 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Language Models Represent the Past without Anachronism?
Apr 28, 2025

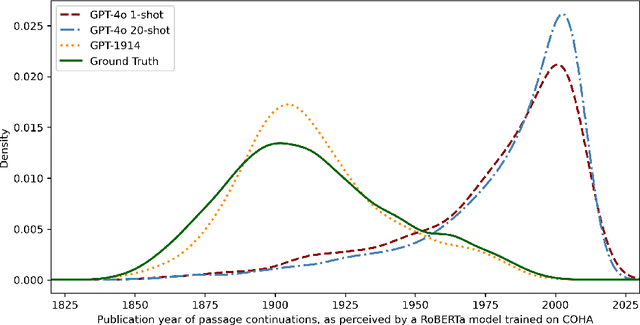
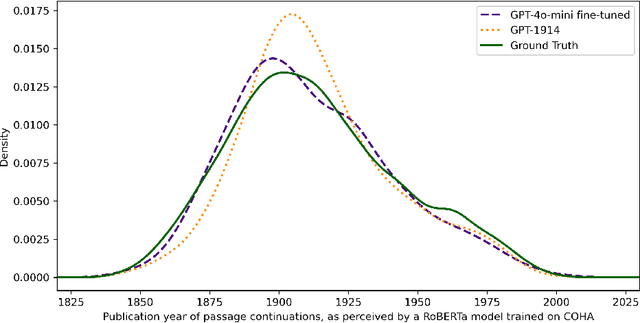
Before researchers can use language models to simulate the past, they need to understand the risk of anachronism. We find that prompting a contemporary model with examples of period prose does not produce output consistent with period style. Fine-tuning produces results that are stylistically convincing enough to fool an automated judge, but human evaluators can still distinguish fine-tuned model outputs from authentic historical text. We tentatively conclude that pretraining on period prose may be required in order to reliably simulate historical perspectives for social research.
Locating the Leading Edge of Cultural Change
Nov 22, 2024

Measures of textual similarity and divergence are increasingly used to study cultural change. But which measures align, in practice, with social evidence about change? We apply three different representations of text (topic models, document embeddings, and word-level perplexity) to three different corpora (literary studies, economics, and fiction). In every case, works by highly-cited authors and younger authors are textually ahead of the curve. We don't find clear evidence that one representation of text is to be preferred over the others. But alignment with social evidence is strongest when texts are represented through the top quartile of passages, suggesting that a text's impact may depend more on its most forward-looking moments than on sustaining a high level of innovation throughout.
The Historical Significance of Textual Distances
Jun 30, 2018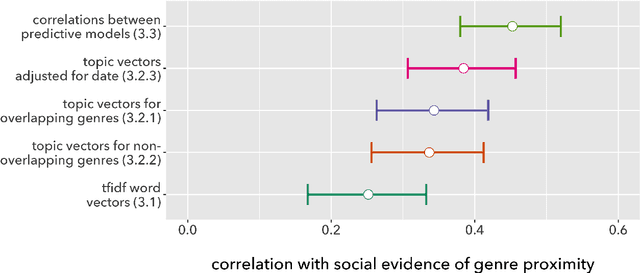
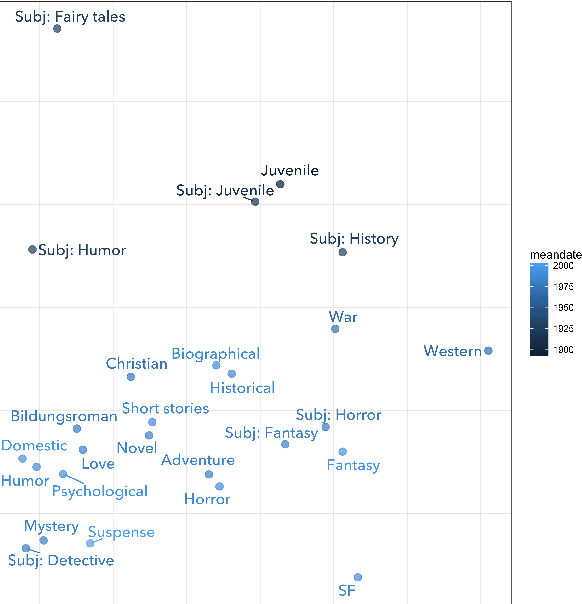
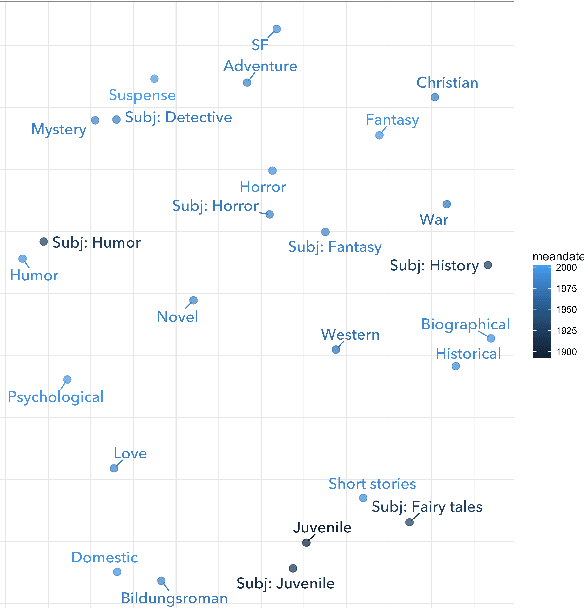

Measuring similarity is a basic task in information retrieval, and now often a building-block for more complex arguments about cultural change. But do measures of textual similarity and distance really correspond to evidence about cultural proximity and differentiation? To explore that question empirically, this paper compares textual and social measures of the similarities between genres of English-language fiction. Existing measures of textual similarity (cosine similarity on tf-idf vectors or topic vectors) are also compared to new strategies that use supervised learning to anchor textual measurement in a social context.
Mapping Mutable Genres in Structurally Complex Volumes
Sep 18, 2013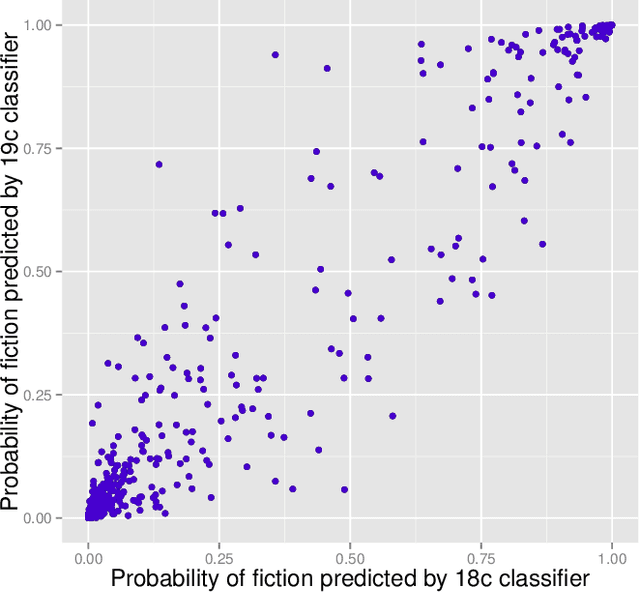
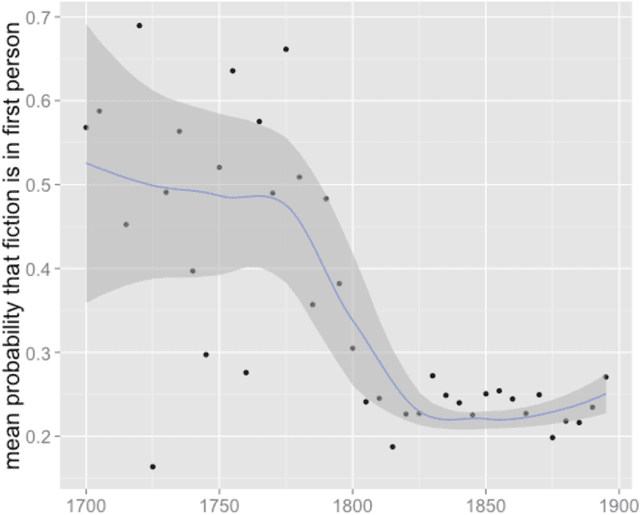
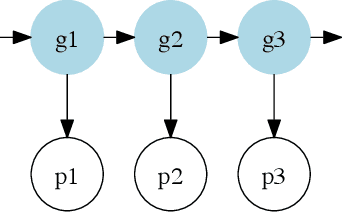
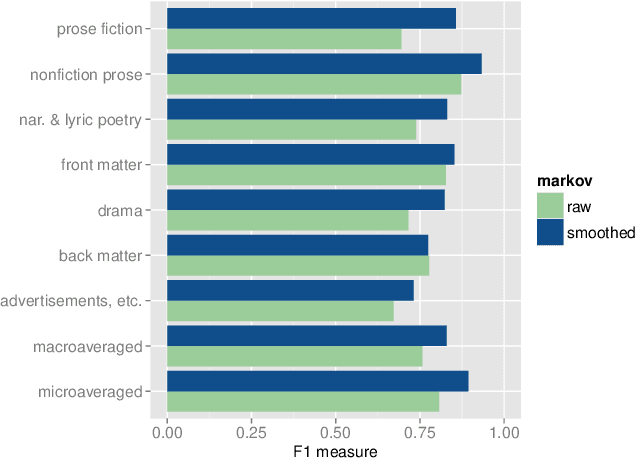
To mine large digital libraries in humanistically meaningful ways, scholars need to divide them by genre. This is a task that classification algorithms are well suited to assist, but they need adjustment to address the specific challenges of this domain. Digital libraries pose two problems of scale not usually found in the article datasets used to test these algorithms. 1) Because libraries span several centuries, the genres being identified may change gradually across the time axis. 2) Because volumes are much longer than articles, they tend to be internally heterogeneous, and the classification task needs to begin with segmentation. We describe a multi-layered solution that trains hidden Markov models to segment volumes, and uses ensembles of overlapping classifiers to address historical change. We test this approach on a collection of 469,200 volumes drawn from HathiTrust Digital Library. To demonstrate the humanistic value of these methods, we extract 32,209 volumes of fiction from the digital library, and trace the changing proportions of first- and third-person narration in the corpus. We note that narrative points of view seem to have strong associations with particular themes and genres.