 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn evaluation of time series forecasting models on water consumption data: A case study of Greece
Mar 30, 2023



In recent years, the increased urbanization and industrialization has led to a rising water demand and resources, thus increasing the gap between demand and supply. Proper water distribution and forecasting of water consumption are key factors in mitigating the imbalance of supply and demand by improving operations, planning and management of water resources. To this end, in this paper, several well-known forecasting algorithms are evaluated over time series, water consumption data from Greece, a country with diverse socio-economic and urbanization issues. The forecasting algorithms are evaluated on a real-world dataset provided by the Water Supply and Sewerage Company of Greece revealing key insights about each algorithm and its use.
Intelligent Proactive Fault Tolerance at the Edge through Resource Usage Prediction
Feb 09, 2023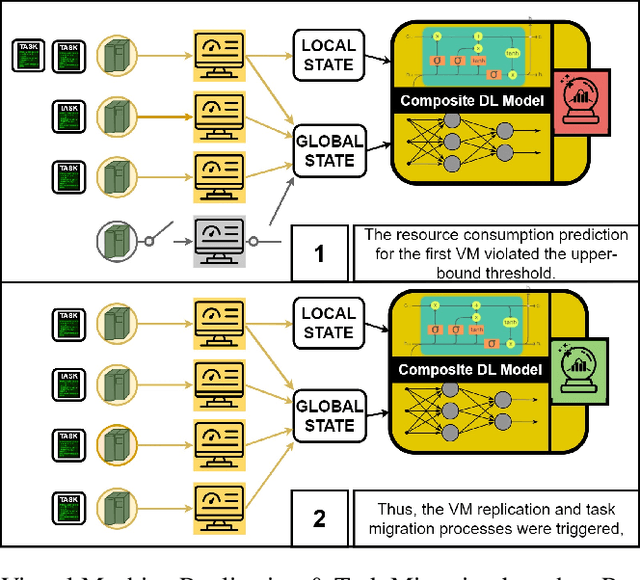
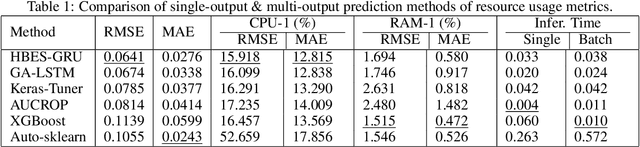
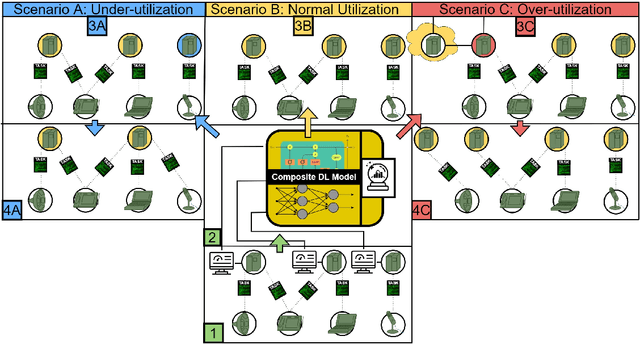
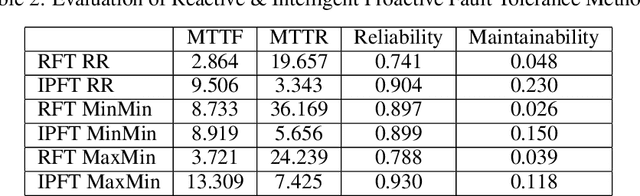
The proliferation of demanding applications and edge computing establishes the need for an efficient management of the underlying computing infrastructures, urging the providers to rethink their operational methods. In this paper, we propose an Intelligent Proactive Fault Tolerance (IPFT) method that leverages the edge resource usage predictions through Recurrent Neural Networks (RNN). More specifically, we focus on the process-faults, which are related with the inability of the infrastructure to provide Quality of Service (QoS) in acceptable ranges due to the lack of processing power. In order to tackle this challenge we propose a composite deep learning architecture that predicts the resource usage metrics of the edge nodes and triggers proactive node replications and task migration. Taking also into consideration that the edge computing infrastructure is also highly dynamic and heterogeneous, we propose an innovative Hybrid Bayesian Evolution Strategy (HBES) algorithm for automated adaptation of the resource usage models. The proposed resource usage prediction mechanism has been experimentally evaluated and compared with other state of the art methods with significant improvements in terms of Root Mean Squared Error (RMSE) and Mean Absolute Error (MAE). Additionally, the IPFT mechanism that leverages the resource usage predictions has been evaluated in an extensive simulation in CloudSim Plus and the results show significant improvement compared to the reactive fault tolerance method in terms of reliability and maintainability.
* Also available in ITU's Journal on Future and Evolving Technologies
Context agnostic trajectory prediction based on $λ$-architecture
Sep 29, 2019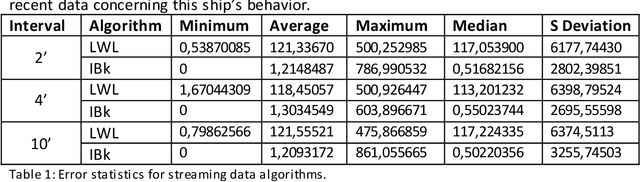
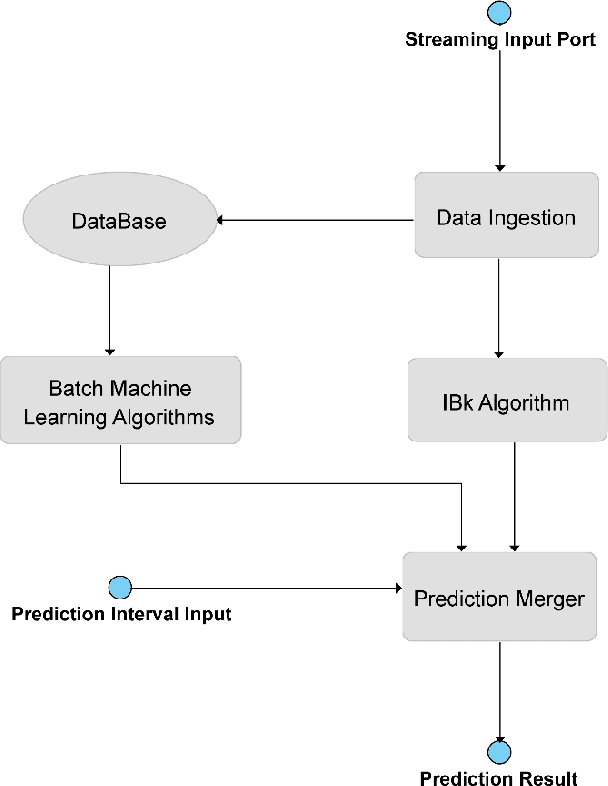
Predicting the next position of movable objects has been a problem for at least the last three decades, referred to as trajectory prediction. In our days, the vast amounts of data being continuously produced add the big data dimension to the trajectory prediction problem, which we are trying to tackle by creating a {\lambda}-Architecture based analytics platform. This platform performs both batch and stream analytics tasks and then combines them to perform analytical tasks that cannot be performed by analyzing any of these layers by itself. The biggest benefit of this platform is its context agnostic trait, which allows us to use it for any use case, as long as a time-stamped geolocation stream is provided. The experimental results presented prove that each part of the {\lambda}-Architecture performs well at certain targets, making a combination of these parts a necessity in order to improve the overall accuracy and performance of the platform.
Employing traditional machine learning algorithms for big data streams analysis: the case of object trajectory prediction
Sep 01, 2016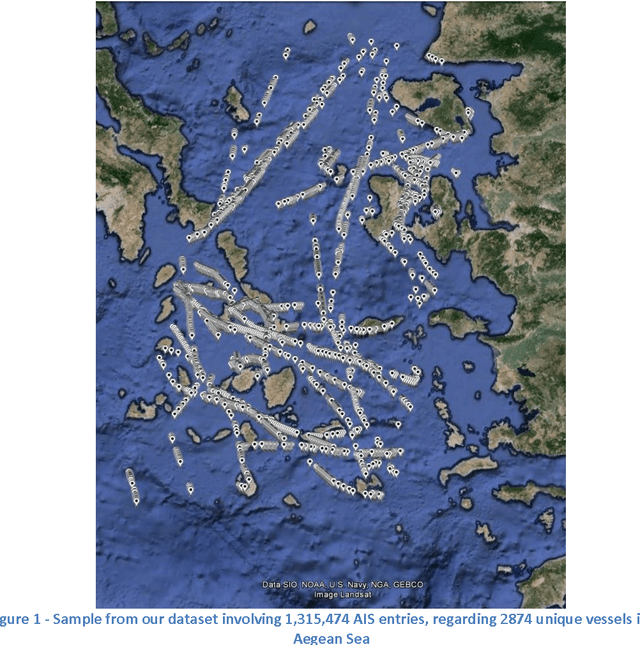
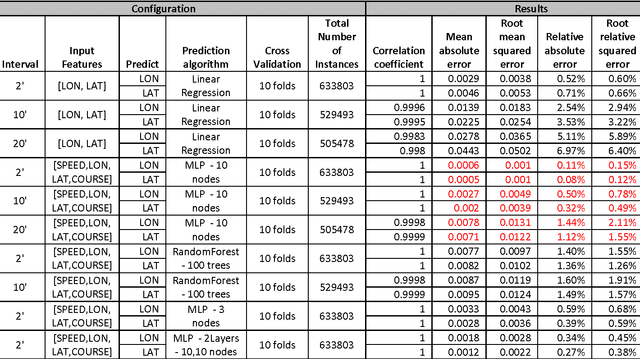


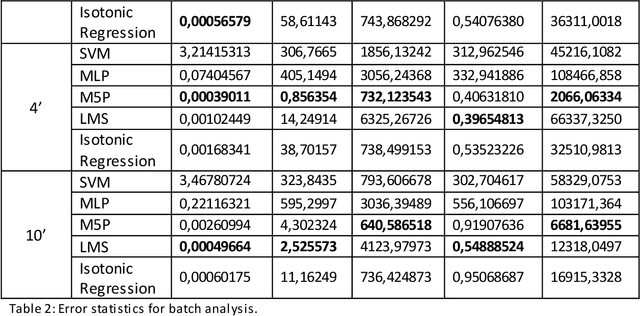
In this paper, we model the trajectory of sea vessels and provide a service that predicts in near-real time the position of any given vessel in 4', 10', 20' and 40' time intervals. We explore the necessary tradeoffs between accuracy, performance and resource utilization are explored given the large volume and update rates of input data. We start with building models based on well-established machine learning algorithms using static datasets and multi-scan training approaches and identify the best candidate to be used in implementing a single-pass predictive approach, under real-time constraints. The results are measured in terms of accuracy and performance and are compared against the baseline kinematic equations. Results show that it is possible to efficiently model the trajectory of multiple vessels using a single model, which is trained and evaluated using an adequately large, static dataset, thus achieving a significant gain in terms of resource usage while not compromising accuracy.
Comparing methods for Twitter Sentiment Analysis
May 12, 2015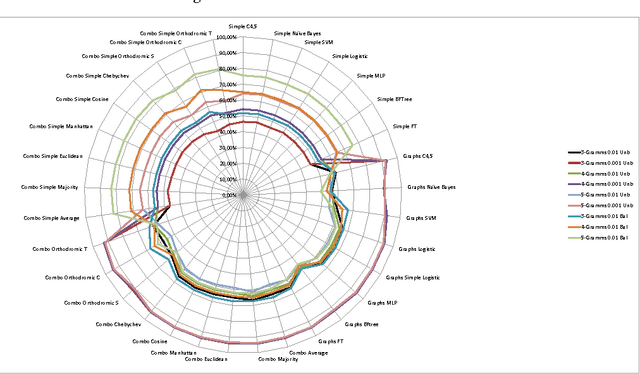
This work extends the set of works which deal with the popular problem of sentiment analysis in Twitter. It investigates the most popular document ("tweet") representation methods which feed sentiment evaluation mechanisms. In particular, we study the bag-of-words, n-grams and n-gram graphs approaches and for each of them we evaluate the performance of a lexicon-based and 7 learning-based classification algorithms (namely SVM, Na\"ive Bayesian Networks, Logistic Regression, Multilayer Perceptrons, Best-First Trees, Functional Trees and C4.5) as well as their combinations, using a set of 4451 manually annotated tweets. The results demonstrate the superiority of learning-based methods and in particular of n-gram graphs approaches for predicting the sentiment of tweets. They also show that the combinatory approach has impressive effects on n-grams, raising the confidence up to 83.15% on the 5-Grams, using majority vote and a balanced dataset (equal number of positive, negative and neutral tweets for training). In the n-gram graph cases the improvement was small to none, reaching 94.52% on the 4-gram graphs, using Orthodromic distance and a threshold of 0.001.