Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking of LSTM Networks
Paper and Code
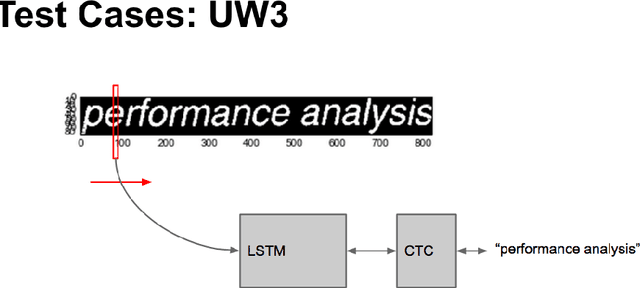
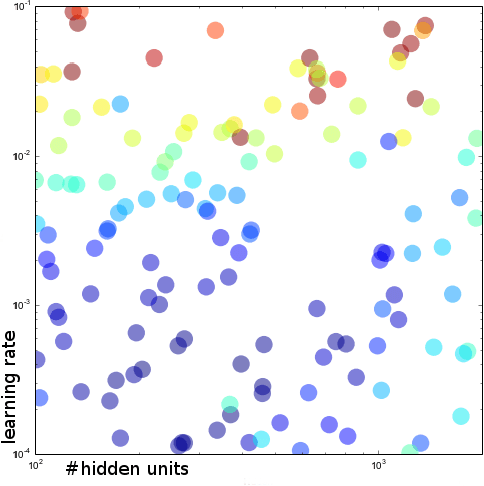
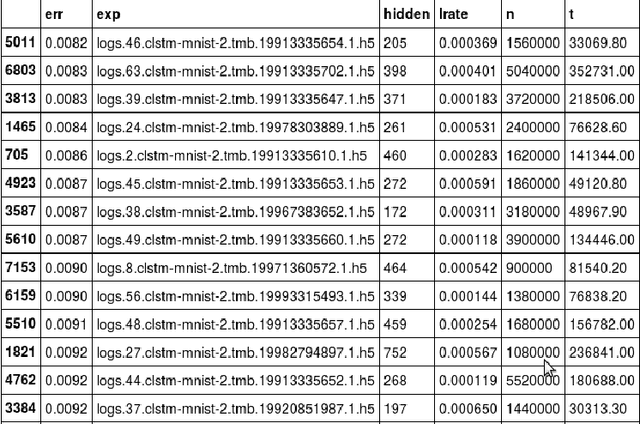
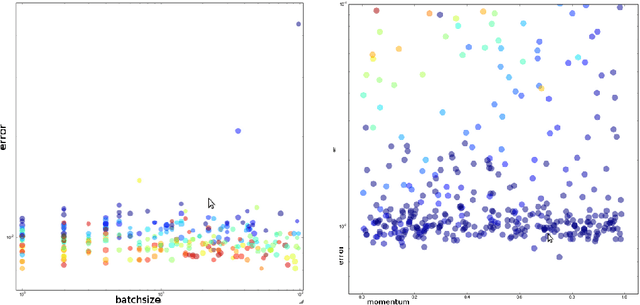
LSTM (Long Short-Term Memory) recurrent neural networks have been highly successful in a number of application areas. This technical report describes the use of the MNIST and UW3 databases for benchmarking LSTM networks and explores the effect of different architectural and hyperparameter choices on performance. Significant findings include: (1) LSTM performance depends smoothly on learning rates, (2) batching and momentum has no significant effect on performance, (3) softmax training outperforms least square training, (4) peephole units are not useful, (5) the standard non-linearities (tanh and sigmoid) perform best, (6) bidirectional training combined with CTC performs better than other methods.
View paper on