 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReasoning Beyond Bias: A Study on Counterfactual Prompting and Chain of Thought Reasoning
Aug 16, 2024



Language models are known to absorb biases from their training data, leading to predictions driven by statistical regularities rather than semantic relevance. We investigate the impact of these biases on answer choice preferences in the Massive Multi-Task Language Understanding (MMLU) task. Our findings reveal that differences in learned regularities across answer options are predictive of model preferences and mirror human test-taking strategies. To address this issue, we introduce two novel methods: Counterfactual Prompting with Chain of Thought (CoT) and Counterfactual Prompting with Agnostically Primed CoT (APriCoT). We demonstrate that while Counterfactual Prompting with CoT alone is insufficient to mitigate bias, our novel Primed Counterfactual Prompting with CoT approach effectively reduces the influence of base-rate probabilities while improving overall accuracy. Our results suggest that mitigating bias requires a "System-2" like process and that CoT reasoning is susceptible to confirmation bias under some prompting methodologies. Our contributions offer practical solutions for developing more robust and fair language models.
Large Language Model Recall Uncertainty is Modulated by the Fan Effect
Jul 08, 2024



This paper evaluates whether large language models (LLMs) exhibit cognitive fan effects, similar to those discovered by Anderson in humans, after being pre-trained on human textual data. We conduct two sets of in-context recall experiments designed to elicit fan effects. Consistent with human results, we find that LLM recall uncertainty, measured via token probability, is influenced by the fan effect. Our results show that removing uncertainty disrupts the observed effect. The experiments suggest the fan effect is consistent whether the fan value is induced in-context or in the pre-training data. Finally, these findings provide in-silico evidence that fan effects and typicality are expressions of the same phenomena.
The Base-Rate Effect on LLM Benchmark Performance: Disambiguating Test-Taking Strategies from Benchmark Performance
Jun 17, 2024


Cloze testing is a common method for measuring the behavior of large language models on a number of benchmark tasks. Using the MMLU dataset, we show that the base-rate probability (BRP) differences across answer tokens are significant and affect task performance ie. guess A if uncertain. We find that counterfactual prompting does sufficiently mitigate the BRP effect. The BRP effect is found to have a similar effect to test taking strategies employed by humans leading to the conflation of task performance and test-taking ability. We propose the Nvr-X-MMLU task, a variation of MMLU, which helps to disambiguate test-taking ability from task performance and reports the latter.
Domain Adaptation for Robust Workload Classification using fNIRS
Jul 02, 2020
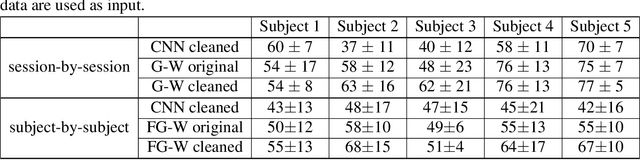


Significance: We demonstrated the potential of using domain adaptation on functional Near-Infrared Spectroscopy (fNIRS) data to detect and discriminate different levels of n-back tasks that involve working memory across different experiment sessions and subjects. Aim: To address the domain shift in fNIRS data across sessions and subjects for task label alignment, we exploited two domain adaptation approaches - Gromov-Wasserstein (G-W) and Fused Gromov-Wasserstein (FG-W). Approach: We applied G-W for session-by-session alignment and FG-W for subject-by-subject alignment with Hellinger distance as underlying metric to fNIRS data acquired during different n-back task levels. We also compared with a supervised method - Convolutional Neural Network (CNN). Results: For session-by-session alignment, using G-W resulted in alignment accuracy of 70 $\pm$ 4 % (weighted mean $\pm$ standard error), whereas using CNN resulted in classification accuracy of 58 $\pm$ 5 % across five subjects. For subject-by-subject alignment, using FG-W resulted in alignment accuracy of 55 $\pm$ 3 %, whereas using CNN resulted in classification accuracy of 45 $\pm$ 1 %. Where in both cases 25 % represents chance. We also showed that removal of motion artifacts from the fNIRS data plays an important role in improving alignment performance. Conclusions: Domain adaptation is potential for session-by-session and subject-by-subject alignment using fNIRS data.