effect of different architectural and hyperparameter choices on performance. Significant findings include: (1) LSTM performance depends smoothly on learning rates, (2) batching and momentum has no significant effect on performance, (3) softmax training outperforms least square training, (4) peephole units are not useful, (5) the standard non-linearities (tanh and sigmoid) perform best, (6) bidirectional training combined with CTC performs better than other methods.
View Based Methods can achieve Bayes-Optimal 3D Recognition
Dec 02, 2007This paper proves that visual object recognition systems using only 2D Euclidean similarity measurements to compare object views against previously seen views can achieve the same recognition performance as observers having access to all coordinate information and able of using arbitrary 3D models internally. Furthermore, it demonstrates that such systems do not require more training views than Bayes-optimal 3D model-based systems. For building computer vision systems, these results imply that using view-based or appearance-based techniques with carefully constructed combination of evidence mechanisms may not be at a disadvantage relative to 3D model-based systems. For computational approaches to human vision, they show that it is impossible to distinguish view-based and 3D model-based techniques for 3D object recognition solely by comparing the performance achievable by human and 3D model-based systems.}
Learning View Generalization Functions
Dec 02, 2007


Learning object models from views in 3D visual object recognition is usually formulated either as a function approximation problem of a function describing the view-manifold of an object, or as that of learning a class-conditional density. This paper describes an alternative framework for learning in visual object recognition, that of learning the view-generalization function. Using the view-generalization function, an observer can perform Bayes-optimal 3D object recognition given one or more 2D training views directly, without the need for a separate model acquisition step. The paper shows that view generalization functions can be computationally practical by restating two widely-used methods, the eigenspace and linear combination of views approaches, in a view generalization framework. The paper relates the approach to recent methods for object recognition based on non-uniform blurring. The paper presents results both on simulated 3D ``paperclip'' objects and real-world images from the COIL-100 database showing that useful view-generalization functions can be realistically be learned from a comparatively small number of training examples.
Learning Similarity for Character Recognition and 3D Object Recognition
Dec 02, 2007



I describe an approach to similarity motivated by Bayesian methods. This yields a similarity function that is learnable using a standard Bayesian methods. The relationship of the approach to variable kernel and variable metric methods is discussed. The approach is related to variable kernel Experimental results on character recognition and 3D object recognition are presented..
On the Relationship between the Posterior and Optimal Similarity
Dec 02, 2007For a classification problem described by the joint density $P(\omega,x)$, models of $P(\omega\eq\omega'|x,x')$ (the ``Bayesian similarity measure'') have been shown to be an optimal similarity measure for nearest neighbor classification. This paper analyzes demonstrates several additional properties of that conditional distribution. The paper first shows that we can reconstruct, up to class labels, the class posterior distribution $P(\omega|x)$ given $P(\omega\eq\omega'|x,x')$, gives a procedure for recovering the class labels, and gives an asymptotically Bayes-optimal classification procedure. It also shows, given such an optimal similarity measure, how to construct a classifier that outperforms the nearest neighbor classifier and achieves Bayes-optimal classification rates. The paper then analyzes Bayesian similarity in a framework where a classifier faces a number of related classification tasks (multitask learning) and illustrates that reconstruction of the class posterior distribution is not possible in general. Finally, the paper identifies a distinct class of classification problems using $P(\omega\eq\omega'|x,x')$ and shows that using $P(\omega\eq\omega'|x,x')$ to solve those problems is the Bayes optimal solution.