 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMapping Mutable Genres in Structurally Complex Volumes
Sep 18, 2013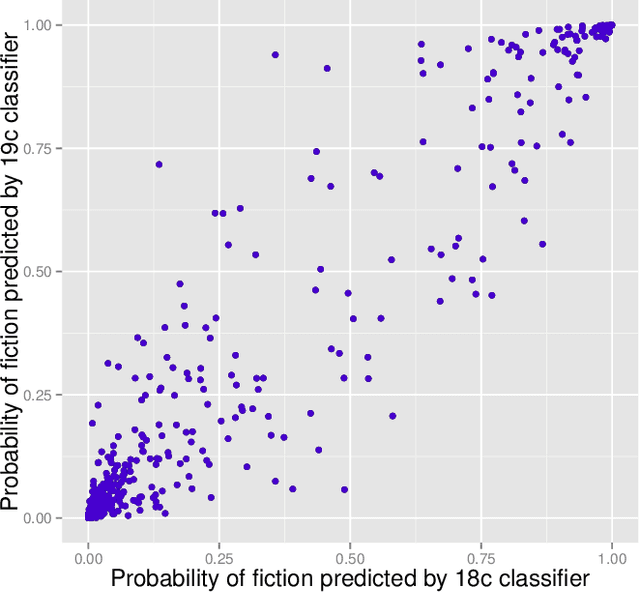
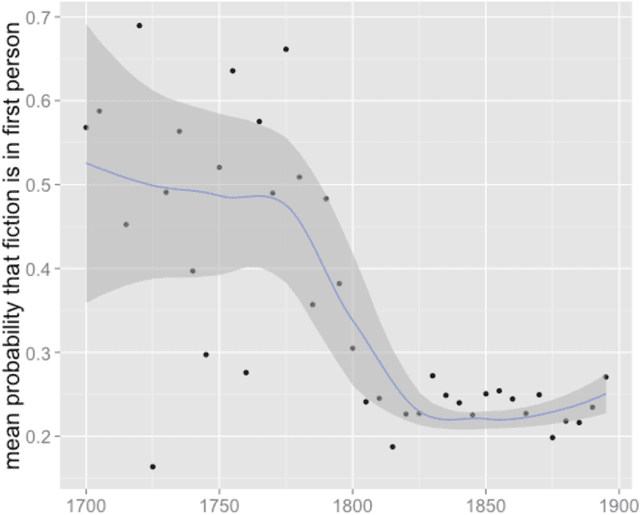
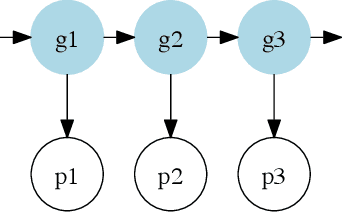
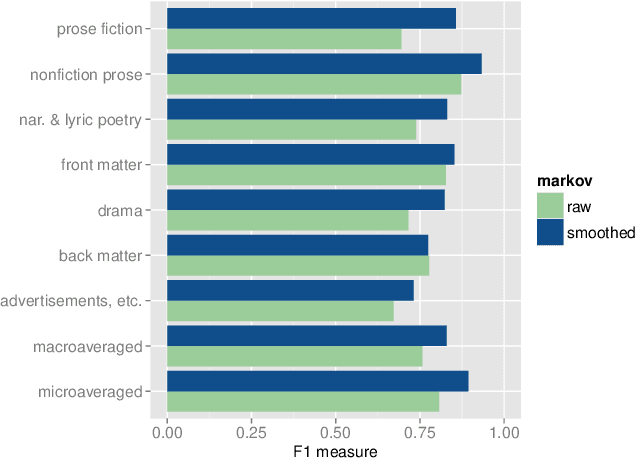
To mine large digital libraries in humanistically meaningful ways, scholars need to divide them by genre. This is a task that classification algorithms are well suited to assist, but they need adjustment to address the specific challenges of this domain. Digital libraries pose two problems of scale not usually found in the article datasets used to test these algorithms. 1) Because libraries span several centuries, the genres being identified may change gradually across the time axis. 2) Because volumes are much longer than articles, they tend to be internally heterogeneous, and the classification task needs to begin with segmentation. We describe a multi-layered solution that trains hidden Markov models to segment volumes, and uses ensembles of overlapping classifiers to address historical change. We test this approach on a collection of 469,200 volumes drawn from HathiTrust Digital Library. To demonstrate the humanistic value of these methods, we extract 32,209 volumes of fiction from the digital library, and trace the changing proportions of first- and third-person narration in the corpus. We note that narrative points of view seem to have strong associations with particular themes and genres.