 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman-Alignment and Calibration of Inference-Time Uncertainty in Large Language Models
Aug 11, 2025There has been much recent interest in evaluating large language models for uncertainty calibration to facilitate model control and modulate user trust. Inference time uncertainty, which may provide a real-time signal to the model or external control modules, is particularly important for applying these concepts to improve LLM-user experience in practice. While many of the existing papers consider model calibration, comparatively little work has sought to evaluate how closely model uncertainty aligns to human uncertainty. In this work, we evaluate a collection of inference-time uncertainty measures, using both established metrics and novel variations, to determine how closely they align with both human group-level uncertainty and traditional notions of model calibration. We find that numerous measures show evidence of strong alignment to human uncertainty, even despite the lack of alignment to human answer preference. For those successful metrics, we find moderate to strong evidence of model calibration in terms of both correctness correlation and distributional analysis.
Basic Category Usage in Vision Language Models
Mar 16, 2025The field of psychology has long recognized a basic level of categorization that humans use when labeling visual stimuli, a term coined by Rosch in 1976. This level of categorization has been found to be used most frequently, to have higher information density, and to aid in visual language tasks with priming in humans. Here, we investigate basic level categorization in two recently released, open-source vision-language models (VLMs). This paper demonstrates that Llama 3.2 Vision Instruct (11B) and Molmo 7B-D both prefer basic level categorization consistent with human behavior. Moreover, the models' preferences are consistent with nuanced human behaviors like the biological versus non-biological basic level effects and the well established expert basic level shift, further suggesting that VLMs acquire cognitive categorization behaviors from the human data on which they are trained.
Investigating Human-Aligned Large Language Model Uncertainty
Mar 16, 2025
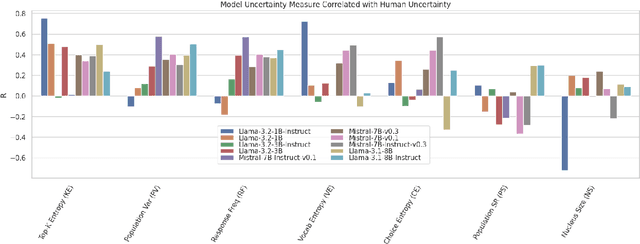
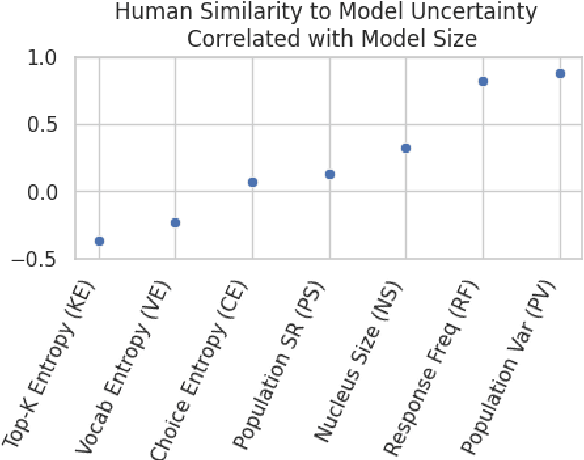
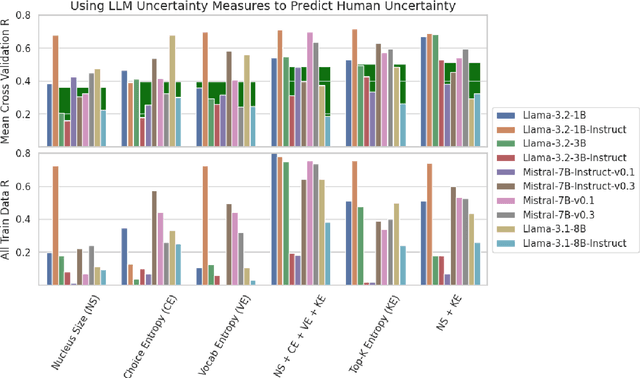
Recent work has sought to quantify large language model uncertainty to facilitate model control and modulate user trust. Previous works focus on measures of uncertainty that are theoretically grounded or reflect the average overt behavior of the model. In this work, we investigate a variety of uncertainty measures, in order to identify measures that correlate with human group-level uncertainty. We find that Bayesian measures and a variation on entropy measures, top-k entropy, tend to agree with human behavior as a function of model size. We find that some strong measures decrease in human-similarity with model size, but, by multiple linear regression, we find that combining multiple uncertainty measures provide comparable human-alignment with reduced size-dependency.
Reasoning Beyond Bias: A Study on Counterfactual Prompting and Chain of Thought Reasoning
Aug 16, 2024



Language models are known to absorb biases from their training data, leading to predictions driven by statistical regularities rather than semantic relevance. We investigate the impact of these biases on answer choice preferences in the Massive Multi-Task Language Understanding (MMLU) task. Our findings reveal that differences in learned regularities across answer options are predictive of model preferences and mirror human test-taking strategies. To address this issue, we introduce two novel methods: Counterfactual Prompting with Chain of Thought (CoT) and Counterfactual Prompting with Agnostically Primed CoT (APriCoT). We demonstrate that while Counterfactual Prompting with CoT alone is insufficient to mitigate bias, our novel Primed Counterfactual Prompting with CoT approach effectively reduces the influence of base-rate probabilities while improving overall accuracy. Our results suggest that mitigating bias requires a "System-2" like process and that CoT reasoning is susceptible to confirmation bias under some prompting methodologies. Our contributions offer practical solutions for developing more robust and fair language models.
Large Language Model Recall Uncertainty is Modulated by the Fan Effect
Jul 08, 2024This paper evaluates whether large language models (LLMs) exhibit cognitive fan effects, similar to those discovered by Anderson in humans, after being pre-trained on human textual data. We conduct two sets of in-context recall experiments designed to elicit fan effects. Consistent with human results, we find that LLM recall uncertainty, measured via token probability, is influenced by the fan effect. Our results show that removing uncertainty disrupts the observed effect. The experiments suggest the fan effect is consistent whether the fan value is induced in-context or in the pre-training data. Finally, these findings provide in-silico evidence that fan effects and typicality are expressions of the same phenomena.
The Base-Rate Effect on LLM Benchmark Performance: Disambiguating Test-Taking Strategies from Benchmark Performance
Jun 17, 2024Cloze testing is a common method for measuring the behavior of large language models on a number of benchmark tasks. Using the MMLU dataset, we show that the base-rate probability (BRP) differences across answer tokens are significant and affect task performance ie. guess A if uncertain. We find that counterfactual prompting does sufficiently mitigate the BRP effect. The BRP effect is found to have a similar effect to test taking strategies employed by humans leading to the conflation of task performance and test-taking ability. We propose the Nvr-X-MMLU task, a variation of MMLU, which helps to disambiguate test-taking ability from task performance and reports the latter.
Do Large Language Models Learn Human-Like Strategic Preferences?
Apr 11, 2024



We evaluate whether LLMs learn to make human-like preference judgements in strategic scenarios as compared with known empirical results. We show that Solar and Mistral exhibit stable value-based preference consistent with human in the prisoner's dilemma, including stake-size effect, and traveler's dilemma, including penalty-size effect. We establish a relationship between model size, value based preference, and superficiality. Finally, we find that models that tend to be less brittle were trained with sliding window attention. Additionally, we contribute a novel method for constructing preference relations from arbitrary LLMs and support for a hypothesis regarding human behavior in the traveler's dilemma.
Using Artificial Populations to Study Psychological Phenomena in Neural Models
Aug 15, 2023



The recent proliferation of research into transformer based natural language processing has led to a number of studies which attempt to detect the presence of human-like cognitive behavior in the models. We contend that, as is true of human psychology, the investigation of cognitive behavior in language models must be conducted in an appropriate population of an appropriate size for the results to be meaningful. We leverage work in uncertainty estimation in a novel approach to efficiently construct experimental populations. The resultant tool, PopulationLM, has been made open source. We provide theoretical grounding in the uncertainty estimation literature and motivation from current cognitive work regarding language models. We discuss the methodological lessons from other scientific communities and attempt to demonstrate their application to two artificial population studies. Through population based experimentation we find that language models exhibit behavior consistent with typicality effects among categories highly represented in training. However, we find that language models don't tend to exhibit structural priming effects. Generally, our results show that single models tend to over estimate the presence of cognitive behaviors in neural models.