 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributional Reinforcement Learning with Maximum Mean Discrepancy
Jul 24, 2020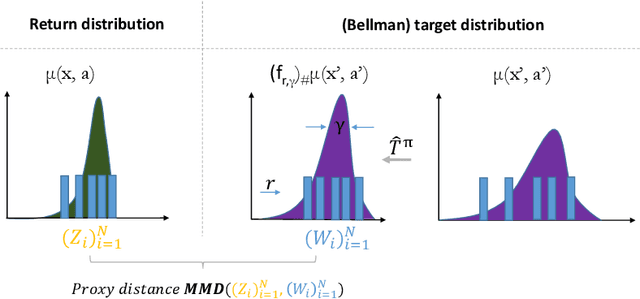



Distributional reinforcement learning (RL) has achieved state-of-the-art performance in Atari games by recasting the traditional RL into a distribution estimation problem, explicitly estimating the probability distribution instead of the expectation of a total return. The bottleneck in distributional RL lies in the estimation of this distribution where one must resort to an approximate representation of the return distributions which are infinite-dimensional. Most existing methods focus on learning a set of predefined statistic functionals of the return distributions requiring involved projections to maintain the order statistics. We take a different perspective using deterministic sampling wherein we approximate the return distributions with a set of deterministic particles that are not attached to any predefined statistic functional, allowing us to freely approximate the return distributions. The learning is then interpreted as evolution of these particles so that a distance between the return distribution and its target distribution is minimized. This learning aim is realized via maximum mean discrepancy (MMD) distance which in turn leads to a simpler loss amenable to backpropagation. Experiments on the suite of Atari 2600 games show that our algorithm outperforms the standard distributional RL baselines and sets a new record in the Atari games for non-distributed agents.
Distributionally Robust Bayesian Quadrature Optimization
Jan 19, 2020
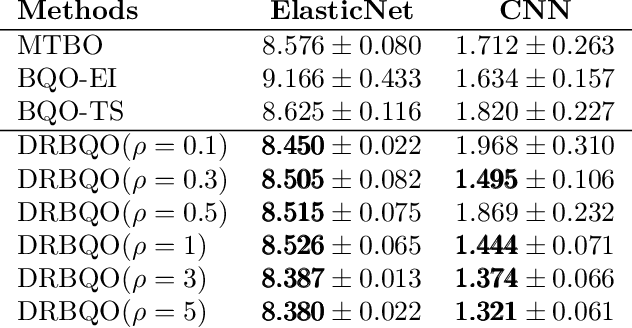
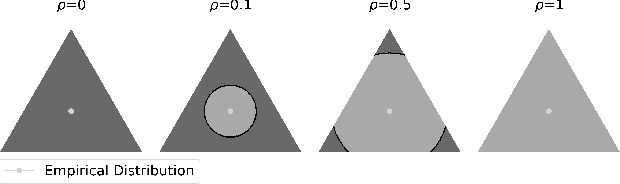

Bayesian quadrature optimization (BQO) maximizes the expectation of an expensive black-box integrand taken over a known probability distribution. In this work, we study BQO under distributional uncertainty in which the underlying probability distribution is unknown except for a limited set of its i.i.d. samples. A standard BQO approach maximizes the Monte Carlo estimate of the true expected objective given the fixed sample set. Though Monte Carlo estimate is unbiased, it has high variance given a small set of samples; thus can result in a spurious objective function. We adopt the distributionally robust optimization perspective to this problem by maximizing the expected objective under the most adversarial distribution. In particular, we propose a novel posterior sampling based algorithm, namely distributionally robust BQO (DRBQO) for this purpose. We demonstrate the empirical effectiveness of our proposed framework in synthetic and real-world problems, and characterize its theoretical convergence via Bayesian regret.
* AISTATS2020