 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReformulating AI-based Multi-Object Relative State Estimation for Aleatoric Uncertainty-based Outlier Rejection of Partial Measurements
Feb 02, 2026Precise localization with respect to a set of objects of interest enables mobile robots to perform various tasks. With the rise of edge devices capable of deploying deep neural networks (DNNs) for real-time inference, it stands to reason to use artificial intelligence (AI) for the extraction of object-specific, semantic information from raw image data, such as the object class and the relative six degrees of freedom (6-DoF) pose. However, fusing such AI-based measurements in an Extended Kalman Filter (EKF) requires quantifying the DNNs' uncertainty and outlier rejection capabilities. This paper presents the benefits of reformulating the measurement equation in AI-based, object-relative state estimation. By deriving an EKF using the direct object-relative pose measurement, we can decouple the position and rotation measurements, thus limiting the influence of erroneous rotation measurements and allowing partial measurement rejection. Furthermore, we investigate the performance and consistency improvements for state estimators provided by replacing the fixed measurement covariance matrix of the 6-DoF object-relative pose measurements with the predicted aleatoric uncertainty of the DNN.
CaRoSaC: A Reinforcement Learning-Based Kinematic Control of Cable-Driven Parallel Robots by Addressing Cable Sag through Simulation
Apr 22, 2025This paper introduces the Cable Robot Simulation and Control (CaRoSaC) Framework, which integrates a simulation environment with a model-free reinforcement learning control methodology for suspended Cable-Driven Parallel Robots (CDPRs), accounting for cable sag. Our approach seeks to bridge the knowledge gap of the intricacies of CDPRs due to aspects such as cable sag and precision control necessities by establishing a simulation platform that captures the real-world behaviors of CDPRs, including the impacts of cable sag. The framework offers researchers and developers a tool to further develop estimation and control strategies within the simulation for understanding and predicting the performance nuances, especially in complex operations where cable sag can be significant. Using this simulation framework, we train a model-free control policy in Reinforcement Learning (RL). This approach is chosen for its capability to adaptively learn from the complex dynamics of CDPRs. The policy is trained to discern optimal cable control inputs, ensuring precise end-effector positioning. Unlike traditional feedback-based control methods, our RL control policy focuses on kinematic control and addresses the cable sag issues without being tethered to predefined mathematical models. We also demonstrate that our RL-based controller, coupled with the flexible cable simulation, significantly outperforms the classical kinematics approach, particularly in dynamic conditions and near the boundary regions of the workspace. The combined strength of the described simulation and control approach offers an effective solution in manipulating suspended CDPRs even at workspace boundary conditions where traditional approach fails, as proven from our experiments, ensuring that CDPRs function optimally in various applications while accounting for the often neglected but critical factor of cable sag.
AIVIO: Closed-loop, Object-relative Navigation of UAVs with AI-aided Visual Inertial Odometry
Oct 08, 2024



Object-relative mobile robot navigation is essential for a variety of tasks, e.g. autonomous critical infrastructure inspection, but requires the capability to extract semantic information about the objects of interest from raw sensory data. While deep learning-based (DL) methods excel at inferring semantic object information from images, such as class and relative 6 degree of freedom (6-DoF) pose, they are computationally demanding and thus often not suitable for payload constrained mobile robots. In this letter we present a real-time capable unmanned aerial vehicle (UAV) system for object-relative, closed-loop navigation with a minimal sensor configuration consisting of an inertial measurement unit (IMU) and RGB camera. Utilizing a DL-based object pose estimator, solely trained on synthetic data and optimized for companion board deployment, the object-relative pose measurements are fused with the IMU data to perform object-relative localization. We conduct multiple real-world experiments to validate the performance of our system for the challenging use case of power pole inspection. An example closed-loop flight is presented in the supplementary video.
AI-Based Multi-Object Relative State Estimation with Self-Calibration Capabilities
Mar 01, 2023


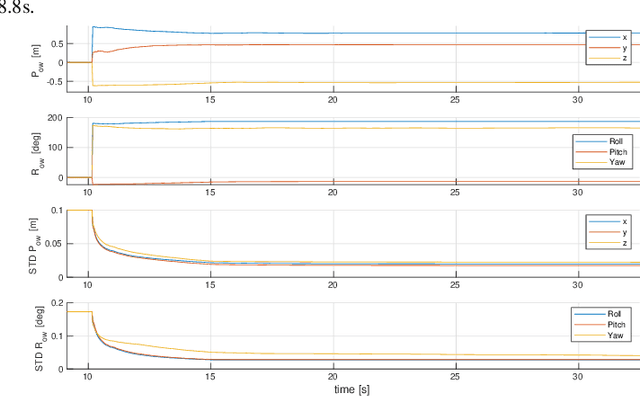
The capability to extract task specific, semantic information from raw sensory data is a crucial requirement for many applications of mobile robotics. Autonomous inspection of critical infrastructure with Unmanned Aerial Vehicles (UAVs), for example, requires precise navigation relative to the structure that is to be inspected. Recently, Artificial Intelligence (AI)-based methods have been shown to excel at extracting semantic information such as 6 degree-of-freedom (6-DoF) poses of objects from images. In this paper, we propose a method combining a state-of-the-art AI-based pose estimator for objects in camera images with data from an inertial measurement unit (IMU) for 6-DoF multi-object relative state estimation of a mobile robot. The AI-based pose estimator detects multiple objects of interest in camera images along with their relative poses. These measurements are fused with IMU data in a state-of-the-art sensor fusion framework. We illustrate the feasibility of our proposed method with real world experiments for different trajectories and number of arbitrarily placed objects. We show that the results can be reliably reproduced due to the self-calibrating capabilities of our approach.
PoET: Pose Estimation Transformer for Single-View, Multi-Object 6D Pose Estimation
Nov 25, 2022



Accurate 6D object pose estimation is an important task for a variety of robotic applications such as grasping or localization. It is a challenging task due to object symmetries, clutter and occlusion, but it becomes more challenging when additional information, such as depth and 3D models, is not provided. We present a transformer-based approach that takes an RGB image as input and predicts a 6D pose for each object in the image. Besides the image, our network does not require any additional information such as depth maps or 3D object models. First, the image is passed through an object detector to generate feature maps and to detect objects. Then, the feature maps are fed into a transformer with the detected bounding boxes as additional information. Afterwards, the output object queries are processed by a separate translation and rotation head. We achieve state-of-the-art results for RGB-only approaches on the challenging YCB-V dataset. We illustrate the suitability of the resulting model as pose sensor for a 6-DoF state estimation task. Code is available at https://github.com/aau-cns/poet.