 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement Learning from Meta-Evaluation: Aligning Language Models Without Ground-Truth Labels
Jan 29, 2026Most reinforcement learning (RL) methods for training large language models (LLMs) require ground-truth labels or task-specific verifiers, limiting scalability when correctness is ambiguous or expensive to obtain. We introduce Reinforcement Learning from Meta-Evaluation (RLME), which optimizes a generator using reward derived from an evaluator's answers to natural-language meta-questions (e.g., "Is the answer correct?" or "Is the reasoning logically consistent?"). RLME treats the evaluator's probability of a positive judgment as a reward and updates the generator via group-relative policy optimization, enabling learning without labels. Across a suite of experiments, we show that RLME achieves accuracy and sample efficiency comparable to label-based training, enables controllable trade-offs among multiple objectives, steers models toward reliable reasoning patterns rather than post-hoc rationalization, and generalizes to open-domain settings where ground-truth labels are unavailable, broadening the domains in which LLMs may be trained with RL.
Human-Alignment and Calibration of Inference-Time Uncertainty in Large Language Models
Aug 11, 2025There has been much recent interest in evaluating large language models for uncertainty calibration to facilitate model control and modulate user trust. Inference time uncertainty, which may provide a real-time signal to the model or external control modules, is particularly important for applying these concepts to improve LLM-user experience in practice. While many of the existing papers consider model calibration, comparatively little work has sought to evaluate how closely model uncertainty aligns to human uncertainty. In this work, we evaluate a collection of inference-time uncertainty measures, using both established metrics and novel variations, to determine how closely they align with both human group-level uncertainty and traditional notions of model calibration. We find that numerous measures show evidence of strong alignment to human uncertainty, even despite the lack of alignment to human answer preference. For those successful metrics, we find moderate to strong evidence of model calibration in terms of both correctness correlation and distributional analysis.
Investigating Human-Aligned Large Language Model Uncertainty
Mar 16, 2025
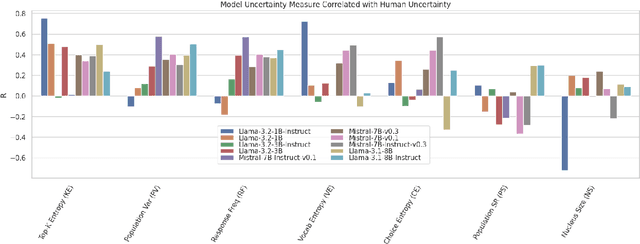
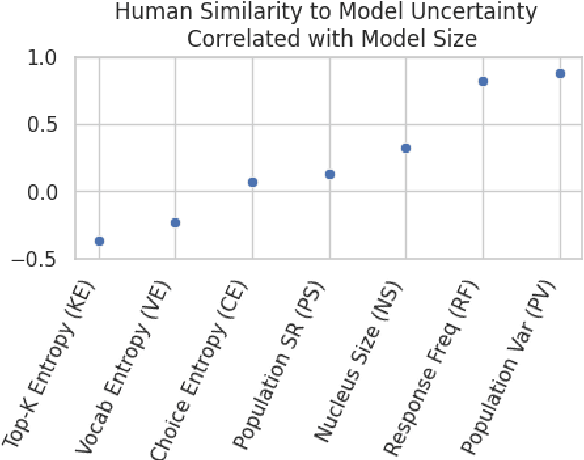
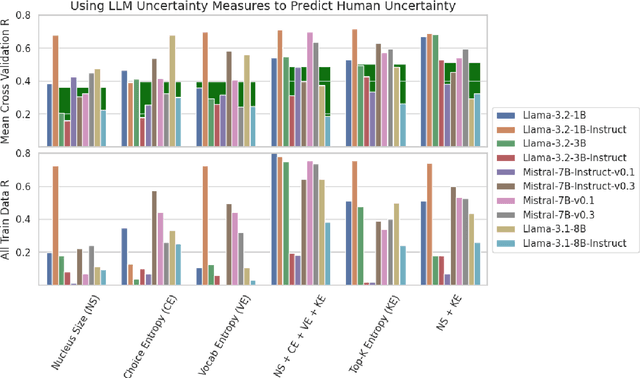
Recent work has sought to quantify large language model uncertainty to facilitate model control and modulate user trust. Previous works focus on measures of uncertainty that are theoretically grounded or reflect the average overt behavior of the model. In this work, we investigate a variety of uncertainty measures, in order to identify measures that correlate with human group-level uncertainty. We find that Bayesian measures and a variation on entropy measures, top-k entropy, tend to agree with human behavior as a function of model size. We find that some strong measures decrease in human-similarity with model size, but, by multiple linear regression, we find that combining multiple uncertainty measures provide comparable human-alignment with reduced size-dependency.
Basic Category Usage in Vision Language Models
Mar 16, 2025The field of psychology has long recognized a basic level of categorization that humans use when labeling visual stimuli, a term coined by Rosch in 1976. This level of categorization has been found to be used most frequently, to have higher information density, and to aid in visual language tasks with priming in humans. Here, we investigate basic level categorization in two recently released, open-source vision-language models (VLMs). This paper demonstrates that Llama 3.2 Vision Instruct (11B) and Molmo 7B-D both prefer basic level categorization consistent with human behavior. Moreover, the models' preferences are consistent with nuanced human behaviors like the biological versus non-biological basic level effects and the well established expert basic level shift, further suggesting that VLMs acquire cognitive categorization behaviors from the human data on which they are trained.
RL + Transformer = A General-Purpose Problem Solver
Jan 24, 2025



What if artificial intelligence could not only solve problems for which it was trained but also learn to teach itself to solve new problems (i.e., meta-learn)? In this study, we demonstrate that a pre-trained transformer fine-tuned with reinforcement learning over multiple episodes develops the ability to solve problems that it has never encountered before - an emergent ability called In-Context Reinforcement Learning (ICRL). This powerful meta-learner not only excels in solving unseen in-distribution environments with remarkable sample efficiency, but also shows strong performance in out-of-distribution environments. In addition, we show that it exhibits robustness to the quality of its training data, seamlessly stitches together behaviors from its context, and adapts to non-stationary environments. These behaviors demonstrate that an RL-trained transformer can iteratively improve upon its own solutions, making it an excellent general-purpose problem solver.
Investigating Expert-in-the-Loop LLM Discourse Patterns for Ancient Intertextual Analysis
Sep 03, 2024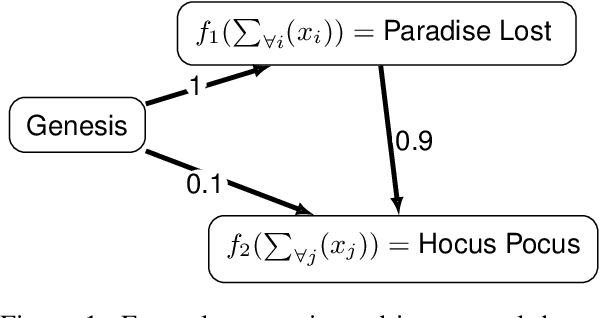


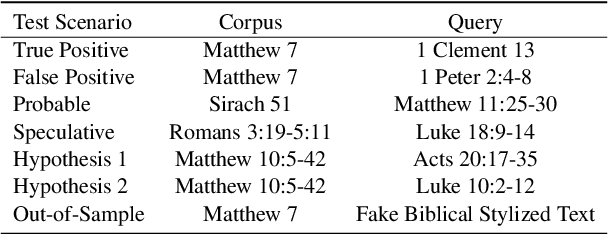
This study explores the potential of large language models (LLMs) for identifying and examining intertextual relationships within biblical, Koine Greek texts. By evaluating the performance of LLMs on various intertextuality scenarios the study demonstrates that these models can detect direct quotations, allusions, and echoes between texts. The LLM's ability to generate novel intertextual observations and connections highlights its potential to uncover new insights. However, the model also struggles with long query passages and the inclusion of false intertextual dependences, emphasizing the importance of expert evaluation. The expert-in-the-loop methodology presented offers a scalable approach for intertextual research into the complex web of intertextuality within and beyond the biblical corpus.
Reasoning Beyond Bias: A Study on Counterfactual Prompting and Chain of Thought Reasoning
Aug 16, 2024



Language models are known to absorb biases from their training data, leading to predictions driven by statistical regularities rather than semantic relevance. We investigate the impact of these biases on answer choice preferences in the Massive Multi-Task Language Understanding (MMLU) task. Our findings reveal that differences in learned regularities across answer options are predictive of model preferences and mirror human test-taking strategies. To address this issue, we introduce two novel methods: Counterfactual Prompting with Chain of Thought (CoT) and Counterfactual Prompting with Agnostically Primed CoT (APriCoT). We demonstrate that while Counterfactual Prompting with CoT alone is insufficient to mitigate bias, our novel Primed Counterfactual Prompting with CoT approach effectively reduces the influence of base-rate probabilities while improving overall accuracy. Our results suggest that mitigating bias requires a "System-2" like process and that CoT reasoning is susceptible to confirmation bias under some prompting methodologies. Our contributions offer practical solutions for developing more robust and fair language models.
Supporting the Digital Autonomy of Elders Through LLM Assistance
Jul 22, 2024The internet offers tremendous access to services, social connections, and needed products. However, to those without sufficient experience, engaging with businesses and friends across the internet can be daunting due to the ever present danger of scammers and thieves, to say nothing of the myriad of potential computer viruses. Like a forest rich with both edible and poisonous plants, those familiar with the norms inhabit it safely with ease while newcomers need a guide. However, reliance on a human digital guide can be taxing and often impractical. We propose and pilot a simple but unexplored idea: could an LLM provide the necessary support to help the elderly who are separated by the digital divide safely achieve digital autonomy?
Large Language Model Recall Uncertainty is Modulated by the Fan Effect
Jul 08, 2024This paper evaluates whether large language models (LLMs) exhibit cognitive fan effects, similar to those discovered by Anderson in humans, after being pre-trained on human textual data. We conduct two sets of in-context recall experiments designed to elicit fan effects. Consistent with human results, we find that LLM recall uncertainty, measured via token probability, is influenced by the fan effect. Our results show that removing uncertainty disrupts the observed effect. The experiments suggest the fan effect is consistent whether the fan value is induced in-context or in the pre-training data. Finally, these findings provide in-silico evidence that fan effects and typicality are expressions of the same phenomena.
The Base-Rate Effect on LLM Benchmark Performance: Disambiguating Test-Taking Strategies from Benchmark Performance
Jun 17, 2024Cloze testing is a common method for measuring the behavior of large language models on a number of benchmark tasks. Using the MMLU dataset, we show that the base-rate probability (BRP) differences across answer tokens are significant and affect task performance ie. guess A if uncertain. We find that counterfactual prompting does sufficiently mitigate the BRP effect. The BRP effect is found to have a similar effect to test taking strategies employed by humans leading to the conflation of task performance and test-taking ability. We propose the Nvr-X-MMLU task, a variation of MMLU, which helps to disambiguate test-taking ability from task performance and reports the latter.