 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributional Reinforcement Learning with Maximum Mean Discrepancy
Paper and Code
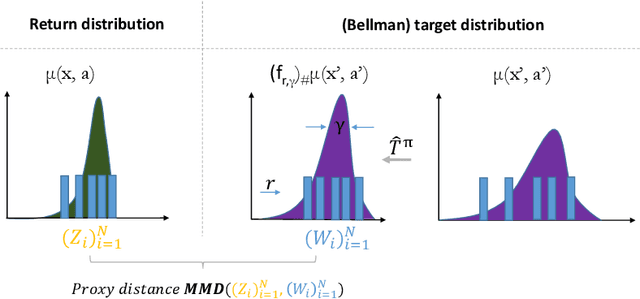



Distributional reinforcement learning (RL) has achieved state-of-the-art performance in Atari games by recasting the traditional RL into a distribution estimation problem, explicitly estimating the probability distribution instead of the expectation of a total return. The bottleneck in distributional RL lies in the estimation of this distribution where one must resort to an approximate representation of the return distributions which are infinite-dimensional. Most existing methods focus on learning a set of predefined statistic functionals of the return distributions requiring involved projections to maintain the order statistics. We take a different perspective using deterministic sampling wherein we approximate the return distributions with a set of deterministic particles that are not attached to any predefined statistic functional, allowing us to freely approximate the return distributions. The learning is then interpreted as evolution of these particles so that a distance between the return distribution and its target distribution is minimized. This learning aim is realized via maximum mean discrepancy (MMD) distance which in turn leads to a simpler loss amenable to backpropagation. Experiments on the suite of Atari 2600 games show that our algorithm outperforms the standard distributional RL baselines and sets a new record in the Atari games for non-distributed agents.