 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBackground-Foreground Segmentation for Interior Sensing in Automotive Industry
Sep 20, 2021


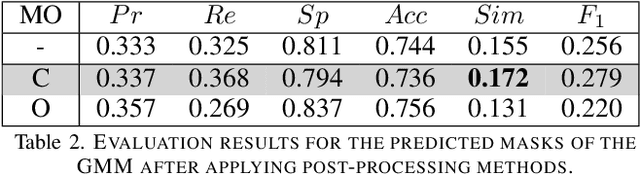
To ensure safety in automated driving, the correct perception of the situation inside the car is as important as its environment. Thus, seat occupancy detection and classification of detected instances play an important role in interior sensing. By the knowledge of the seat occupancy status, it is possible to, e.g., automate the airbag deployment control. Furthermore, the presence of a driver, which is necessary for partially automated driving cars at the automation levels two to four can be verified. In this work, we compare different statistical methods from the field of image segmentation to approach the problem of background-foreground segmentation in camera based interior sensing. In the recent years, several methods based on different techniques have been developed and applied to images or videos from different applications. The peculiarity of the given scenarios of interior sensing is, that the foreground instances and the background both contain static as well as dynamic elements. In data considered in this work, even the camera position is not completely fixed. We review and benchmark three different methods ranging, i.e., Gaussian Mixture Models (GMM), Morphological Snakes and a deep neural network, namely a Mask R-CNN. In particular, the limitations of the classical methods, GMM and Morphological Snakes, for interior sensing are shown. Furthermore, it turns, that it is possible to overcome these limitations by deep learning, e.g.\ using a Mask R-CNN. Although only a small amount of ground truth data was available for training, we enabled the Mask R-CNN to produce high quality background-foreground masks via transfer learning. Moreover, we demonstrate that certain augmentation as well as pre- and post-processing methods further enhance the performance of the investigated methods.
PrognoseNet: A Generative Probabilistic Framework for Multimodal Position Prediction given Context Information
Oct 02, 2020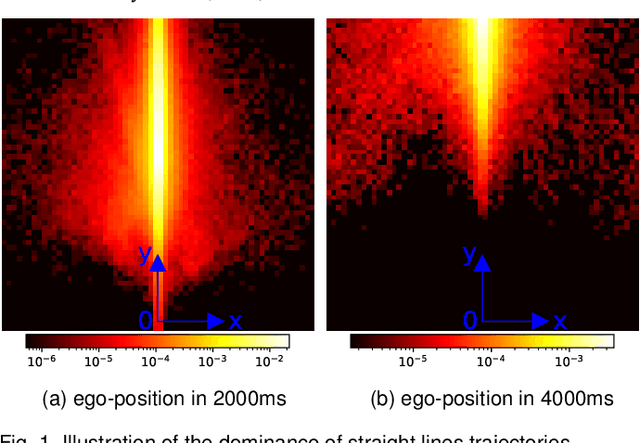



The ability to predict multiple possible future positions of the ego-vehicle given the surrounding context while also estimating their probabilities is key to safe autonomous driving. Most of the current state-of-the-art Deep Learning approaches are trained on trajectory data to achieve this task. However trajectory data captured by sensor systems is highly imbalanced, since by far most of the trajectories follow straight lines with an approximately constant velocity. This poses a huge challenge for the task of predicting future positions, which is inherently a regression problem. Current state-of-the-art approaches alleviate this problem only by major preprocessing of the training data, e.g. resampling, clustering into anchors etc. In this paper we propose an approach which reformulates the prediction problem as a classification task, allowing for powerful tools, e.g. focal loss, to combat the imbalance. To this end we design a generative probabilistic model consisting of a deep neural network with a Mixture of Gaussian head. A smart choice of the latent variable allows for the reformulation of the log-likelihood function as a combination of a classification problem and a much simplified regression problem. The output of our model is an estimate of the probability density function of future positions, hence allowing for prediction of multiple possible positions while also estimating their probabilities. The proposed approach can easily incorporate context information and does not require any preprocessing of the data.
RetinotopicNet: An Iterative Attention Mechanism Using Local Descriptors with Global Context
May 12, 2020



Convolutional Neural Networks (CNNs) were the driving force behind many advancements in Computer Vision research in recent years. This progress has spawned many practical applications and we see an increased need to efficiently move CNNs to embedded systems today. However traditional CNNs lack the property of scale and rotation invariance: two of the most frequently encountered transformations in natural images. As a consequence CNNs have to learn different features for same objects at different scales. This redundancy is the main reason why CNNs need to be very deep in order to achieve the desired accuracy. In this paper we develop an efficient solution by reproducing how nature has solved the problem in the human brain. To this end we let our CNN operate on small patches extracted using the log-polar transform, which is known to be scale and rotation equivariant. Patches extracted in this way have the nice property of magnifying the central field and compressing the periphery. Hence we obtain local descriptors with global context information. However the processing of a single patch is usually not sufficient to achieve high accuracies in e.g. classification tasks. We therefore successively jump to several different locations, called saccades, thus building an understanding of the whole image. Since log-polar patches contain global context information, we can efficiently calculate following saccades using only the small patches. Saccades efficiently compensate for the lack of translation equivariance of the log-polar transform.
Training of Deep Neural Networks based on Distance Measures using RMSProp
Aug 06, 2017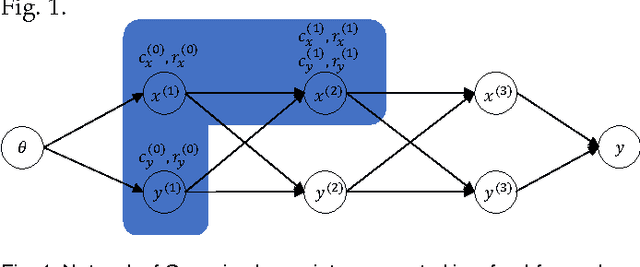



The vanishing gradient problem was a major obstacle for the success of deep learning. In recent years it was gradually alleviated through multiple different techniques. However the problem was not really overcome in a fundamental way, since it is inherent to neural networks with activation functions based on dot products. In a series of papers, we are going to analyze alternative neural network structures which are not based on dot products. In this first paper, we revisit neural networks built up of layers based on distance measures and Gaussian activation functions. These kinds of networks were only sparsely used in the past since they are hard to train when using plain stochastic gradient descent methods. We show that by using Root Mean Square Propagation (RMSProp) it is possible to efficiently learn multi-layer neural networks. Furthermore we show that when appropriately initialized these kinds of neural networks suffer much less from the vanishing and exploding gradient problem than traditional neural networks even for deep networks.