 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCorrecting and Quantifying Systematic Errors in 3D Box Annotations for Autonomous Driving
Jan 20, 2026Accurate ground truth annotations are critical to supervised learning and evaluating the performance of autonomous vehicle systems. These vehicles are typically equipped with active sensors, such as LiDAR, which scan the environment in predefined patterns. 3D box annotation based on data from such sensors is challenging in dynamic scenarios, where objects are observed at different timestamps, hence different positions. Without proper handling of this phenomenon, systematic errors are prone to being introduced in the box annotations. Our work is the first to discover such annotation errors in widely used, publicly available datasets. Through our novel offline estimation method, we correct the annotations so that they follow physically feasible trajectories and achieve spatial and temporal consistency with the sensor data. For the first time, we define metrics for this problem; and we evaluate our method on the Argoverse 2, MAN TruckScenes, and our proprietary datasets. Our approach increases the quality of box annotations by more than 17% in these datasets. Furthermore, we quantify the annotation errors in them and find that the original annotations are misplaced by up to 2.5 m, with highly dynamic objects being the most affected. Finally, we test the impact of the errors in benchmarking and find that the impact is larger than the improvements that state-of-the-art methods typically achieve with respect to the previous state-of-the-art methods; showing that accurate annotations are essential for correct interpretation of performance. Our code is available at https://github.com/alexandre-justo-miro/annotation-correction-3D-boxes.
Visual Area Coverage with Attitude-Dependent Camera Footprints by Particle Harvesting
Sep 15, 2019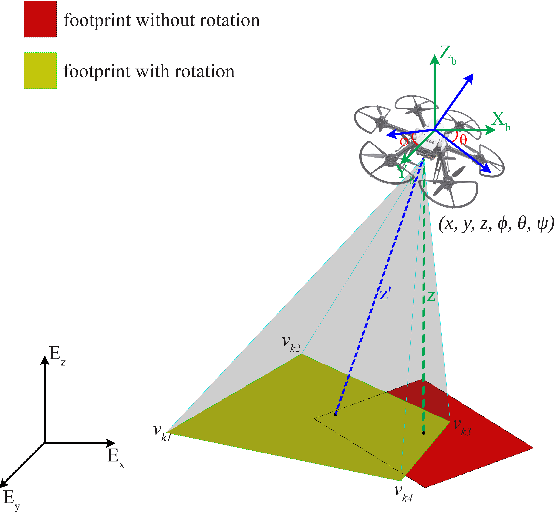


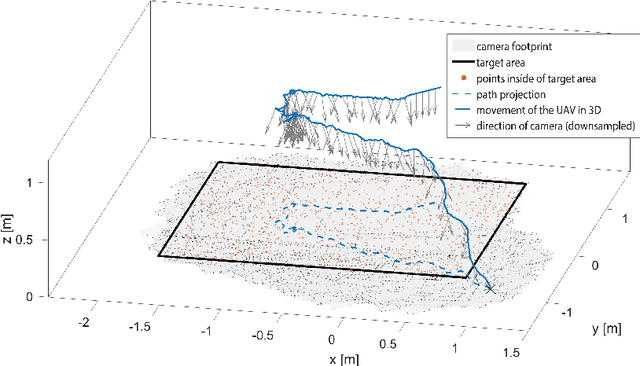
In aerial visual area coverage missions, the camera footprint changes over time based on the camera position and orientation -- a fact that complicates the whole process of coverage and path planning. This article proposes a solution to the problem of visual coverage by filling the target area with a set of randomly distributed particles and harvesting them by camera footprints. This way, high coverage is obtained at a low computational cost. In this approach, the path planner considers six degrees of freedom (DoF) for the camera movement and commands thrust and attitude references to a lower layer controller, while maximizing the covered area and coverage quality. The proposed method requires a priori information of the boundaries of the target area and can handle areas of very complex and highly non-convex geometry. The effectiveness of the approach is demonstrated in multiple simulations in terms of computational efficiency and coverage.