 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContext agnostic trajectory prediction based on $λ$-architecture
Sep 29, 2019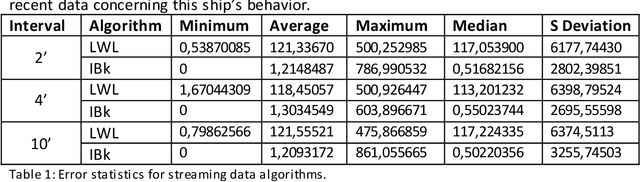
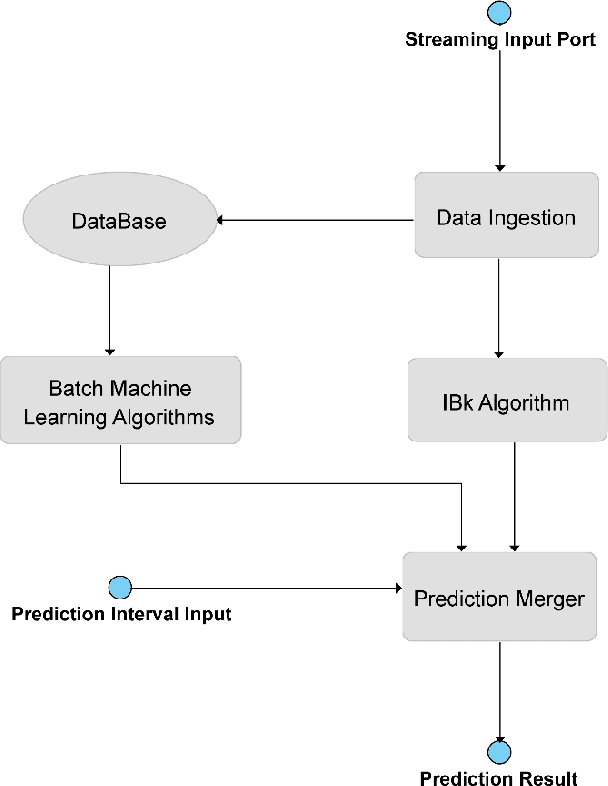
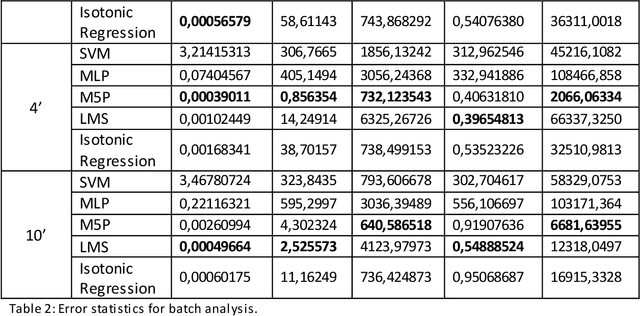
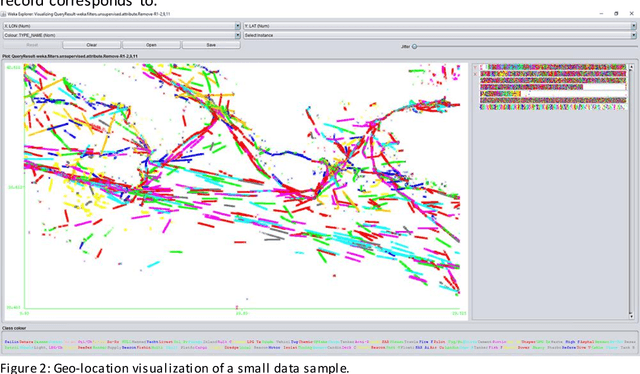
Predicting the next position of movable objects has been a problem for at least the last three decades, referred to as trajectory prediction. In our days, the vast amounts of data being continuously produced add the big data dimension to the trajectory prediction problem, which we are trying to tackle by creating a {\lambda}-Architecture based analytics platform. This platform performs both batch and stream analytics tasks and then combines them to perform analytical tasks that cannot be performed by analyzing any of these layers by itself. The biggest benefit of this platform is its context agnostic trait, which allows us to use it for any use case, as long as a time-stamped geolocation stream is provided. The experimental results presented prove that each part of the {\lambda}-Architecture performs well at certain targets, making a combination of these parts a necessity in order to improve the overall accuracy and performance of the platform.
Big IoT and social networking data for smart cities: Algorithmic improvements on Big Data Analysis in the context of RADICAL city applications
Jul 02, 2016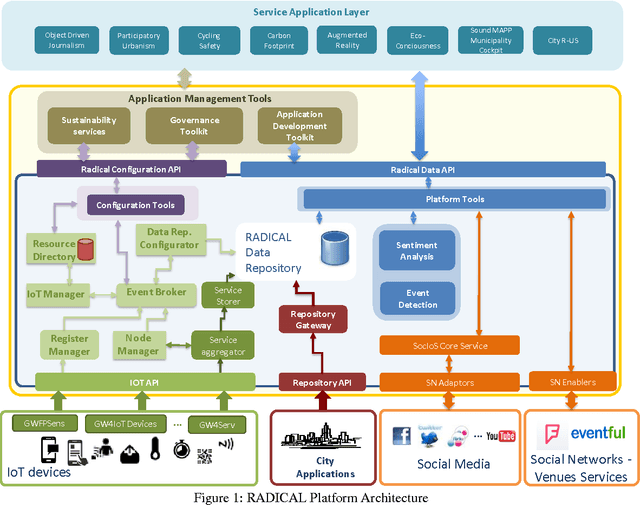
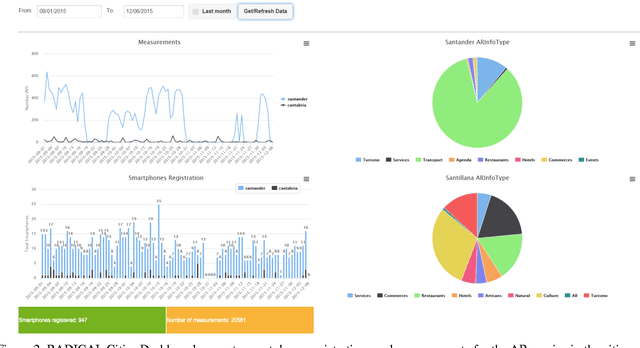
In this paper we present a SOA (Service Oriented Architecture)-based platform, enabling the retrieval and analysis of big datasets stemming from social networking (SN) sites and Internet of Things (IoT) devices, collected by smart city applications and socially-aware data aggregation services. A large set of city applications in the areas of Participating Urbanism, Augmented Reality and Sound-Mapping throughout participating cities is being applied, resulting into produced sets of millions of user-generated events and online SN reports fed into the RADICAL platform. Moreover, we study the application of data analytics such as sentiment analysis to the combined IoT and SN data saved into an SQL database, further investigating algorithmic and configurations to minimize delays in dataset processing and results retrieval.
Comparing methods for Twitter Sentiment Analysis
May 12, 2015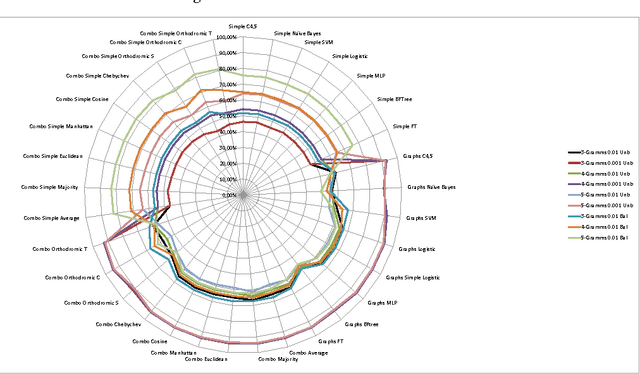
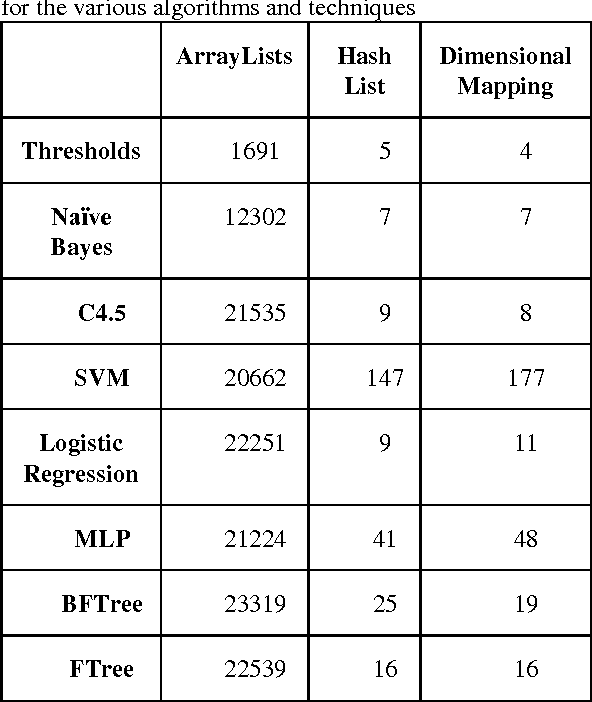
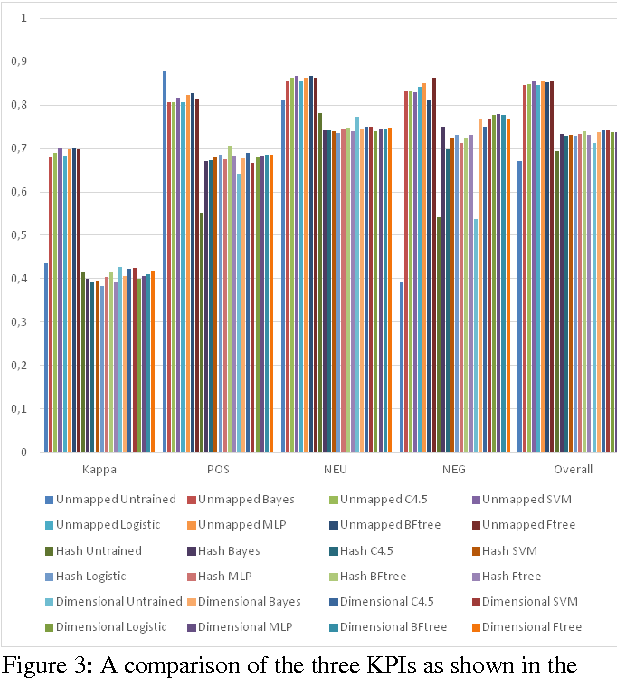
This work extends the set of works which deal with the popular problem of sentiment analysis in Twitter. It investigates the most popular document ("tweet") representation methods which feed sentiment evaluation mechanisms. In particular, we study the bag-of-words, n-grams and n-gram graphs approaches and for each of them we evaluate the performance of a lexicon-based and 7 learning-based classification algorithms (namely SVM, Na\"ive Bayesian Networks, Logistic Regression, Multilayer Perceptrons, Best-First Trees, Functional Trees and C4.5) as well as their combinations, using a set of 4451 manually annotated tweets. The results demonstrate the superiority of learning-based methods and in particular of n-gram graphs approaches for predicting the sentiment of tweets. They also show that the combinatory approach has impressive effects on n-grams, raising the confidence up to 83.15% on the 5-Grams, using majority vote and a balanced dataset (equal number of positive, negative and neutral tweets for training). In the n-gram graph cases the improvement was small to none, reaching 94.52% on the 4-gram graphs, using Orthodromic distance and a threshold of 0.001.